En este tema
Ajustes condicionales
Los ajustes condicionales son las estimaciones de los valores de respuesta media con la configuración de los factores aleatorios especificada en el conjunto de datos. Los ajustes condicionales se calculan a partir de las ecuaciones ajustadas condicionales.
EE ajuste
El error estándar del ajuste (EE ajuste) estima la variación en la respuesta media estimada para la configuración especificada de las variables. El cálculo del intervalo de confianza para la respuesta media utiliza el error estándar del ajuste. Los errores estándar son siempre no negativos.
GL para la media condicional
Los grados de libertad (GL) representan la cantidad de información en los datos para estimar el intervalo de confianza para la respuesta media.
Interpretación
Utilice los GL para comparar la cantidad de información que está disponible acerca de las diferentes medias condicionales. Por lo general, más grados de libertad hacen que el intervalo de confianza para la media sea más estrecho que un intervalo con menos grados de libertad. Puesto que los errores estándar para las medias de diferentes observaciones son diferentes, el intervalo de confianza para una media con más grados de libertad no tiene que ser más estrecho que un intervalo de confianza para una media con menos grados de libertad.
Intervalo de confianza para la media condicional (IC de 95%)
Estos intervalos de confianza (IC) son rangos de valores que es probable que contengan las respuestas medias condicionales correspondientes.
Puesto que las muestras son aleatorias, es poco probable que dos muestras de una población produzcan intervalos de confianza idénticos. Sin embargo, si se toman muchas muestras, un determinado porcentaje de los intervalos de confianza resultantes incluirá el parámetro de población desconocido. El porcentaje de estos intervalos de confianza que contiene el parámetro es el nivel de confianza del intervalo.
El intervalo de confianza consta de las dos partes siguientes:
Interpretación
Utilice los intervalos de confianza para evaluar si las respuestas medias condicionales son estadísticamente mayores que, iguales a o menores que un valor específico. También puede utilizar los intervalos de confianza para determinar un rango de valores para las respuestas medias condicionales desconocidas correspondientes.
Resid condicional
Un residuo (ei) es la diferencia entre un valor observado (y) y el valor ajustado condicional correspondiente, (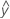 ).
).
Interpretación
Grafique los residuos para determinar si el modelo es adecuado y cumple con los supuestos del modelo de efectos mixtos. Examinar los residuos puede ofrecer información útil acerca de qué tan bien se ajusta el modelo a los datos. En general, los residuos deberían estar distribuidos aleatoriamente, sin patrones obvios ni valores poco comunes. Si Minitab determina que los datos incluyen observaciones poco comunes, identifica esas observaciones en la tabla Ajustes condicionales y diagnósticos para observaciones poco comunes incluida en la salida. Las observaciones que Minitab etiqueta como poco comunes no siguen adecuadamente la ecuación condicional propuesta. Sin embargo, se espera que haya algunas observaciones poco comunes. Por ejemplo, con base en los criterios para los residuos grandes, se esperaría que aproximadamente el 5% de las observaciones sean marcadas como observaciones con un residuo grande.
Resid Est
El residuo condicional estandarizado es igual al valor de un residuo (ei) dividido entre una estimación de su desviación estándar.
Interpretación
Utilice los residuos condicionales estandarizados como ayuda para detectar valores atípicos. Los residuos condicionales estandarizados mayores que 2 y menores que −2 por lo general se consideran grandes. La tabla Ajustes condicionales y diagnósticos para observaciones poco comunes identifica estas observaciones con una 'R'. Las observaciones que Minitab etiqueta no siguen adecuadamente la ecuación ajustada condicional propuesta. Sin embargo, se espera que haya algunas observaciones poco comunes. Por ejemplo, con base en los criterios para los residuos condicionales estandarizados grandes, se esperaría que aproximadamente el 5% de las observaciones se marquen como observaciones con un residuo estandarizado grande.
Los residuos condicionales estandarizados son útiles porque los residuos condicionales sin procesar podrían no ser buenos indicadores de valores atípicos. La varianza de cada residuo condicional sin procesar puede diferir según los valores de X asociados al residuo. Esta variación desigual hace que sea difícil evaluar las magnitudes de los residuos condicionales sin procesar. La estandarización de los residuos condicionales resuelve este problema al convertir las diferentes varianzas a una escala común.