In This Topic
Fit
Fitted values are also called fits or 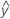 . The fitted values are point estimates of the standard deviation response for given values of the predictors. The values of the predictors are also called x-values.
. The fitted values are point estimates of the standard deviation response for given values of the predictors. The values of the predictors are also called x-values.
Interpretation
Fitted values are calculated by entering the specific x-values for each observation in the data set into the model equation.
For example, if the equation is ln (y) = ln (5 + 10x), the fitted value for the x-value, 2, is 3.21888 (ln(5 + 10(2))).
Observations with fitted values that are very different from the observed value may be unusual. Observations with unusual predictor values may be influential. If Minitab determines that your data include unusual or influential values, your output includes the table of Fits and Diagnostics for Unusual Observations, which identifies these observations. The observations with large standardized residuals do not follow the proposed regression equation well. However, it is expected that you will have some unusual observations. For example, based on the criteria for large standardized residuals, you would expect roughly 5% of your observations to be flagged as having a large standardized residual. For more information on unusual values, go to Unusual observations.
Confidence interval for original response (95% CI)
These confidence intervals (CI) are ranges of values that are likely to contain the standard deviation response for the population that has the observed values of the predictors or factors in the model.
Because samples are random, two samples from a population are unlikely to yield identical confidence intervals. But, if you sample many times, a certain percentage of the resulting confidence intervals contain the unknown population parameter. The percentage of these confidence intervals that contain the parameter is the confidence level of the interval.
- Point estimate
- The point estimate is calculated from the sample data.
- Margin of error
- The margin of error defines the width of the confidence interval and is determined by the observed variability in the sample, the sample size, and the confidence level.
Interpretation
Use the confidence interval to assess the estimate of the fitted value for the observed values of the variables.
For example, with a 95% confidence level, you can be 95% confident that the confidence interval contains the population standard deviation for the specified values of the predictor variables or factors in the model. The confidence interval helps you assess the practical significance of your results. Use your specialized knowledge to determine whether the confidence interval includes values that have practical significance for your situation. A wide confidence interval indicates that you can be less confident about the standard deviation of future values. If the interval is too wide to be useful, consider increasing your sample size.
Ratio residual
The ratio residual is the observed standard deviation divided by the fitted value.
Ln(Std)
The natural log of the observed response standard deviation.
Ln (Fit)
The natural log of the fitted standard deviation.
SE Ln(Fit)
The standard error of the natural log of the fitted standard deviation estimates the variation in the estimated standard deviation for the specified variable settings. The calculation of the confidence interval for the mean response uses the standard error of the fit. Standard errors are always non-negative.
Interpretation
Use the standard error of the fit to measure the precision of the estimate of the natural log of the standard deviation. The smaller the standard error, the more precise the estimate.
Confidence interval for transformed response (95% CI)
These confidence intervals (CI) are ranges of values that are likely to contain the natural log of the standard deviation for the population that has the observed values of the predictors or factors in the model.
Because samples are random, two samples from a population are unlikely to yield identical confidence intervals. But, if you sample many times, a certain percentage of the resulting confidence intervals contain the unknown population parameter. The percentage of these confidence intervals that contain the parameter is the confidence level of the interval.
- Point estimate
- The point estimate is calculated from the sample data.
- Margin of error
- The margin of error defines the width of the confidence interval and is determined by the observed variability in the sample, the sample size, and the confidence level.
Interpretation
Use the confidence interval to assess the estimate of the fitted value for the observed values of the variables.
For example, with a 95% confidence level, you can be 95% confident that the confidence interval contains the population log standard deviation for the specified values of the predictor variables or factors in the model. The confidence interval helps you assess the practical significance of your results. Use your specialized knowledge to determine whether the confidence interval includes values that have practical significance for your situation. A wide confidence interval indicates that you can be less confident about the standard deviation of future values. If the interval is too wide to be useful, consider increasing your sample size.
Ln(Residual)
The difference between the natural log of the observed response standard deviation and the natural log of the fitted standard deviation. It is the log of the ratio residual.
Interpretation
The log residual represents the part of the observed response that is not explained by the model. Of the types of residuals Minitab calculates in Analyze Variability, the log residuals most closely resemble regular residuals.
Std Ln(Resid)
The standardized residuals for the natural log equals the log residual divided by its (asymptotic) standard error
Interpretation
Use the standardized residuals for the natural log to help you detect outliers. When the Std Ln(Resid) values are between −2 and 2, no unusual observations exist in the data.
Standardized residuals greater than 2 and less than −2 are usually considered large. The observations that Minitab labels do not follow the proposed regression equation well. However, it is expected that you will have some unusual observations. For example, based on the criteria for large standardized residuals, you would expect roughly 5% of your observations to be flagged as having a large standardized residual. For more information, go to Unusual observations.
Standardized residuals are useful because raw residuals might not be good indicators of outliers. The variance of each raw residual can differ by the x-values associated with it. This unequal variation causes it to be difficult to assess the magnitudes of the raw residuals. Standardizing the residuals solves this problem by converting the different variances to a common scale.
Hi (leverage)
Hi, also known as leverage, measures the distance from an observation's x-value to the average of the x-values for all observations in a data set.
Interpretation
Hi values fall between 0 and 1. Minitab identifies observations with leverage values greater than 3p/n or 0.99, whichever is smaller, with an X in the Fits and Diagnostics for Unusual Observations table. In 3p/n, p is the number of coefficients in the model, and n is the number of observations. The observations that Minitab labels with an 'X' may be influential.
Influential observations have a disproportionate effect on the model and can produce misleading results. For example, the inclusion or exclusion of an influential point can change whether a coefficient is statistically significant or not. Influential observations can be leverage points, outliers, or both.
If you see an influential observation, determine whether the observation is a data-entry or measurement error. If the observation is neither a data-entry error nor a measurement error, determine how influential an observation is. First, fit the model with and without the observation. Then, compare the coefficients, p-values, R2, and other model information. If the model changes significantly when you remove the influential observation, examine the model further to determine if you have incorrectly specified the model. You may need to gather more data to resolve the issue.
Cook's distance (D)
Cook's distance (D) measures the effect that an observation has on the set of coefficients in a linear model. Cook's distance considers both the leverage value and the standardized residual of each observation to determine the observation's effect.
Interpretation
Observations with a large D may be considered influential. A commonly used criterion for a large D-value is when D is greater than the median of the F-distribution: F(0.5, p, n-p), where p is the number of model terms, including the constant, and n is the number of observations. Another way to examine the D-values is to compare them to one another using a graph, such as an individual value plot. Observations with large D-values relative to the others may be influential.
Influential observations have a disproportionate effect on the model and can produce misleading results. For example, the inclusion or exclusion of an influential point can change whether a coefficient is statistically significant or not. Influential observations can be leverage points, outliers, or both.
If you see an influential observation, determine whether the observation is a data-entry or measurement error. If the observation is neither a data-entry error nor a measurement error, determine how influential an observation is. First, fit the model with and without the observation. Then, compare the coefficients, p-values, R2, and other model information. If the model changes significantly when you remove the influential observation, examine the model further to determine if you have incorrectly specified the model. You may need to gather more data to resolve the issue.
DFITS
DFITS measures the effect each observation has on the fitted values in a linear model. DFITS represents approximately the number of standard deviations that the fitted value changes when each observation is removed from the data set and the model is refit.
Interpretation
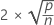
| Term | Description |
|---|---|
| p | the number of model terms |
| n | the number of observations |
If you see an influential observation, determine whether the observation is a data-entry or measurement error. If the observation is neither a data-entry error nor a measurement error, determine how influential an observation is. First, fit the model with and without the observation. Then, compare the coefficients, p-values, R2, and other model information. If the model changes significantly when you remove the influential observation, examine the model further to determine if you have incorrectly specified the model. You may need to gather more data to resolve the issue.