In This Topic
Length
The number of observations in the time series.
NMissing
The number of missing values in the time series.
Fitted Trend Equation
Use the fitted trend equation to calculate the trend component for a specific time period. The fitted trend equation is an algebraic representation of the trend line. The form of the fitted trend equation is Yt = b0 + (b1 * t).
- yt is the variable
- b0 is the constant
- b1 is the slope
- t is the value of the time unit
Minitab uses the fitted trend equation and the seasonal indices to calculate the predicted values.
Interpretation
Minitab uses the fitted trend equation to calculate the trend component, which is used in conjunction with the seasonal indices to calculate the predicted values. For example, if the fitted trend equation is:
Yt = 173.06 + 2.111*t
The trend component for the third period is 173.06 + 2.11*3 = 182.45
Minitab also calculates the detrended data by either dividing the data by the trend component (multiplicative model) or subtracting the trend component from the data (additive model).
Seasonal Indices and Seasonal
The seasonal indices (also called Seasonal in the table with the original data) are the seasonal effects at time t. Minitab uses the indices to seasonally adjust the data, either by dividing the data by the seasonal indices (multiplicative model) or by subtracting the seasonal indices from the data (additive model). Minitab also uses the fitted trend equation and the seasonal indices to calculate the predicted values.
MAPE
The mean absolute percent error (MAPE) expresses accuracy as a percentage of the error. Because the MAPE is a percentage, it can be easier to understand than the other accuracy measure statistics. For example, if the MAPE is 5, on average, the forecast is off by 5%.
However, sometimes you may see a very large value of MAPE even though the model appears to fit the data well. Examine the plot to see if any data values are close to 0. Because MAPE divides the absolute error by the actual data, values close to 0 can greatly inflate the MAPE.
Interpretation
Use to compare the fits of different time series models. Smaller values indicate a better fit. If a single model does not have the lowest values for all 3 accuracy measures, MAPE is usually the preferred measurement.
The accuracy measures are based on one-period-ahead residuals. At each point in time, the model is used to predict the Y value for the next period in time. The difference between the predicted values (fits) and the actual Y are the one-period-ahead residuals. Because of this, the accuracy measures provide an indication of the accuracy you might expect when you forecast out 1 period from the end of the data. Therefore, they do not indicate the accuracy of forecasting out more than 1 period. If you're using the model for forecasting, you shouldn't base your decision solely on accuracy measures. You should also examine the fit of the model to ensure that the forecasts and the model follow the data closely, especially at the end of the series.
MAD
The mean absolute deviation (MAD) expresses accuracy in the same units as the data, which helps conceptualize the amount of error. Outliers have less of an effect on MAD than on MSD.
Interpretation
Use to compare the fits of different time series models. Smaller values indicate a better fit.
The accuracy measures are based on one-period-ahead residuals. At each point in time, the model is used to predict the Y value for the next period in time. The difference between the predicted values (fits) and the actual Y are the one-period-ahead residuals. Because of this, the accuracy measures provide an indication of the accuracy you might expect when you forecast out 1 period from the end of the data. Therefore, they do not indicate the accuracy of forecasting out more than 1 period. If you're using the model for forecasting, you shouldn't base your decision solely on accuracy measures. You should also examine the fit of the model to ensure that the forecasts and the model follow the data closely, especially at the end of the series.
MSD
The mean square deviation (MSD) measures the accuracy of the fitted time series values. Outliers have a greater effect on MSD than on MAD.
Interpretation
Use to compare the fits of different time series models. Smaller values indicate a better fit.
The accuracy measures are based on one-period-ahead residuals. At each point in time, the model is used to predict the Y value for the next period in time. The difference between the predicted values (fits) and the actual Y are the one-period-ahead residuals. Because of this, the accuracy measures provide an indication of the accuracy you might expect when you forecast out 1 period from the end of the data. Therefore, they do not indicate the accuracy of forecasting out more than 1 period. If you're using the model for forecasting, you shouldn't base your decision solely on accuracy measures. You should also examine the fit of the model to ensure that the forecasts and the model follow the data closely, especially at the end of the series.
Trend
The trend values are the trend components that are calculated by the fitted trend equation.
Interpretation
The trend component for a specific time period is calculated by entering the specific time values for each observation in the data set into the fitted trend equation. For example, if the fitted trend equation is Yt = 5 + 10*t, the trend value at time 2, is 25 (25 = 5 + 10(2)).
Detrend
Detrend values are the data with the trend component removed. The detrend values are either the differences between the observed values and the trend values (additive model) or the ratio between the observed values and the trend values (multiplicative model).
Deseason
Deseason values are the data with the seasonal component removed. The deseason values are either the differences between the observed values and the seasonal values (additive model) or the observed values divided by the seasonal values (multiplicative model).
Predict
The predicted values are also called fits. The predicted values are point estimates of the variable at time (t).
Observations that have predicted values that are very different from the observed value may be unusual or influential. Try to identify the cause of any outliers. Correct any data-entry errors or measurement errors. Consider removing data values that are associated with abnormal, one-time events (special causes). Then, repeat the analysis.
Error
The error values are also called residuals. The error values are the differences between the observed values and the predicted values.
Interpretation
Plot the error values to determine whether your model is adequate. The values can provide useful information about how well the model fits the data. In general, the error values should be randomly distributed around 0 with no obvious patterns and no unusual values.
Period
Minitab displays the period when you generate forecasts. The period is the time unit of the forecast. By default, the forecasts start at the end of the data.
Forecast
The forecasts are the fitted values obtained from the time series model. Minitab displays the number of forecasts that you specify. The forecasts begin either at the end of the data or at the point of origin that you specify.
Interpretation
Use forecasts to predict a variable for a specified period of time. For example, a warehouse manager can model how much product to order for the next 3 months based on the previous 60 months of orders.
Decomposition uses a fixed trend line and fixed seasonal indices. Because both the trend and the seasonal indices are fixed, you should only use decomposition to forecast when the trend and seasonality are very consistent. It is especially important to verify that the fits match the actual values at the end of the time series. If the seasonal pattern or trend do not match up with the fits at the end of the data, use Winters' Method.
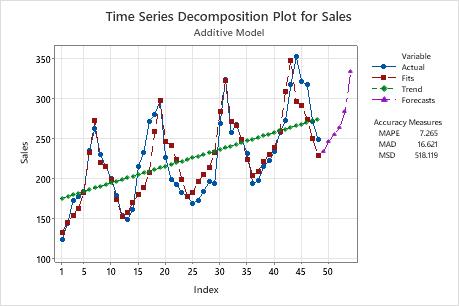
On this plot, the model underpredicts the data at the end of the series. This indicates that the trend or seasonal pattern are not consistent. If you want to forecast this data, you should try Winters' method to determine whether it provides a better fit to the data.
Time Series Decomposition Plot
The plot displays the observations versus time. The plot includes the trend line, the fits that are calculated from the trend and seasonal components, the forecasts, and the accuracy measures.
Interpretation
- If the model fits the data, you can perform Winters' Method and compare the two models.
- Decomposition uses a constant linear trend. If the trend appears to have curvature, decomposition will not provide a good fit. You should use Winters' Method.
- If the model does not fit the data, examine the plot for a lack of seasonality. If there is no seasonal pattern, you should use a different time series analysis. For more information, go to Which time series analysis should I use?.
On this plot, the fits closely follow the data, which indicates that the model fits the data.
Component Analysis
- Original Data
- A time series plot of the original data
- Detrended Data
- Detrend values are the data with the trend component removed. The detrend values are either the differences between the observed values and the trend values (additive model) or the observed values divided by the trend values (multiplicative model). If the plot of the detrend data looks different from the original data, you can conclude that a trend component exists in the data.
- Seasonally Adjusted Data
- Seasonally adjusted values are the data with the seasonal component removed. The seasonally adjusted values are either the differences between the observed values and the seasonal values (additive model) or the observed values divided by the seasonal values (multiplicative model). If the plot of the seasonally adjusted data looks different from the original data, you can conclude that a seasonal component exists in the data.
- Seas. Adj. and Detr. Data
- The seasonally adjusted and detrend values are also called residuals. The residuals are the differences between the observed values and the predicted values. Examine the plot to determine whether your model is adequate. The residuals should be randomly distributed with no obvious patterns and no unusual values.
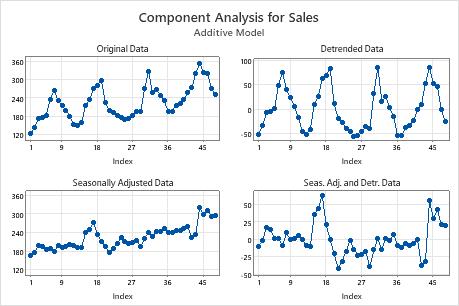
In this plot, the detrended data and the seasonally adjusted data look different from the original observations. You can conclude that a trend component and a seasonal component exist in the data. The large positive residuals near the end of the data indicate that the model underpredicts those time periods.
Seasonal Analysis
- Seasonal Indices
- The seasonal indices are the seasonal effects at time t. Use the plot to determine the direction of the seasonal effect.
- Detrended Data by Season
- The detrended data are the data with the trend component removed. Use the boxplots to determine which seasonal period has the most and least variation.
- Percent Variation by Season
- The plot shows the percent of variation for each season. Use the plot to quantify the variation of each seasonal period.
- Residuals by Season
- The residuals are the differences between the observed values and the predicted values. Use the plot to determine whether there is a seasonal effect on the residuals.
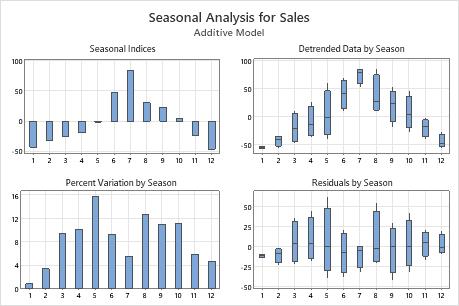
On this plot, the seasonal indices indicate average downward movements in the first 5 months and the last 2 months of the season and average upward movements in the 6th to the 10th month. The chart of percent variation by season shows that the 1st month has the least variation and the 5th month has the most variation. The boxplots of the detrended data by season show that months where the absolute value of the seasonal effect is large tend to have less variation than months where the seasonal effect is smaller. The residuals by season plot does not show any obvious effect of season on the residuals.
Histogram of the residuals
The histogram of the residuals shows the distribution of the residuals for all observations. lf the model fits the data well, the residuals should be random with a mean of 0. So the histogram should be approximately symmetric around 0.
Normal probability plot of the residuals
The normal plot of the residuals displays the residuals versus their expected values when the distribution is normal.
Interpretation
Use the normal plot of the residuals to determine whether the residuals are normally distributed. However, this analysis does not require normally distributed residuals.
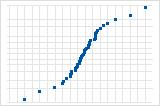
S-curve implies a distribution with long tails.
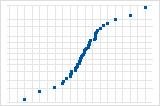
Inverted S-curve implies a distribution with short tails.
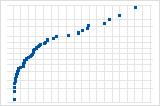
Downward curve implies a right-skewed distribution.
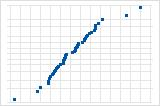
A few points lying away from the line implies a distribution with outliers.
Residuals versus fits
The residuals versus fits plot displays the residuals on the y-axis and the fitted values on the x-axis.
Interpretation
Use the residuals versus fits plot to determine whether the residuals are unbiased and have a constant variance. Ideally, the points should fall randomly on both sides of 0, with no recognizable patterns in the points.
| Pattern | What the pattern may indicate |
|---|---|
| Fanning or uneven spreading of residuals across fitted values | Nonconstant variance |
| Curvilinear | A missing higher-order term |
| A point that is far away from zero | An outlier |
If you see nonconstant variance or patterns in the residuals, your forecasts may not be accurate.
Residuals versus order
The residuals versus order plot displays the residuals in the order that the data were collected.
Interpretation
Use the residuals versus order plot to determine how accurate the fits are compared to the observed values during the observation period. Patterns in the points may indicate that model does not fit the data. Ideally, the residuals on the plot should fall randomly around the center line.
| Pattern | What the pattern may indicate |
|---|---|
| A consistent long-term trend | The model does not fit the data |
| A short-term trend | A shift or a change in pattern |
| A point that is far away from the other points | An outlier |
| A sudden shift in the points | The underlying pattern for the data has changed |
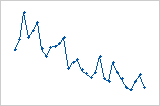
Residuals systematically decrease as the order of the observations increases from left to right.
A sudden change in the values of the residuals occurs from low (left) to high (right).
Residuals versus variables
The residuals versus variables plot displays the residuals versus another variable.
Interpretation
Use the plot to determine whether the variable affects the response in a systematic way. If patterns are present in the residuals, the other variables are associated with the response. You can use this information as the basis for additional studies.