Fit
Fitted values are also called fits or 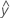 . The fitted values are point estimates of the mean response for given values of the predictors. The values of the predictors are also called x-values.
. The fitted values are point estimates of the mean response for given values of the predictors. The values of the predictors are also called x-values.
Interpretation
Fitted values are calculated by entering the specific x-values for each observation in the data set into the model equation.
For example, if the equation is y = 5 + 10x, the fitted value for the x-value, 2, is 25 (25 = 5 + 10(2)).
Observations with fitted values that are very different from the observed value may be unusual. Observations with unusual predictor values may be influential. If Minitab determines that your data include unusual or influential values, your output includes the table of Fits and Diagnostics for Unusual Observations, which identifies these observations. The unusual observations that Minitab labels do not follow the proposed regression equation well. However, it is expected that you will have some unusual observations. For example, based on the criteria for large standardized residuals, you would expect roughly 5% of your observations to be flagged as having a large standardized residual. For more information on unusual values, go to Unusual observations.
SE Fit
The standard error of the fit (SE fit) estimates the variation in the estimated mean response for the specified variable settings. The calculation of the confidence interval for the mean response uses the standard error of the fit. Standard errors are always non-negative.
Interpretation
Use the standard error of the fit to measure the precision of the estimate of the mean response. The smaller the standard error, the more precise the predicted mean response. For example, an analyst develops a model to predict delivery time. For one set of variable settings, the model predicts a mean delivery time of 3.80 days. The standard error of the fit for these settings is 0.08 days. For a second set of variable settings, the model produces the same mean delivery time with a standard error of the fit of 0.02 days. The analyst can be more confident that the mean delivery time for the second set of variable settings is close to 3.80 days.
With the fitted value, you can use the standard error of the fit to create a confidence interval for the mean response. For example, depending on the number of degrees of freedom, a 95% confidence interval extends approximately two standard errors above and below the predicted mean. For the delivery times, the 95% confidence interval for the predicted mean of 3.80 days when the standard error is 0.08 is (3.64, 3.96) days. You can be 95% confident that the population mean is within this range. When the standard error is 0.02, the 95% confidence interval is (3.76, 3.84) days. The confidence interval for the second set of variable settings is narrower because the standard error is smaller.
95% CI
The confidence interval for the fit provides a range of likely values for the mean response given the specified settings of the predictors.
Interpretation
Use the confidence interval to assess the estimate of the fitted value for the observed values of the variables.
For example, with a 95% confidence level, you can be 95% confident that the confidence interval contains the population mean for the specified values of the variables in the model. The confidence interval helps you assess the practical significance of your results. Use your specialized knowledge to determine whether the confidence interval includes values that have practical significance for your situation. A wide confidence interval indicates that you can be less confident about the mean of future values. If the interval is too wide to be useful, consider increasing your sample size.
95% PI
The prediction interval is a range that is likely to contain a single future response for a value of the predictor variable given the specified settings of the predictors.
Interpretation
For example, a materials engineer at a furniture manufacturer develops a simple regression model to predict the stiffness of particleboard from the density of the board. The engineer verifies that the model meets the assumptions of the analysis. Then, the analyst uses the model to predict the stiffness.
The regression equation predicts that the stiffness for a new observation will be 66.995 and the prediction interval is [50, 85]. While it is unlikely that the observation would have a stiffness of exactly 66.995, the prediction interval indicates that the engineer can be 95% confident that the actual value will be between 50 and 85.
The prediction interval is always wider than the corresponding confidence interval because predicting a single response is more uncertain than predicting the mean of multiple responses.