In This Topic
DF
The total degrees of freedom (DF) are the amount of information in your data. The analysis uses that information to estimate the values of unknown population parameters. The total DF is determined by the number of observations in your sample. The DF for a term show how much information that term uses. Increasing your sample size provides more information about the population, which increases the total DF. Increasing the number of terms in your model uses more information, which decreases the DF available to estimate the variability of the parameter estimates.
- DF for curvature
- If a design has center points, then one DF is for the test for curvature. If the term for center points is in the model, the row for curvature is part of the model. If the term for center points is not in the model, the row for curvature is part of the error that is used to test terms that are in the model.
- DF for error
- If two conditions are met, then Minitab partitions the DF for error that are not for curvature. The first condition is that there must be terms that you can fit with the data that are not in the current model. For example, if you the design has blocks but the blocks are not in the model. The center point term is always for curvature, so the center point term does not count as a term that you can fit with the data that is not in the current model.
Adj SS
Adjusted sums of squares are measures of variation for different components of the model. The order of the predictors in the model does not affect the calculation of the adjusted sums of squares. In the Analysis of Variance table, Minitab separates the sums of squares into different components that describe the variation due to different sources.
- Adj SS Model
- The adjusted sum of squares for the model is the difference between the total sum of square and the error sum of squares in the model compared to a model that uses only the mean of the response. It is the sum of all the sequential sums of squares for terms in the model.
- Adj SS groups of terms
- The adjusted sum of squares for a group of terms in the model is the sum of the sequential sum of squares for all of the terms in the group. It quantifies the amount of variation in the response data that the group of terms explains.
- Adj SS term
- The adjusted sum of squares for a term is the increase in the model sum of squares compared to a model with only the other terms. It quantifies the amount of variation in the response data that each term in the model explains.
- Adj SS Error
- The adjusted error sum of squares is the sum of the squared residuals. It quantifies the variation in the data that the predictors do not explain.
- Adj SS Curvature
- The adjusted sum of squares for curvature can be part of the model sum of squares or part of the error sum of squares. It quantifies the amount of variation in the response data explained by the center point term. This variation represents the combined effect of one or more quadratic terms.
- Adj SS Pure Error
- The adjusted pure error sum of squares is part of the error sum of squares. The pure error sum of squares exists when the degrees of freedom for pure error exist. For more information, go to the section on Degrees of Freedom (DF). It quantifies the variation in the data for observations with the same values of the factors, blocks, and covariates.
- Adj SS Total
- The adjusted total sum of squares is the sum of the model sum of squares and the error sum of squares. It quantifies the total variation in the data.
Interpretation
Minitab uses the adjusted sums of squares to calculate the p-values in the ANOVA table. Minitab also uses the sums of squares to calculate the R2 statistic. Usually, you interpret the p-values and the R2 statistic instead of the sums of squares.
Adj MS
Adjusted mean squares measure how much variation a term or a model explains, assuming that all other terms are in the model, regardless of their order in the model. Unlike the adjusted sums of squares, the adjusted mean squares consider the degrees of freedom.
The adjusted mean square of the error (also called MSE or s2) is the variance around the fitted values.
Interpretation
Minitab uses the adjusted mean squares to calculate the p-values in the ANOVA table. Minitab also uses the adjusted mean squares to calculate the adjusted R2 statistic. Usually, you interpret the p-values and the adjusted R2 statistic instead of the adjusted mean squares.
Seq SS
Sequential sums of squares are measures of variation for different components of the model. Unlike the adjusted sums of squares, the sequential sums of squares depend on the order that the terms are in the model. In the Analysis of Variance table, Minitab separates the sequential sums of squares into different components that describe the variation due to different sources.
- Seq SS Model
- The sequential sum of squares for the model is difference between the total sum of square and the error sum of squares. It is the sum of all of the sums of squares for terms in the model.
- Seq SS groups of terms
- The sequential sum of squares for a group of terms in the model is the sum of the sums of squares for all of the terms in the group. It quantifies the amount of variation in the response data that the group of terms explains.
- Seq SS term
- The sequential sum of squares for a term is the increase in the model sum of squares compared to a model with only the terms above it in the ANOVA table. It quantifies the increase in the model sum of squares when that term is added to a model with the terms above it.
- Seq SS Error
- The sequential error sum of squares is the sum of the squared residuals. It quantifies the variation in the data that the predictors do not explain.
- Seq SS Curvature
- The sequential sum of squares for curvature can be part of the model sum of squares or part of the error sum of squares. It quantifies the amount of variation in the response data explained by the center point term. This variation represents the combined effect of one or more quadratic terms.
- Seq SS Pure Error
- The sequential pure error sum of squares is part of the error sum of squares. The pure error sum of squares exists when the degrees of freedom for pure error exist. For more information, go to the section on Degrees of Freedom (DF). It quantifies the variation in the data for observations with the same values of the factors, blocks, and covariates.
- Seq SS Total
- The sequential total sum of squares is the sum of the model sum of squares and the error sum of squares. It quantifies the total variation in the data.
Interpretation
Minitab does not use the sequential sums of squares to calculate p-values when you analyze a design, but can use the sequential sums of squares when you use Fit Regression Model or Fit General Linear Model. Usually, you interpret the p-values and the R2 statistic based on the adjusted sums of squares.
Contribution
Contribution displays the percentage that each source in the Analysis of Variance table contributes to the total sequential sums of squares (Seq SS).
Interpretation
Higher percentages indicate that the source accounts for more of the variation in the response.
F-value
An F-value appears for each test in the analysis of variance table.
- F-value for the model
- The F-value is the test statistic used to determine whether any term in the model is associated with the response, including covariates, blocks, factor terms, and curvature.
- F-value for covariates as a group
- The F-value is the test statistic used to determine whether any of the covariates are associated with the response simultaneously.
- F-value for individual covariates
- The F-value is the test statistic used to determine whether an individual covariate is associated the response.
- F-value for blocks
- The F-value is the test statistic used to determine whether different conditions among blocks are associated with the response.
- F-value for types of factor terms
- The F-value is the test statistic used to determine whether a group of terms is associated with the response. Examples of groups of terms are linear effects and 2-way interactions.
- F-value for individual terms
- The F-value is the test statistic used to determine whether the term is associated with the response.
- F-value for curvature
- The F-value is the test statistic used to determine whether any of the factors have a curved relationship with the response.
- F-value for the lack-of-fit test
- The F-value is the test statistic used to determine whether the model is missing terms that include the factors in the experiment. If blocks or covariates are removed from the model by a stepwise procedure, then the lack-of-fit test includes these terms also.
Interpretation
Minitab uses the F-value to calculate the p-value, which you use to make a decision about the statistical significance of the test. The p-value is a probability that measures the evidence against the null hypothesis. Lower probabilities provide stronger evidence against the null hypothesis. A sufficiently large F-value indicates statistical significance.
If you want to use the F-value to determine whether to reject the null hypothesis, compare the F-value to your critical value. You can calculate the critical value in Minitab or find the critical value from an F-distribution table in most statistics books. For more information on using Minitab to calculate the critical value, go to Using the inverse cumulative distribution function (ICDF) and click "Use the ICDF to calculate critical values".
P-Value – Model
The p-value is a probability that measures the evidence against the null hypothesis. Lower probabilities provide stronger evidence against the null hypothesis.
Interpretation
To determine whether the model explains variation in the response, compare the p-value for the model to your significance level to assess the null hypothesis. The null hypothesis for the model is that the model does not explain any of the variation in the response. Usually, a significance level (denoted as α or alpha) of 0.05 works well. A significance level of 0.05 indicates a 5% risk of concluding that the model explains variation in the response when the model does not.
- P-value ≤ α: The model explains variation in the response
- If the p-value is less than or equal to the significance level, you conclude that the model explains variation in the response.
- P-value > α: There is not enough evidence to conclude that the model explains variation in the response
- If the p-value is greater than the significance level, you cannot conclude that the model explains variation in the response. You may want to fit a new model.
P-value – Covariates
The p-value is a probability that measures the evidence against the null hypothesis. Lower probabilities provide stronger evidence against the null hypothesis.
In a designed experiment, covariates account for variables that are measurable, but difficult to control. For example, members of a quality team at a hospital network design an experiment to study length of stay for patients admitted for total knee replacement surgery. For the experiment, the team can control factors like the format of pre-surgical instructions. To avoid bias, the team records data on covariates that they cannot control, such as the age of the patient.
Interpretation
To determine whether the association between the response and a covariate is statistically significant, compare the p-value for the covariate to your significance level to assess the null hypothesis. The null hypothesis is that the coefficient for the covariate is zero, which implies that there is no association between the covariate and the response.
Usually, a significance level (denoted as α or alpha) of 0.05 works well. A significance level of 0.05 indicates a 5% risk of concluding that different conditions between runs change the response when the conditions do not.
When you assess the statistical significance of terms for a model with covariates, consider the variance inflation factors (VIFs).
- P-value ≤ α: The association is statistically significant
- If the p-value is less than or equal to the significance level, you conclude that the association between the response and the covariate is statistically significant.
- P-value > α: The association is not statistically significant
- If the p-value is greater than the significance level, you cannot conclude that the association between the response and the covariate is statistically significant. You may want to fit a model without the covariate.
Note
All the VIF values are 1 in most factorial designs, which simplifies the determination of statistical significance. The inclusion of covariates in the model and the occurrence of botched runs during data collection are two common ways that VIF values increase, which complicates the interpretation of statistical significance. VIF values are in the Coefficients table. For more information, go to Coefficients table for Analyze Factorial Design and click VIF.
P-value – Blocks
The p-value is a probability that measures the evidence against the null hypothesis. Lower probabilities provide stronger evidence against the null hypothesis.
Blocks account for the differences that might occur between runs that are performed under different conditions. For example, an engineer designs an experiment to study welding and cannot collect all of the data on the same day. Weld quality is affected by several variables that change from day-to-day that the engineer cannot control, such as relative humidity. To account for these uncontrollable variables, the engineer groups the runs performed each day into separate blocks. The blocks account for the variation from the uncontrollable variables so that these effects are not confused with the effects of the factors the engineer wants to study. For more information on how Minitab assigns runs to blocks, go to What is a block?.
Interpretation
To determine whether different conditions between runs change the response, compare the p-value for the blocks to your significance level to assess the null hypothesis. The null hypothesis is that different conditions do not change the response.
Usually, a significance level (denoted as α or alpha) of 0.05 works well. A significance level of 0.05 indicates a 5% risk of concluding that different conditions between runs change the response when the conditions do not.
- P-value ≤ α: The different conditions change the response
- If the p-value is less than or equal to the significance level, you conclude that the different conditions change the response.
- P-value > α: There is not enough evidence to conclude that the different conditions change the response
- If the p-value is greater than the significance level, you cannot conclude that the different conditions change the response. You may want to fit a model without blocks.
P-Value – Factors, interactions, and groups of terms
The p-value is a probability that measures the evidence against the null hypothesis. Lower probabilities provide stronger evidence against the null hypothesis.
Interpretation
- If a covariate is significant, you can conclude that the coefficient for the covariate does not equal zero.
- If a categorical factor is significant, you can conclude that not all the level means are equal.
- If an interaction term is significant, you can conclude that the relationship between a factor and the response depends on the other factors in the term.
Tests of groups of terms
If a group of terms is statistically significant, then you can conclude that at least one of the terms in the group has an effect on the response. When you use statistical significance to decide which terms to keep in a model, you usually do not remove entire groups of terms at the same time. The statistical significance of individual terms can change because of the terms in the model.
Analysis of Variance
| Source | DF | Adj SS | Adj MS | F-Value | P-Value |
|---|---|---|---|---|---|
| Model | 10 | 447.766 | 44.777 | 17.61 | 0.003 |
| Linear | 4 | 428.937 | 107.234 | 42.18 | 0.000 |
| Material | 1 | 181.151 | 181.151 | 71.25 | 0.000 |
| InjPress | 1 | 112.648 | 112.648 | 44.31 | 0.001 |
| InjTemp | 1 | 73.725 | 73.725 | 29.00 | 0.003 |
| CoolTemp | 1 | 61.412 | 61.412 | 24.15 | 0.004 |
| 2-Way Interactions | 6 | 18.828 | 3.138 | 1.23 | 0.418 |
| Material*InjPress | 1 | 0.342 | 0.342 | 0.13 | 0.729 |
| Material*InjTemp | 1 | 0.778 | 0.778 | 0.31 | 0.604 |
| Material*CoolTemp | 1 | 4.565 | 4.565 | 1.80 | 0.238 |
| InjPress*InjTemp | 1 | 0.002 | 0.002 | 0.00 | 0.978 |
| InjPress*CoolTemp | 1 | 0.039 | 0.039 | 0.02 | 0.906 |
| InjTemp*CoolTemp | 1 | 13.101 | 13.101 | 5.15 | 0.072 |
| Error | 5 | 12.712 | 2.542 | ||
| Total | 15 | 460.478 |
In this model, the test for the two-way interactions is not statistically significant at the 0.05 level. Also, the tests for all the 2-way interactions are not statistically significant.
Analysis of Variance
| Source | DF | Adj SS | Adj MS | F-Value | P-Value |
|---|---|---|---|---|---|
| Model | 5 | 442.04 | 88.408 | 47.95 | 0.000 |
| Linear | 4 | 428.94 | 107.234 | 58.16 | 0.000 |
| Material | 1 | 181.15 | 181.151 | 98.24 | 0.000 |
| InjPress | 1 | 112.65 | 112.648 | 61.09 | 0.000 |
| InjTemp | 1 | 73.73 | 73.725 | 39.98 | 0.000 |
| CoolTemp | 1 | 61.41 | 61.412 | 33.31 | 0.000 |
| 2-Way Interactions | 1 | 13.10 | 13.101 | 7.11 | 0.024 |
| InjTemp*CoolTemp | 1 | 13.10 | 13.101 | 7.11 | 0.024 |
| Error | 10 | 18.44 | 1.844 | ||
| Total | 15 | 460.48 |
If you reduce the model one term at a time, beginning with the 2-way interaction with the highest p-value, then the last 2-way interaction is statistically significant at the 0.05 level.
P-value – Curvature
The p-value is a probability that measures the evidence against the null hypothesis. Lower probabilities provide stronger evidence against the null hypothesis.
Minitab tests for curvature when the design has center points. The test looks at the fitted mean of the response at the center points relative to the expected mean if the relationships between the model terms and the response are linear. To visualize the curvature, use factorial plots.
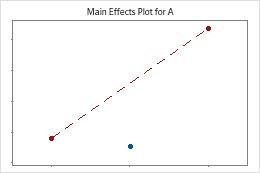
The center points are far away from the line that joins the means of the corner points, which suggests a curved relationship. Use the p-value to verify that the curvature is statistically significant.
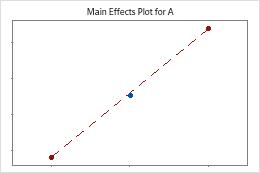
The center points are near the line that joins the means of the corner points. The curvature is probably not statistically significant.
Interpretation
To determine whether at least one of the factors have a curved relationship with the response, compare the p-value for curvature to your significance level to assess the null hypothesis. The null hypothesis is that all the relationships between the factors and the response are linear.
Usually, a significance level (denoted as α or alpha) of 0.05 works well. A significance level of 0.05 indicates a 5% risk of concluding that different conditions between runs change the response when the conditions do not.
- P-value ≤ α: At least one factor has a curved relationship with the response
- If the p-value is less than or equal to the significance level, you conclude that at least one of the factors has a curved relationship with the response. You may want to add axial points to the design so that you can model the curvature.
- P-value > α: There is not enough evidence to conclude that any factors have a curved relationship with the response
- If the p-value is greater than the significance level, you cannot conclude that any of the factors have a curved relationship with the response. If the curvature is part of the model, you may want to refit the model without a term for center points so that the curvature is part of the error.
Note
Usually, if the curvature is not statistically significant, you remove the center point term. If you leave the center points in the model, Minitab assumes that the model contains curvature that the factorial design cannot fit. Due to the inadequate fit, Contour Plot, Surface Plot, and Overlaid Contour Plot are not available. Also, Minitab does not interpolate between the factor levels in the design with Response Optimizer. For more information on ways to use the model, go to Stored model overview.
P-value – Lack-of-fit
The p-value is a probability that measures the evidence against the null hypothesis. Lower probabilities provide stronger evidence against the null hypothesis.
Interpretation
- P-value ≤ α: The lack-of-fit is statistically significant
- If the p-value is less than or equal to the significance level, you conclude that the model does not correctly specify the relationship. To improve the model, you may need to add terms or transform your data.
- P-value > α: The lack-of-fit is not statistically significant
-
If the p-value is larger than the significance level, the test does not detect any lack-of-fit.