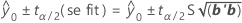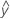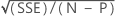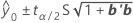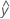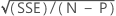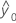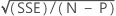The expected response for the nth observation at θ*:
Notation
Term
Description
θ*
the final iteration
xn
vector of values for the predictors at the nth observation
v0
gradient matrix = ( ∂f(xn, θ) / ∂θp ), the P by 1 vector of partial derivatives of f(x0, θ), evaluated at θ*
Confidence interval of the prediction
The range in which the mean response is expected to fall given specified settings of the predictors. An approximate 100(1 - α)% confidence interval for the prediction is:
Notation
Term
Description
tα/2
upper α/2 point of the t distribution with N – P degrees of freedom
se fit
standard error of the fit
n
nth observation
N
total number of observations
P
number of free (unlocked) parameters
fitted value
b
(R')-1v0
R
the (upper triangular) R matrix from the QR decomposition of Vi for the final iteration
v0
gradient matrix = ( ∂f(xn, θ) / ∂θp), the P by 1 vector of partial derivatives of f(x0, θ), evaluated at θ*
S
Prediction interval
The range in which the predicted response for a single new observation is expected to fall. A new observation has an approximate 100(1 - α)% prediction interval of:
Notation
Term
Description
tα/2
upper α/2 point of the t distribution with N – P degrees of freedom
se fit
standard error of the fit
n
nth observation
N
total number of observations
P
number of free (unlocked) parameters
fitted value
b
(R')-1v0
R
the (upper triangular) R matrix from the QR decomposition of Vi for the final iteration
v0
gradient matrix = ( ∂f(xn, θ) / ∂θp), the P by 1 vector of partial derivatives of f(x0, θ), evaluated at θ*
S
Standard error of the fitted value
The approximate standard error of the fitted value is:
where R is the (upper triangular) R matrix from the QR decomposition of Vi for the final iteration. Minitab computes:
by back-solving:
Notation
Term
Description
n
nth observation
N
total number of observations
P
number of free (unlocked) parameters
x0
vector of values for the predictors
f(x0, θ*)
v0
gradient matrix = ( ∂f(xn, θ) / ∂θp), the P by 1 vector of partial derivatives of f(x0, θ), evaluated at θ*