Note
This command is available with the Predictive Analytics Module. Click here for more information about how to activate the module.
A team of researchers wants to use data from an injection molding process to study settings for machines that maximize one type of strength of a plastic part. The variables include controls on the machines, different plastic formulas, and the injection molding machines.
As part of the initial exploration of the data, the team decides to use Discover Key Predictors to compare models by sequentially removing unimportant predictors to identify key predictors. The researchers hope to identify key predictors that have the most effect on response and gain more insight into the relationships between the response and the key predictors.
- Open the sample data set InjectionProcess.MWX.
- Choose .
- In Response, enter Strength.
- In Continuous predictors, enter 'Injection Pressure' – 'Temperature at Measurement'.
- In Categorical predictors, enter Machine and Formula.
- Click OK.
Interpret the results
For this analysis, Minitab Statistical Software compares 20 models. The asterisk in the Model column of the Model Evaluation table shows that the model with the greatest value of the cross-validated R2 statistic is model 16. Model 16 contains 5 important predictors. The results that follow the model evaluation table are for model 16.
Although Model 16 has the greatest value of the cross-validated R2 statistic, other models have similar values. The team can click Select Alternative Model to produce results for other models from the Model Evaluation table.
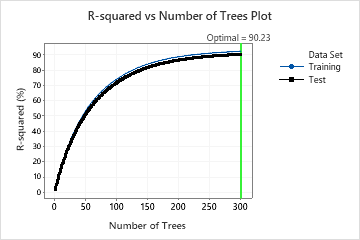
In the results for Model 16, the R-squared vs. Number of Trees Plot shows that the optimal number of trees equals the number of trees in the analysis, 300. The team can click Tune Hyperparameters to increase the number of trees and to see whether changes to other hyperparameters improve the performance of the model.
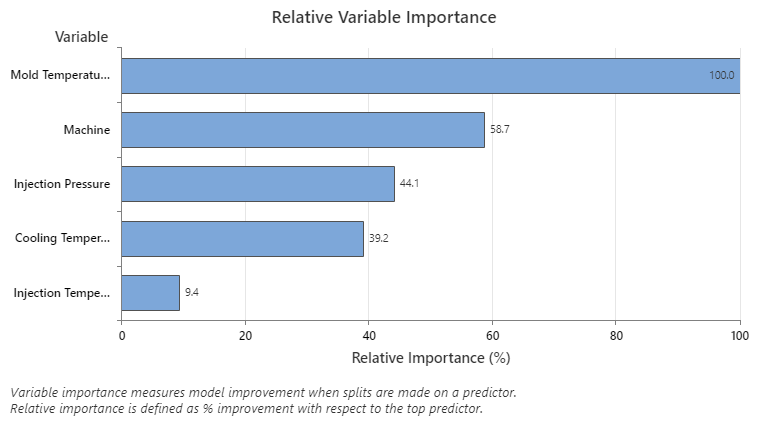
The Relative Variable Importance graph plots the predictors in order of their effect on model improvement when splits are made on a predictor over the sequence of trees. The most important predictor variable is Mold Temperature. If the importance of the top predictor variable, Mold Temperature, is 100%, then the next important variable, Machine, has a contribution of 58.7%. This means the machine that injects is 58.7% as important as the temperature inside the mold.
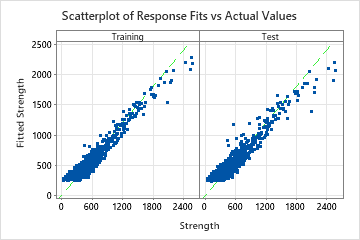
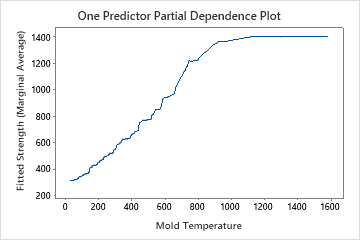
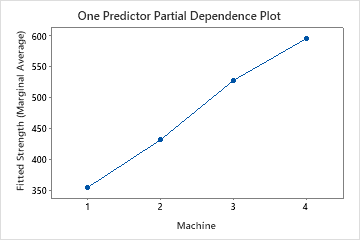
Use the partial dependency plots to gain insight into how the important variables or pairs of variables affect the predicted response. The partial dependence plots show whether the relationship between the response and a variable is linear, monotonic, or more complex.
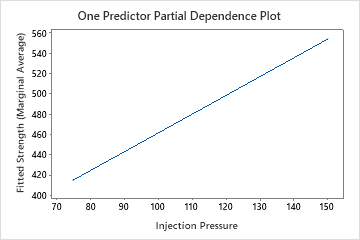
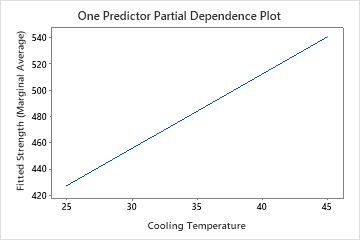
The one predictor partial dependence plots show that mold temperature, injection pressure, and cooling temperature all have a positive relationship with strength. The plot of the machines shows the differences between machines, with machine 1 making the weakest parts on average and machine 4 making the strongest parts on average. The team notices that the mold temperature and the machine have the strongest interaction in the data, so they look at the two-predictor partial dependence plot to further understand how these variables affect strength. The team can select in the results to produce plots for other variables, such as Injection Temperature.
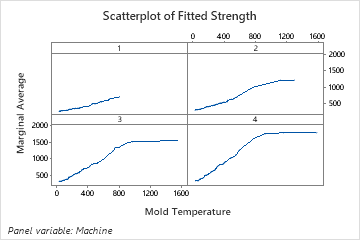
The two-predictor partial dependence plot of Mold Temperature and Machine gives some insight into the difference average strengths for the machines. One reason is that the data from machine 1 do not include as many observations at the highest mold temperatures as the other machines. The team could still decide to look for other reasons that the machines produce different strengths when other settings are the same. The team can click in the results to produce plots for other pairs of variables.
Method
| Loss function | Squared error |
|---|---|
| Criterion for selecting optimal number of trees | Maximum R-squared |
| Model validation | 3-fold cross-validation |
| Learning rate | 0.01408 |
| Subsample fraction | 0.5 |
| Maximum terminal nodes per tree | 6 |
| Minimum terminal node size | 3 |
| Number of predictors selected for node splitting | Total number of predictors = 21 |
| Rows used | 1408 |
Response Information
| Mean | StDev | Minimum | Q1 | Median | Q3 | Maximum |
|---|---|---|---|---|---|---|
| 485.247 | 318.611 | 41.2082 | 301.099 | 398.924 | 562.449 | 2569.04 |
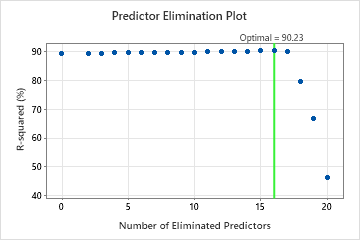
Model Selection by Eliminating Unimportant Predictors
| Model | Optimal Number of Trees | R-squared (%) | Number of Predictors | Eliminated Predictors |
|---|---|---|---|---|
| 1 | 300 | 89.32 | 21 | None |
| 2 | 300 | 89.34 | 19 | Plastic Flow Rate, Change Position |
| 3 | 300 | 89.39 | 18 | Drying Temperature |
| 4 | 300 | 89.46 | 17 | Melt Temperature Zone 2 |
| 5 | 300 | 89.51 | 16 | Plastic Temperature |
| 6 | 300 | 89.50 | 15 | Formula |
| 7 | 300 | 89.59 | 14 | Hold Pressure |
| 8 | 300 | 89.57 | 13 | Screw cushion |
| 9 | 300 | 89.69 | 12 | Melt Temperature Zone 4 |
| 10 | 300 | 89.70 | 11 | Back Pressure |
| 11 | 300 | 89.86 | 10 | Melt Temperature Zone 1 |
| 12 | 300 | 89.90 | 9 | Drying Time |
| 13 | 300 | 89.92 | 8 | Temperature at Measurement |
| 14 | 300 | 90.06 | 7 | Melt Temperature Zone 5 |
| 15 | 300 | 90.16 | 6 | Melt Temperature Zone 3 |
| 16* | 300 | 90.23 | 5 | Screw Rotation Speed |
| 17 | 300 | 89.96 | 4 | Injection Temperature |
| 18 | 297 | 79.37 | 3 | Cooling Temperature |
| 19 | 244 | 66.64 | 2 | Injection Pressure |
| 20 | 164 | 46.19 | 1 | Machine |
Model Summary
| Total predictors | 5 |
|---|---|
| Important predictors | 5 |
| Number of trees grown | 300 |
| Optimal number of trees | 300 |
| Statistics | Training | Cross-validation |
|---|---|---|
| R-squared | 92.23% | 90.23% |
| Root mean squared error (RMSE) | 88.8049 | 99.5673 |
| Mean squared error (MSE) | 7886.3152 | 9913.6420 |
| Mean absolute deviation (MAD) | 68.9231 | 74.4113 |
| Mean absolute percent error (MAPE) | 0.2083 | 0.2175 |