α (alpha)
The significance level (denoted as α or alpha) is the maximum acceptable level of risk for rejecting the null hypothesis when the null hypothesis is true (type I error). Alpha is also interpreted as the power of the test when the null hypothesis (H0) is true. Usually, you choose the significance level before you analyze the data. The default significance level is 0.05.
Interpretation
Use the significance level to minimize the power value of the test when the null hypothesis (H0) is true. Higher values for the significance level give the test more power, but also increase the chance of making a type I error, which is rejecting the null hypothesis when it is true.
Length of observation
The length of observation represents the magnitude, duration, or size of each observation period.
Interpretation
Use the length of observation to convert the rate of occurrence into a form that best suits your situation.
For example, if each sample observation counts the number of events in a year, a length of 1 would represent a yearly rate of occurrence while a length of 12 would represent a monthly rate of occurrence.
- For assembly line A, the total occurrences is 112, because they found 112 defects. It is 132 for assembly line B because they found 132 defects.
- The sample size (N) is 50 for both assembly lines because they sampled 50 boxes for each.
- To determine the number of defects per towel, inspectors use a length of observation of 10 for assembly line A because there are 10 towels per box. The length of observation is 15 for assembly line B.
- For assembly line A, the rate of occurrence is (Total occurrences / N) / (length of observation) = (112/50) / 10 = 0.224. For assembly line B, the rate of occurrence is (132/50) / 15 = 0.176. So on average, each towel has 0.244 defects from assembly line A and 0.176 defects from assembly line B.
- Because the inspectors enter a length of observation that is different than 1, Minitab also calculates the mean occurrence. For assembly line A, the mean occurrence is (Total occurrences / N) = 112/50 = 2.24. For assembly line B, the mean occurrence is 132/50 = 2.64. In other words, the mean occurrence describes the average number of defects per box. However, because the boxes had different amounts of towels, the rate of occurrence is more helpful.
Comparison Rate
The comparison rate is the value you want to compare to the baseline rate.
Interpretation
Minitab calculates the comparison rate. The difference between the comparison rate and the baseline rate is the minimum difference for which you can achieve the specified level of power for each sample size. Larger sample sizes enable the test to detect smaller differences. You want to detect the smallest difference that has practical consequences for your application.
To more fully investigate the relationship between the sample size and the comparison rate at a given power, use the power curve.
Sample Size
The sample size is the total number of observations in the sample.
Interpretation
Use the sample size to estimate how many observations you need to obtain a certain power value for the hypothesis test at a specific difference.
Minitab calculates how large your sample must be for a test with your specified power to detect the difference between the baseline rate and comparison rate. Because sample sizes are whole numbers, the actual power of the test might be slightly greater than the power value that you specify.
If you increase the sample size, the power of the test also increases. You want enough observations in your sample to achieve adequate power. But you don't want a sample size so large that you waste time and money on unnecessary sampling or detect unimportant differences to be statistically significant.
To more fully investigate the relationship between the sample size and the difference at a given power, use the power curve.
Power
The power of a hypothesis test is the probability that the test correctly rejects the null hypothesis. The power of a hypothesis test is affected by the sample size, the difference, the variability of the data, and the significance level of the test.
For more information, go to What is power?.
Interpretation
Minitab calculates the power of the test based on the specified comparison rate and sample size. A power value of 0.9 is usually considered adequate. A value of 0.9 indicates you have a 90% chance of detecting a difference between the population rates when a difference actually exists. If a test has low power, you might fail to detect a difference and mistakenly conclude that none exists. Usually, when the sample size is smaller or the difference is smaller, the test has less power to detect a difference.
If you enter a comparison rate and a power value for the test, then Minitab calculates how large your sample must be. Minitab also calculates the actual power of the test for that sample size. Because sample sizes are whole numbers, the actual power of the test might be slightly greater than the power value that you specify.
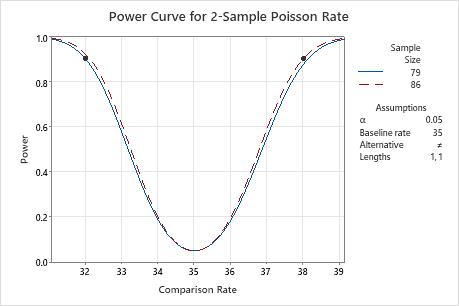
Power curve
The power curve plots the power of the test versus the comparison rate.
Interpretation
Use the power curve to assess the appropriate sample size or power for your test.
The power curve represents every combination of power and comparison rate for each sample size when the significance level is held constant. Each symbol on the power curve represents a calculated value based on the values that you enter. For example, if you enter a sample size and a power value, Minitab calculates the corresponding comparison proportion and displays the calculated value on the graph.
Examine the values on the curve to determine the difference between the comparison rate and the baseline rate that can be detected at a certain power value and sample size. A power value of 0.9 is usually considered adequate. However, some practitioners consider a power value of 0.8 to be adequate. If a hypothesis test has low power, you might fail to detect a difference that is practically significant. If you increase the sample size, the power of the test also increases. You want enough observations in your sample to achieve adequate power. But you don't want a sample size so large that you waste time and money on unnecessary sampling or detect unimportant differences to be statistically significant. If you decrease the size of the difference that you want to detect, the power also decreases.
In this graph, the power curve shows that to detect a comparison rate of 32 with a power of 0.9, the sample size needs to be 79. To detect a comparison rate of 38 with a power of 0.9, the sample size needs to be 86. As the comparison rate approaches the baseline rate (35, in this graph), the power of the test decreases and approaches α (also called the significance level), which is 0.05 for this analysis.