En este tema
- R-cuad.(ajustado)
- Componentes de la varianza
- Cuadrados medios esperados
- Estadístico F para modelos con factores aleatorios
- Cómo se calculan los estadísticos F en la salida de ANOVA
- ¿Por qué incluye la salida de mi ANOVA una "x" al lado del valor p en la tabla ANOVA y la etiqueta "No es una prueba F exacta"?
- Acerca del mensaje "El denominador de la prueba F es cero o no está definido"
- Valor ajustado
- Residuo (Resid.)
Modelo de ANOVA balanceado
El modelo de ANOVA balanceado de tres o más factores es una extensión sencilla de un análisis de dos factores del modelo de varianza,
Un modelo ANOVA balanceado de tres factores con factores A, B y C es:
yijkm = μ + α i+ β j + γ k + (αβ)ij+ (αγ)ik+ (βγ)jk+ (αβγ)ijk+εijkm
Si los factores son fijos, Σαi = 0, Σβj = 0, Σγk = 0, Σ(αβ)ij = 0, Σ(αγ)ik = 0, Σ(βγ)jk = 0, Σ(αβγ)ijk = 0 y εijkm son independientes N(0, σ2).
Si los factores son aleatorios, α i, β j , γk, (αβ)ij, (αγ)ik, (βγ)jk, (αβγ)ijk,y εijkmson variables aleatorias independientes. Las variables son distribuidas normalmente con media cero y varianzas dadas por V(αi) = σ2α,V(β j) = σ2β,V(γk) = σ2γ, V[(αβ)ij] = σ2αβ, V[(αγ)jk] = σ2αγ, V[(βγ)jk] = σ2βγ, V(εijkm) = σ2.
El modelo de tres factores puede extenderse a modelos con más de tres factores.
Medias de factor
Fórmula
El promedio de las observaciones para un factor a un nivel de factor determinado. Las fórmulas son:
Media del Factor A: 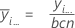
Media del factor B: 
Media del Factor C: 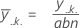
Media general: 
Notación
| Término | Description |
|---|---|
| yi... | la suma de todas las observaciones para el iésimo nivel del factor de A |
| y.j.. | la suma de todas las observaciones para el jésimo nivel del factor de B |
| y..k. | la suma de todas las observaciones para el késimo nivel del factor de C |
| y.... | la suma de todas las observaciones en la muestra |
| a | número de niveles en A |
| b | número de niveles en B |
| c | número de niveles en C |
| n | número de observaciones en cada combinación del factor y los niveles |
Suma de los cuadrados (SC)
La suma de distancias cuadradas. La SC Total es la variación total en los datos. SC (A), SC (B) y SC (C) representan la cantidad de variación alrededor de la media general. También se les conoce como la suma de los cuadrados entre los tratamientos. SC(AB), SC(AC), SC(BC) y SC(ABC) representa la cantidad de variación explicada por cada término de interacción respectivo. El error de SC representa la cantidad de variación entre el valor ajustado y la observación real. Esto se conoce también como un error en los tratamientos. Estas fórmulas asumen un modelo completo que está ajustado. Los cálculos son:

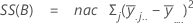

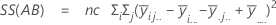
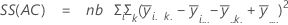
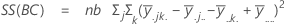
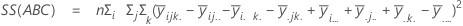
- SC error = SC total - SC (para todos los términos en el modelo)
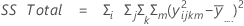
Notación
| Término | Description |
|---|---|
| a | número de niveles en el factor A |
| b | número de niveles en el factor B |
| c | número de niveles en el factor C |
| n | Número total de ensayos |
 | media del iésimo nivel de factor del factor A |
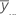 | media general de todas las observaciones |
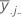 | media del jésimo nivel de factor del factor B |
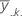 | media del jésimo nivel de factor del factor C |
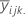 | media de tratamiento estimada |
Grados de libertad (GL)
Los grados de libertad para cada componente del modelo son:
| Fuentes de variación | GL |
|---|---|
| Factor | ki – 1 |
| Covariables e interacciones entre covariables | 1 |
| Interacciones que implican factores | 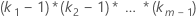 |
| Regresión | p |
| Error | n – p – 1 |
| Total | n – 1 |
Notación
| Término | Description |
|---|---|
| ki | número de niveles en el iésimo factor |
| m | número de factores |
| n | número de observaciones |
| p | número de coeficientes en el modelo, sin contar la constante |
Cuadrado medio (CM)
Fórmulas
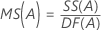
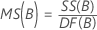
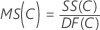
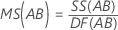
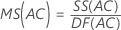
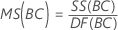
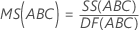
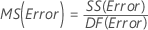
F
Para un ANOVA de 3 factores con todos los factores fijos, estas fórmulas son los estadísticos F cuando el modelo está completo.
Fórmulas



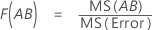
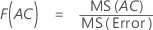
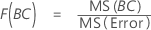
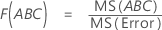
- Para F(A), los grados de libertad del numerador son a - 1 y del denominador son (n - 1)abc.
- Para F(B), los grados de libertad del numerador son b - 1 y del denominador son (n - 1)abc.
- Para F(C), los grados de libertad del numerador son c - 1 y del denominador son (n - 1)abc.
- Para F(AB), los grados de libertad del numerador son (a - 1)(b - 1) y del denominador son (n - 1)abc.
- Para F(AC), los grados de libertad del numerador son (a - 1)(c - 1) y del denominador son (n - 1)abc.
- Para F(BC), los grados de libertad del numerador son (b - 1)(c - 1) y del denominador son (n - 1)abc.
- Para F(ABC), los grados de libertad del numerador son (a - 1)(b - 1)(c - 1) y del denominador son (n - 1)abc.
Si hay factores aleatorios en el modelo, la relación F de cada término se determina mediante el cuadrado medio esperado de cada término.
Valores elevados de F apoyan el rechazo de la hipótesis nula. Se puede concluir que el efecto es estadísticamente significativo.
Valor p – Tabla Análisis de varianza
El valor p es una probabilidad que se calcula a partir de una distribución F con los grados de libertad (GL) que se indican a continuación:
- GL del numerador
- suma de los grados de libertad para el término o los términos en la prueba
- GL del denominador
- grados de libertad para el error
Fórmula
1 − P(F ≤ fj)
Notación
| Término | Description |
|---|---|
| P(F ≤ f) | función de distribución acumulada para la distribución F |
| f | estadístico F para la prueba |
S

Notación
| Término | Description |
|---|---|
| MSE | cuadrado medio del error |
R-cuad.
El R2 también es denominado como el coeficiente de determinación.
Fórmula

Notación
| Término | Description |
|---|---|
| yi | i ésimo valor de respuesta observado |
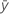 | respuesta media |
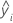 | i iésima respuesta ajustada |
R-cuad.(ajustado)
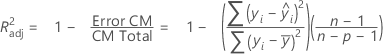
Mientras que los cálculos de R2 ajustados pueden producir valores negativos, Minitab muestra el cero para estos casos.
Notación
| Término | Description |
|---|---|
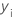 | iésimo valor de respuesta observado |
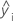 | iésima respuesta ajustada |
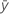 | respuesta media |
| n | número de observaciones |
| p | número de términos en el modelo |
Componentes de la varianza
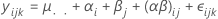
donde, αi, βj , (αβ)ij, y εijk son variables aleatorias independientes. Las variables normalmente están distribuidas con cero media y varianzas dadas por estas fórmulas:
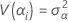

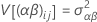

Estas varianzas son los componentes de varianza. En este caso, se prueba la hipótesis de que los componentes de varianza son iguales a cero.
Para un modelo mixto restringido con dos factores, el modelo es:
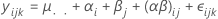
donde αi es un efecto fijo y βj es un efecto aleatorio, (αβ)ij, es un efecto aleatorio, y εijk es un error aleatorio. La Σαi = 0 y la Σ(αβ)ij = 0 para cada j. Las varianzas son V(βj) = σ2β,V[(αβ)ij] =[(a - 1)/a]σ2αβ, y V(εijk) = σ2. σ2β, σ2αβ, y σ2 son componentes de varianza. En resumen el componente de interacción sobre el factor fijo es igual a cero, lo que indica que este es el modelo mixto restringido.
Para un modelo mixto no restringido con un factor fijo, A, y un factor aleatorio, B, esta fórmula describe el modelo:

donde αi son efectos fijos y βj, (αβ)ij y εijk son variables aleatorias no relacionadas que tienen medias de cero y estas varianzas:

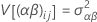

Estas varianzas son los componentes de varianza. La Σα i = 0 y Σ(αβ)ij = 0 para cada j.
Esta información es para modelos balanceados. Para información sobre modelos más complejos o no balanceados, véase Montgomery1 y Neter2.
- D.C. Montgomery (1991). Design and Analysis of Experiments, Third Edition. John Wiley & Sons.
- J. Neter, W. Wasserman and M.H. Kutner (1985). Applied Linear Statistical Models, Second Edition. Irwin, Inc.
Cuadrados medios esperados
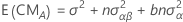
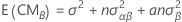

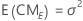
Las fórmulas de los cuadrados medios esperados para un modelo mixto restringido con dos factores, A (fijo) y B (aleatorio) son:



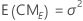
Las fórmulas de los cuadrados medios esperados para un modelo mixto sin restricciones con un factor fijo, A, y un factor aleatorio, B, son:
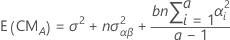
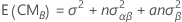

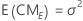
Para las reglas sobre como calcular los cuadrados medios esperados y para información sobre modelos más complejos o no balanceados, véase Montgomery1 y Neter2.
- D.C. Montgomery (1991). Design and Analysis of Experiments, Third Edition. John Wiley & Sons.
- J. Neter, W. Wasserman and M.H. Kutner (1985). Applied Linear Statistical Models, Second Edition. Irwin, Inc.
Notación
| Término | Description |
|---|---|
| b | número de niveles en el factor B |
| a | número de niveles en el factor A |
| n | número de observaciones |
| σ2 | varianza estimada del modelo |
 | varianza estimada de A |
 | varianza estimada de B |
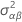 | varianza estimada de AB |
 | efectos fijos de A |
Estadístico F para modelos con factores aleatorios
Cómo se calculan los estadísticos F en la salida de ANOVA
Cada estadístico F es una relación de cuadrados medios. El numerador es el cuadrado medio del término. El denominador se escoge de manera que el valor esperado del cuadrado medio del numerador difiera del valor esperado del cuadrado medio del denominador solo por el efecto de interés. El efecto de un término aleatorio está representado por el componente de la varianza del término. El efecto de un término fijo está representado por la suma de los cuadrados de los componentes del modelo asociados con ese término dividida entre sus grados de libertad. Por lo tanto, un estadístico F alto indica un efecto significativo.
Cuando todos los términos del modelo son fijos, el denominador para cada estadístico F es el cuadrado medio del error (MSE). Sin embargo, para los modelos que incluyen términos aleatorios, el MSE no siempre es el cuadrado medio correcto. Los cuadrados medios esperados (EMS) pueden utilizarse para determinar qué es lo apropiado para el denominador.
Ejemplo
| Fuente | Cuadrado medio esperado para cada término |
|---|---|
| (1) Pantalla | (4) + 2.00(3) + Q[1] |
| (2) Tecno | (4) + 2,0000(3) + 4,0000(2) |
| (3) Pantalla*Tecno | (4) + 2,0000(3) |
| (4) Error | (4) |
Un número entre paréntesis indica un efecto aleatorio asociado con el término que aparece al lado del número de la fuente. (2) representa el efecto aleatorio de Tecno, (3) representa el efecto aleatorio de la interacción Pantalla*Tecno y (4) representa el efecto aleatorio del Error. El EMS para Error es el efecto del término de error. Además, el EMS para Pantalla*Tecno es el efecto del término de error más dos veces el efecto de la interacción Pantalla*Tecno.
Para calcular el estadístico F de Pantalla*Tecno, el cuadrado medio de Pantalla*Tecno se divide entre el cuadrado medio del error de modo que el valor esperado del numerador (EMS para Pantalla*Tecno = (4) + 2.00(3)) difiera del valor esperado del denominador (EMS para Error = (4)) solo por el efecto de la interacción (2.00(3)). Por lo tanto, un estadístico F alto indica una interacción Pantalla*Tecno significativa.
Un número con Q[ ] indica el efecto fijo asociado con el término que aparece al lado del número de la fuente. Por ejemplo, Q[1] es el efecto fijo de Pantalla. El EMS para Pantalla es el efecto del término de error más dos veces el efecto de la interacción Pantalla*Tecno más una constante multiplicada por el efecto de Pantalla. Q[1] es igual a (b*n * suma((coeficientes de los niveles de Pantalla)**2)) dividido entre (a - 1), donde a y b son el número de niveles de Pantalla y Tecno, respectivamente, y n es el número de réplicas.
Para calcular el estadístico F para Pantalla, el cuadrado medio de Pantalla se divide entre el cuadrado medio de Pantalla*Tecno de modo que el valor esperado del numerador (EMS para Pantalla = (4) + 2.0000(3) + Q[1]) difiera del valor esperado del denominador (EMS para Pantalla*Tecno = (4) + 2.0000(3) ) solo por el efecto debido a la Pantalla (Q[1]). Por lo tanto, un estadístico F alto indica un efecto significativo de Pantalla.
¿Por qué incluye la salida de mi ANOVA una "x" al lado del valor p en la tabla ANOVA y la etiqueta "No es una prueba F exacta"?
Una prueba F exacta para un término es aquella en la que el valor esperado de los cuadrados medios del numerador difiere del valor esperado de los cuadrados medios del denominador solo por el componente de la varianza o el factor fijo de interés.
Sin embargo, a veces no es posible calcular ese cuadrado medio. En ese caso, Minitab utiliza un cuadrado medio que da como resultado una prueba F aproximada y muestra una "x" al lado el valor p para indicar que la prueba F no es exacta.
| Fuente | Cuadrado medio esperado para cada término |
|---|---|
| (1) Suplemento | (4) + 1,7500(3) + Q[1] |
| (2) Lago | (4) + 1,7143(3) + 5,1429(2) |
| (3) Suplemento*Lago | (4) + 1,7500(3) |
| (4) Error | (4) |
El estadístico F para Suplemento es el cuadrado medio de Suplemento dividido entre el cuadrado medio de la interacción Suplemento*Lago. Si el efecto para Suplemento es muy pequeño, el valor esperado del numerador es igual al valor esperado del denominador. Este es un ejemplo de una prueba F exacta.
Sin embargo, observe que para un efecto muy pequeño de Lago no hay cuadrados medios tales que el valor esperado del numerador sea igual al valor esperado del denominador. Por lo tanto, Minitab utiliza una prueba F aproximada. En este ejemplo, el cuadrado medio de Lago se divide entre el cuadrado medio de la interacción Suplemento*Lago. Esto da como resultado un valor esperado del numerador que es aproximadamente igual al del denominador si el efecto de Lago es muy pequeño.
Acerca del mensaje "El denominador de la prueba F es cero o no está definido"
- No hay al menos un grado de libertad para el error.
-
Los valores ajustados de CM son muy pequeños y por lo tanto no hay suficiente precisión para mostrar los valores p y F. Como una solución, multiplique la columna de respuesta por 10. Entonces ejecute el mismo modelo de regresión, pero en cambio utilice esta nueva columna de respuesta para la respuesta.
Nota
Multiplicar los valores de respuesta por 10 no afectará los valores F y p que Minitab muestra en la salida. Sin embargo, la posición decimal se verá afectada en la salida restante, específicamente, las sumas secuenciales de los cuadrados, SC Ajust., CM Ajust., Ajuste, error estándar de los ajustes y las columnas de residuos.
Cómo se calculan los estadísticos F en la salida de ANOVA
Cada estadístico F es una relación de cuadrados medios. El numerador es el cuadrado medio del término. El denominador se escoge de manera que el valor esperado del cuadrado medio del numerador difiera del valor esperado del cuadrado medio del denominador solo por el efecto de interés. El efecto de un término aleatorio está representado por el componente de la varianza del término. El efecto de un término fijo está representado por la suma de los cuadrados de los componentes del modelo asociados con ese término dividida entre sus grados de libertad. Por lo tanto, un estadístico F alto indica un efecto significativo.
Cuando todos los términos del modelo son fijos, el denominador para cada estadístico F es el cuadrado medio del error (MSE). Sin embargo, para los modelos que incluyen términos aleatorios, el MSE no siempre es el cuadrado medio correcto. Los cuadrados medios esperados (EMS) pueden utilizarse para determinar qué es lo apropiado para el denominador.
Ejemplo
| Fuente | Cuadrado medio esperado para cada término |
|---|---|
| (1) Pantalla | (4) + 2.00(3) + Q[1] |
| (2) Tecno | (4) + 2,0000(3) + 4,0000(2) |
| (3) Pantalla*Tecno | (4) + 2,0000(3) |
| (4) Error | (4) |
Un número entre paréntesis indica un efecto aleatorio asociado con el término que aparece al lado del número de la fuente. (2) representa el efecto aleatorio de Tecno, (3) representa el efecto aleatorio de la interacción Pantalla*Tecno y (4) representa el efecto aleatorio del Error. El EMS para Error es el efecto del término de error. Además, el EMS para Pantalla*Tecno es el efecto del término de error más dos veces el efecto de la interacción Pantalla*Tecno.
Para calcular el estadístico F de Pantalla*Tecno, el cuadrado medio de Pantalla*Tecno se divide entre el cuadrado medio del error de modo que el valor esperado del numerador (EMS para Pantalla*Tecno = (4) + 2.00(3)) difiera del valor esperado del denominador (EMS para Error = (4)) solo por el efecto de la interacción (2.00(3)). Por lo tanto, un estadístico F alto indica una interacción Pantalla*Tecno significativa.
Un número con Q[ ] indica el efecto fijo asociado con el término que aparece al lado del número de la fuente. Por ejemplo, Q[1] es el efecto fijo de Pantalla. El EMS para Pantalla es el efecto del término de error más dos veces el efecto de la interacción Pantalla*Tecno más una constante multiplicada por el efecto de Pantalla. Q[1] es igual a (b*n * suma((coeficientes de los niveles de Pantalla)**2)) dividido entre (a - 1), donde a y b son el número de niveles de Pantalla y Tecno, respectivamente, y n es el número de réplicas.
Para calcular el estadístico F para Pantalla, el cuadrado medio de Pantalla se divide entre el cuadrado medio de Pantalla*Tecno de modo que el valor esperado del numerador (EMS para Pantalla = (4) + 2.0000(3) + Q[1]) difiera del valor esperado del denominador (EMS para Pantalla*Tecno = (4) + 2.0000(3) ) solo por el efecto debido a la Pantalla (Q[1]). Por lo tanto, un estadístico F alto indica un efecto significativo de Pantalla.
¿Por qué incluye la salida de mi ANOVA una "x" al lado del valor p en la tabla ANOVA y la etiqueta "No es una prueba F exacta"?
Una prueba F exacta para un término es aquella en la que el valor esperado de los cuadrados medios del numerador difiere del valor esperado de los cuadrados medios del denominador solo por el componente de la varianza o el factor fijo de interés.
Sin embargo, a veces no es posible calcular ese cuadrado medio. En ese caso, Minitab utiliza un cuadrado medio que da como resultado una prueba F aproximada y muestra una "x" al lado el valor p para indicar que la prueba F no es exacta.
| Fuente | Cuadrado medio esperado para cada término |
|---|---|
| (1) Suplemento | (4) + 1,7500(3) + Q[1] |
| (2) Lago | (4) + 1,7143(3) + 5,1429(2) |
| (3) Suplemento*Lago | (4) + 1,7500(3) |
| (4) Error | (4) |
El estadístico F para Suplemento es el cuadrado medio de Suplemento dividido entre el cuadrado medio de la interacción Suplemento*Lago. Si el efecto para Suplemento es muy pequeño, el valor esperado del numerador es igual al valor esperado del denominador. Este es un ejemplo de una prueba F exacta.
Sin embargo, observe que para un efecto muy pequeño de Lago no hay cuadrados medios tales que el valor esperado del numerador sea igual al valor esperado del denominador. Por lo tanto, Minitab utiliza una prueba F aproximada. En este ejemplo, el cuadrado medio de Lago se divide entre el cuadrado medio de la interacción Suplemento*Lago. Esto da como resultado un valor esperado del numerador que es aproximadamente igual al del denominador si el efecto de Lago es muy pequeño.
Acerca del mensaje "El denominador de la prueba F es cero o no está definido"
- No hay al menos un grado de libertad para el error.
-
Los valores ajustados de CM son muy pequeños y por lo tanto no hay suficiente precisión para mostrar los valores p y F. Como una solución, multiplique la columna de respuesta por 10. Entonces ejecute el mismo modelo de regresión, pero en cambio utilice esta nueva columna de respuesta para la respuesta.
Nota
Multiplicar los valores de respuesta por 10 no afectará los valores F y p que Minitab muestra en la salida. Sin embargo, la posición decimal se verá afectada en la salida restante, específicamente, las sumas secuenciales de los cuadrados, SC Ajust., CM Ajust., Ajuste, error estándar de los ajustes y las columnas de residuos.
Valor ajustado
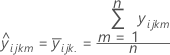
Notación
Para un modelo de 3 factores:
| Término | Description |
|---|---|
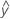 | el valor ajustado para la observación en el iésimo nivel del factor A, el jésimo nivel del factor B, el késimo nivel del factor C |
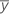 | el valor medio para la observación en el iésimo nivel del factor A, el jésimo nivel del factor B, el késimo nivel del factor C |
| n | el número de observaciones en el iésimo nivel del factor A, el jésimo nivel del factor B, el késimo nivel del factor C |
Residuo (Resid.)
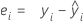
Notación
| Término | Description |
|---|---|
| ei | i ésimo residuo |
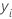 | i ésimo valor de respuesta observado |
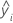 | i iésima respuesta ajustada |