In This Topic
Components
The components represent the number of components included in each model. Minitab displays the model with 1 component, with 2 components, and so on, until it includes the number of components you specified. If you didn't specify the number of components to include in the model, Minitab shows the model selection statistics for 10 components, or the number of predictors, whichever is less.
X-variance
The x-variance is the amount of variance in the terms that is explained by the model. The x-variance value is between 0 and 1.
The closer the x-variance value is to 1, the better the components represent the original set of terms. If you have more than 1 response, the x-variance value is the same for all responses.
Error
The error is the error sum of squares, which is the sum of the squared residuals. It quantifies the variation in the data that the model does not explain. For the final model, the error matches the SS for residual error in the ANOVA table for the final model.
R-sq
R2 is the percentage of variation in the response that is explained by the model. It is calculated as 1 minus the ratio of the error sum of squares (which is the variation that is not explained by model) to the total sum of squares (which is the total variation in the model).
Interpretation
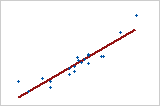
Use R2 to determine how well the model fits your data. The higher the R2 value, the better the model fits your data. R2 is always between 0% and 100%.
-
R2 always increases when you add additional predictors to a model. For example, the best five-predictor model will always have an R2 that is at least as high as the best four-predictor model. Therefore, R2 is most useful when you compare models of the same size.
-
Small samples do not provide a precise estimate of the strength of the relationship between the response and predictors. For example, if you need R2 to be more precise, you should use a larger sample (typically, 40 or more).
-
Goodness-of-fit statistics are just one measure of how well the model fits the data. Even when a model has a desirable value, you should check the residual plots to verify that the model meets the model assumptions.
R-sq (pred)
Predicted R2 indicates how well each calculated model predicts the response and is only calculated when you perform cross-validation. If one response variable is in the data, Minitab selects the PLS model with the highest predicted R2. If multiple response variables are in the data, Minitab selects the PLS model with the highest mean predicted R2 for all of the response variables. Predicted R2 is calculated by systematically removing each observation from the data set, estimating the regression equation, and determining how well the model predicts the removed observation. The value of predicted R2 ranges between 0% and 100%. (While the calculations for predicted R2 can produce negative values, Minitab displays zero for these cases.)
Interpretation
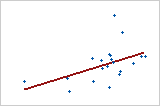
Use predicted R2 to determine how well your model predicts the response for new observations. Models that have larger predicted R2 values have better predictive ability.
A predicted R2 that is substantially less than R2 may indicate that the model is over-fit. An over-fit model occurs when you add terms for effects that are not important in the population. The model becomes tailored to the sample data and, therefore, may not be useful for making predictions about the population.
To determine the whether the model selected by cross-validation is most appropriate, examine the R2 and predicted R2 values. In some cases, you may decide to use a different model than the one selected by cross-validation. Consider an example where adding two components to the model that Minitab selects significantly increases R2 and only slightly decreases the predicted R2. Because the predicted R2 only decreased slightly, the model is not overfit and you may decide it better suits your data.
PRESS
The prediction error sum of squares (PRESS) is a measure of the deviation between the fitted values and the observed values. PRESS is similar to the sum of squares of the residual error (SSE), which is the summation of the squared residuals. However, PRESS uses a different calculation for the residuals. The formula used to calculate PRESS is equivalent to a process of systematically removing each observation from the data set, estimating the regression equation, and determining how well the model predicts the removed observation.
Interpretation
Use PRESS to assess your model's predictive ability. Usually, the smaller the PRESS value, the better the model's predictive ability. Minitab uses PRESS to calculate the predicted R2, which is usually more intuitive to interpret. Together, these statistics can prevent over-fitting the model. An over-fit model occurs when you add terms for effects that are not important in the population, although they may appear important in the sample data. The model becomes tailored to the sample data and therefore, may not be useful for making predictions about the population.