En este tema
Suma de los cuadrados (SC)
En términos de matriz, estas son las fórmulas para las diferentes sumas de cuadrados:



Minitab desglosa el componente SC Regresión o SC Tratamientos en la cantidad de variación explicada por cada término utilizando tanto la suma de cuadrados secuenciales como la suma de cuadrados ajustados.
Notación
| Término | Description |
|---|---|
| b | vector de coeficientes |
| X | matriz de diseño |
| Y | vector de valores de respuesta |
| n | número de observaciones |
| J | n entre n matriz de 1s |
Suma secuencial de los cuadrados
Minitab desglosa el componente SC Regresión o Tratamientos de la varianza en las sumas secuenciales de los cuadrados para cada factor. Las sumas secuenciales de los cuadrados dependen del orden en que los factores o predictores se ingresan en el modelo. Las sumas secuenciales de cuadrados es la porción única de la SC Regresión explicada por un factor, dados los factores ingresados previamente.
Por ejemplo, si se tiene un modelo con tres factores o predictores, X1, X2 y X3, la suma secuencial de cuadrados para X2 muestra qué proporción de la variación restante puede explicar X2, dado que X1 ya se encuentra en el modelo. Para obtener una secuencia diferente de factores, repita el análisis e ingrese los factores en un orden diferente.
Suma ajustada de los cuadrados
Las sumas ajustadas de los cuadrados no dependen del orden en que los términos se ingresan en el modelo. La suma ajustada de los cuadrados es la cantidad de variación explicada por un término, dados todos los otros términos estén incluidos en el modelo, independientemente del orden en que se ingresen los términos en el modelo.
Por ejemplo, si usted tiene un modelo con tres factores, X1, X2 y X3, la suma ajustada de los cuadrados para X2 muestra la proporción de la variación restante que es explicada por el término para X2, dado que los términos para X1 y X3 también se encuentren en el modelo.
Los cálculos de las sumas ajustadas de los cuadrados para tres factores son:
- SSR(X3 | X1, X2) = SSE (X1, X2) - SSE (X1, X2, X3) o
- SSR(X3 | X1, X2) = SSR (X1, X2, X3) - SSR (X1, X2)
donde SSR(X3 | X1, X2) es la suma ajustada de los cuadrados para X3, dado que X1 y X2 estén en el modelo.
- SSR(X2, X3 | X1) = SSE (X1) - SSE (X1, X2, X3) o
- SSR(X2, X3 | X1) = SSR (X1, X2, X3) - SSR (X1)
donde SSR(X2, X3 | X1) es la suma ajustada de los cuadrados para X2 y X3, dado que X1 esté en el modelo.
Usted puede ampliar estas fórmulas si tienen más de 3 factores en el modelo1.
- J. Neter, W. Wasserman y M.H. Kutner (1985). Applied Linear Statistical Models, Second Edition. Irwin, Inc.
Grados de libertad (GL)
Los grados de libertad para cada componente del modelo son:
| Fuentes de variación | GL |
|---|---|
| Factor | ki – 1 |
| Covariables e interacciones entre covariables | 1 |
| Interacciones que implican factores | 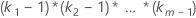 |
| Regresión | p |
| Error | n – p – 1 |
| Total | n – 1 |
- Los datos contienen múltiples observaciones con los mismos valores predictores.
- Los datos contienen los puntos correctos para estimar los términos adicionales que no están en el modelo.
Notación
| Término | Description |
|---|---|
| ki | número de niveles en el iésimo factor |
| m | número de factores |
| n | número de observaciones |
| p | número de coeficientes en el modelo, sin contar la constante |
CM ajust – Regresión
La fórmula del cuadrado medio (CM) de la regresión es:
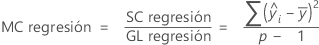
Notación
| Término | Description |
|---|---|
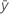 | respuesta media |
 | iésima respuesta ajustada |
| p | número de términos en el modelo |
CM ajustado – Error
El cuadrado medio del error (también abreviado como CM error o MSE y conocido como s2) es la varianza alrededor de la línea de regresión ajustada. La fórmula es:
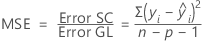
Notación
| Término | Description |
|---|---|
| yi | iésimo valor de respuesta observado |
 | iésima respuesta ajustada |
| n | número de observaciones |
| p | número de coeficientes en el modelo, sin contar la constante |
F
Si todos los factores en el modelo son fijos, entonces el cálculo del estadístico F depende de lo que se trata la prueba de hipótesis, como sigue:
- F(Término)
-

- F(Falta de ajuste)
-

Si hay factores aleatorios en el modelo, F se construye utilizando la información del cuadrado medio esperado para cada término. Para obtener más información, consulte a Neter et al.1.
Notación
| Término | Description |
|---|---|
| Término de CM Ajust. | Una medida de la cantidad de variación que explica un término después de representar los demás términos en el modelo. |
| Error CM | Una medida de la variación que el modelo no explica. |
| Falta de ajuste de CM | Una medida de la variación en la respuesta que pudiera modelarse agregando más términos al modelo. |
| Error puro CM | Una medida de la variación en los datos de respuesta replicada. |
- J. Neter, W. Wasserman y M.H. Kutner (1985). Applied Linear Statistical Models, Second Edition. Irwin, Inc.
Valor p – Tabla Análisis de varianza
El valor p es una probabilidad que se calcula a partir de una distribución F con los grados de libertad (GL) que se indican a continuación:
- GL del numerador
- suma de los grados de libertad para el término o los términos en la prueba
- GL del denominador
- grados de libertad para el error
Fórmula
1 − P(F ≤ fj)
Notación
| Término | Description |
|---|---|
| P(F ≤ f) | función de distribución acumulada para la distribución F |
| f | estadístico F para la prueba |
Prueba de falta de ajuste de error puro
- La suma de las desviaciones al cuadrado de la respuesta con respecto a la media en cada conjunto de réplicas y las suma juntas para crear la suma de los cuadrados del error puro (SC EP).
- El cuadrado medio del error puro


donde n = número de observaciones y m = número de distintas combinaciones del nivel x
- La suma de los cuadrados de la falta de ajuste

- El cuadrado medio de la falta de ajuste

- Los estadísticos de prueba

Los valores F y los valores p pequeños sugieren que el modelo es inadecuado.
Valor p – Prueba de falta de ajuste
- GL del numerador
- grados de libertad para la falta de ajuste
- GL del denominador
- grados de libertad para el error puro
Fórmula
1 − P(F ≤ fj)
Notación
| Término | Description |
|---|---|
| P(F ≤ fj) | función de distribución acumulada para la distribución F |
| fj | estadístico F para la prueba |