Note
This command is available with the Predictive Analytics Module. Click here for more information about how to activate the module.
After the creation of a model with Discover Best Model (Continuous Response), you can click Select an Alternative Model to explore other models. If you select a Random Forests ® model, one option is to specify hyperparameters to fit new models. If you specify hyperparameters, then the results include the Optimization of Hyperparameters table. The table compares the combinations of hyperparameters. The results that follow the Optimization of Hyperparameters table are for the model with the best value of the optimality criterion, such as the maximum R2.
R-squared
R2 is the percentage of variation in the response that the model explains.
Interpretation
Use R2 to determine how well the model fits your data. The higher the R2 value, the better the model fits your data. R2 is always between 0% and 100%.
Note
Because Random Forests® use out-of-bag data to calculate R2, but not to fit the model, overfitting of the model is not a concern.
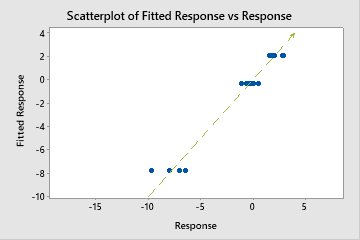
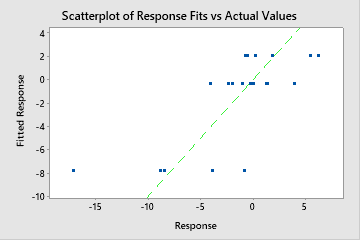
Mean absolute deviation (MAD)
The mean absolute deviation (MAD) expresses accuracy in the same units as the data, which helps conceptualize the amount of error. Outliers have less of an effect on MAD than on R2.
Interpretation
Use to compare the fits of different models. Smaller values indicate a better fit.
Predictor count for node splitting
This row indicates the choice for the number of predictors to consider.
Minimum internal node size
The minimum internal node size indicates the minimum number of cases a node can have and still split into more nodes.
Number of bootstrap samples
The number of bootstrap samples indicates the number of trees in the analysis.