En este tema
Ajuste
Los valores ajustados también se denominan ajustes o 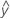 . Los valores ajustados son estimados de puntos de la respuesta media para los valores dados de los predictores. Los valores de los predictores también se denominan valores x.
. Los valores ajustados son estimados de puntos de la respuesta media para los valores dados de los predictores. Los valores de los predictores también se denominan valores x.
Interpretación
Los valores ajustados se calculan ingresando los valores específicos de X para cada observación del conjunto de datos en la ecuación del modelo.
Por ejemplo, si la ecuación es y = 5 + 10x, el valor ajustado para el valor x, 2, es 25 (25 = 5 + 10(2)).
Las observaciones con valores ajustados que sean muy diferentes del valor observado pueden ser poco comunes. Las observaciones con valores predictores poco comunes podrían ser influyentes. Si Minitab determina que los datos incluyen valores poco comunes o influyentes, la salida incluye la tabla Ajustes y diagnósticos para observaciones poco comunes, que identifica estas observaciones. Las observaciones poco comunes que Minitab etiqueta no siguen adecuadamente la ecuación de regresión propuesta. Sin embargo, se espera que haya algunas observaciones poco comunes. Por ejemplo, con base en los criterios para los residuos estandarizados grandes, se esperaría que aproximadamente el 5% de las observaciones se marque como observaciones que tienen un residuo estandarizado grande. Para obtener más información sobre valores poco comunes, vaya a Observaciones poco comunes.
EE de ajuste
El error estándar del ajuste (EE ajuste) estima la variación en la respuesta media estimada para la configuración especificada de las variables. El cálculo del intervalo de confianza para la respuesta media utiliza el error estándar del ajuste. Los errores estándar son siempre no negativos. El análisis calcula los errores estándar para los modelos desde el Estadísticas menú y los modelos desde Regresión lineal y Regresión logística binaria desde el Módulo de análisis predictivo archivo .
Interpretación
Utilice el error estándar del ajuste para medir la precisión de la estimación de la respuesta media. Cuanto menor sea el error estándar, más precisa será la respuesta media pronosticada. Por ejemplo, un analista desarrolla un modelo para pronosticar el tiempo de entrega. Para un conjunto de valores de configuración de las variables, el modelo predice un tiempo medio de entrega de 3.80 días. El error estándar del ajuste para esta configuración es 0.08 días. Para un segundo conjunto de valores de configuración de las variables, el modelo produce el mismo tiempo medio de entrega con un error estándar del ajuste de 0.02 días. El analista puede estar más seguro de que el tiempo medio de entrega del segundo conjunto de valores de configuración de las variables es cercano a 3.80 días.
Con el valor ajustado, usted puede utilizar el error estándar del ajuste para crear un intervalo de confianza para la respuesta media. Por ejemplo, dependiendo del número de grados de libertad, un intervalo de confianza de 95% se extiende aproximadamente dos errores estándar por encima y por debajo de la media pronosticada. Para los tiempos de entrega, el intervalo de confianza de 95% de la media pronosticada de 3.80 días cuando el error estándar es 0.08 es (3.64, 3.96) días. Puede estar 95% seguro de que la media de la población se encuentra dentro de este rango. Cuando el error estándar es 0.02, el intervalo de confianza de 95% es (3.76, 3.84) días. El intervalo de confianza del segundo conjunto de valores de configuración de las variables es más estrecho porque el error estándar es menor.
Intervalo de confianza para ajuste (IC de 95 %)
Estos intervalos de confianza (IC) son rangos de valores que probablemente contienen la respuesta media para la población que tiene los valores observados de los predictores o factores en el modelo.
Puesto que las muestras son aleatorias, es poco probable que dos muestras de una población produzcan intervalos de confianza idénticos. Sin embargo, si se toman muchas muestras, un determinado porcentaje de los intervalos de confianza resultantes incluirá el parámetro de población desconocido. El porcentaje de estos intervalos de confianza que contiene el parámetro es el nivel de confianza del intervalo.
El intervalo de confianza consta de las dos partes siguientes:
Interpretación
Utilice el intervalo de confianza para evaluar la estimación del valor ajustado para los valores observados de las variables.
Por ejemplo, con un nivel de confianza de 95 %, se puede estar un 95 % seguro de que el intervalo de confianza contiene la media de población para los valores especificados de los factores o variables predictoras en el modelo. El intervalo de confianza ayuda a evaluar la significancia práctica de los resultados. Utilice el conocimiento especializado para determinar si el intervalo de confianza incluye valores que tienen significancia práctica para su situación. Un intervalo de confianza amplio indica que se puede estar menos seguro de la media de los valores futuros. Si el intervalo es demasiado amplio para ser útil, considere aumentar el tamaño de la muestra.
Residuos
Un residuo (ei) es la diferencia entre un valor observado (y) y el valor ajustado correspondiente, (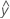 ), el cual es el valor pronosticado por el modelo.
), el cual es el valor pronosticado por el modelo.
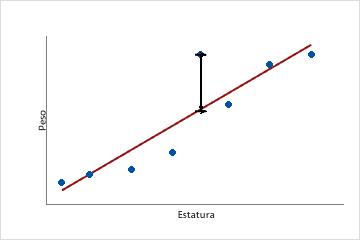
Esta gráfica de dispersión muestra el peso vs. la estatura para una muestra de adultos hombres. La línea de regresión ajustada representa la relación entre estatura y peso. Si la estatura equivale a 6 pies, el valor ajustado para el peso es de 190 libras. Si el peso real es de 200 libras, el residuo es de 10.
Interpretación
Método que se utiliza cuando se viola el supuesto de cuadrados mínimos de la varianza constante en los residuos (heteroscedasticidad). Graficar los residuos para determinar si el modelo es adecuado y cumple con los supuestos de regresión. Examinar los residuos puede ofrecer información útil de hasta qué punto el modelo se ajusta a los datos. En general, los residuos deben ser distribuidos aleatoriamente sin patrones evidentes y sin valores poco comunes. Si Minitab determina que los datos incluyen observaciones poco comunes, identifica esas observaciones en la tabla Ajustes y diagnósticos para observaciones poco comunes en el resultado. Las observaciones que Minitab etiqueta como poco comunes no siguen adecuadamente la ecuación de regresión propuesta. Sin embargo, se espera que se tengan algunas observaciones poco comunes. Por ejemplo, con base en los criterios para los residuos grandes, se esperaría que aproximadamente el 5 % de las observaciones sean etiquetadas como con un residuo grande. Para obtener más información sobre valores poco comunes, vaya a Observaciones poco comunes.
Residuo estandarizado
El residuo estandarizado es igual al valor de un residuo (ei) dividido entre una estimación de su desviación estándar.
Interpretación
Utilice los residuos estandarizados como ayuda para detectar valores atípicos. Los residuos estandarizados mayores que 2 y menores que −2 por lo general se consideran grandes. La tabla Ajustes y diagnósticos para observaciones inusuales identifica estas observaciones con una 'R'. Las observaciones que Minitab etiqueta no siguen adecuadamente la ecuación de regresión propuesta. Sin embargo, se espera que se tengan algunas observaciones poco comunes. Por ejemplo, con base en los criterios para los residuos estandarizados grandes, se esperaría que aproximadamente el 5% de las observaciones se etiquete como con un residuo estandarizado grande. Para obtener más información, vaya a Observaciones poco comunes.
Los residuos estandarizados son útiles porque los residuos sin procesar podrían no ser buenos indicadores de valores atípicos. La varianza de cada residuo sin procesar puede diferir por los valores x asociados con la misma. Esta variación desigual hace que sea dificil evaluar las magnitudes de los residuos sin procesar. Al estandarizar los residuos se resuelve el problema conviertiendo las diferentes varianzas en una escala común.
Residuos elim.
Cada residuo studentizado eliminado se calcula con una fórmula que equivale a eliminar sistemáticamente cada una de las observaciones del conjunto de datos, estimar la ecuación de regresión y determinar qué tan bien el modelo predice la observación eliminada. Cada residuo studentizado eliminado también se estandariza al dividir el residuo eliminado de una observación entre una estimación de su desviación estándar. La observación se omite para determinar cómo se comporta el modelo sin esta observación. Si una observación tiene un residuo eliminado studentizado grande (si su valor absoluto es mayor que 2), podría tratarse de un valor atípico en los datos.
Interpretación
Utilice los residuos studentizados eliminados para detectar valores atípicos. Cada observación se omite para determinar qué tan bien el modelo predice la respuesta cuando no está incluida en el proceso de ajuste del modelo. Los residuos studentizados eliminados mayores que 2 o menores que −2 generalmente se consideran grandes. Las observaciones que Minitab etiqueta no siguen adecuadamente la ecuación de regresión propuesta. Sin embargo, se espera que haya algunas observaciones poco comunes. Por ejemplo, con base en los criterios para los residuos grandes, se esperaría que aproximadamente el 5% de las observaciones sean marcadas como observaciones con un residuo grande. Si el análisis revela muchas observaciones poco comunes, el modelo probablemente no describe adecuadamente la relación entre los predictores y la variable de respuesta. Para obtener más información, vaya a Observaciones poco comunes.
Los residuos estandarizados y eliminados podrían ser más útiles que los residuos sin procesar en la identificación de valores atípicos. Se ajustan a las posibles diferencias en la varianza de residuos sin procesar debido a los diferentes valores de los predictores o factores.
Hi (apalancamiento)
El Hi, también denominado apalancamiento, mide la distancia del valor x de una observación hasta el promedio de los valores x de todas las observaciones en un conjunto de datos.
Interpretación
Los valores de Hi están entre 0 y 1. Minitab identifica las observaciones con valores de apalancamiento superior a 3p/n o 0.99, el valor que sea menor, mediante una X en la tabla de ajustes y diagnósticos de observaciones poco usuales. En 3p/n, p es el número de coeficientes en el modelo y n es el número de observaciones. Las observaciones que Minitab etiqueta con una 'X' podrían ser influyentes.
Las observaciones influyentes tienen un efecto desproporcionado sobre el modelo y pueden generar resultados engañosos. Por ejemplo, la inclusión o exclusión de un punto influyente puede cambiar el hecho de que un coeficiente sea estadísticamente significativo o no. Las observaciones influyentes pueden ser puntos de apalancamiento, valores atípicos o ambos.
Si ve una observación influyente, determine si la observación es un error de entrada de datos o de medición. Si la observación no es un error de entrada de datos ni de medición, determine qué tan influyente es la observación. En primer lugar, ajuste el modelo con y sin la observación. Luego, compare los coeficientes, los valores p, el R2 y otras informaciones del modelo. Si el modelo cambia significativamente al eliminar la observación influyente, examine más a fondo el modelo para determinar si se especificó de forma incorrecta. Es posible que tenga que recopilar más datos para resolver el problema.
Distancia (D) de Cook
La distancia de Cook (D) mide el efecto que tiene una observación sobre el conjunto de coeficientes en un modelo lineal. La distancia de Cook considera tanto el valor de apalancamiento como el residuo estandarizado de cada observación para determinar el efecto de la observación.
Interpretación
Las observaciones con una D grande pueden ser consideradas influyentes. Un criterio comúnmente utilizado para un valor D grande es cuando D es mayor que la mediana de la distribución F: F(0.5, p. n-p), donde p es el número de términos del modelo, incluyendo la constante y n es el número de observaciones. Otra manera de examinar los valores D consiste en compararlos entre sí, utilizando una gráfica, como una gráfica de valores individuales. Las observaciones con valores D que sean grandes en comparación con los demás valores podrían ser influyentes.
Las observaciones influyentes tienen un efecto desproporcionado sobre el modelo y pueden generar resultados engañosos. Por ejemplo, la inclusión o exclusión de un punto influyente puede cambiar el hecho de que un coeficiente sea estadísticamente significativo o no. Las observaciones influyentes pueden ser puntos de apalancamiento, valores atípicos o ambos.
Si ve una observación influyente, determine si la observación es un error de entrada de datos o de medición. Si la observación no es un error de entrada de datos ni de medición, determine qué tan influyente es la observación. En primer lugar, ajuste el modelo con y sin la observación. Luego, compare los coeficientes, los valores p, el R2 y otras informaciones del modelo. Si el modelo cambia significativamente al eliminar la observación influyente, examine más a fondo el modelo para determinar si se especificó de forma incorrecta. Es posible que tenga que recopilar más datos para resolver el problema.
DFITS
DFITS mide el efecto que tiene cada observación sobre los valores ajustados en un modelo lineal. DFITS representa aproximadamente el número de desviaciones estándar que el valor ajustado cambia cuando cada observación se elimina del conjunto de datos y el modelo se reajusta.
Interpretación
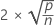
| Término | Description |
|---|---|
| p | el número de términos del modelo |
| n | el número de observaciones |
Las observaciones influyentes tienen un efecto desproporcionado sobre el modelo y pueden generar resultados engañosos. Por ejemplo, la inclusión o exclusión de un punto influyente puede cambiar el hecho de que un coeficiente sea estadísticamente significativo o no. Las observaciones influyentes pueden ser puntos de apalancamiento, valores atípicos o ambos.
Si ve una observación influyente, determine si la observación es un error de entrada de datos o de medición. Si la observación no es un error de entrada de datos ni de medición, determine qué tan influyente es la observación. En primer lugar, ajuste el modelo con y sin la observación. Luego, compare los coeficientes, los valores p, el R2 y otras informaciones del modelo. Si el modelo cambia significativamente al eliminar la observación influyente, examine más a fondo el modelo para determinar si se especificó de forma incorrecta. Es posible que tenga que recopilar más datos para resolver el problema.