In This Topic
S
S represents the standard deviation of the distance between the data values and the fitted values. S is measured in the units of the response.
Interpretation
Use S to assess how well the model describes the response. S is measured in the units of the response variable and represents how far the data values fall from the fitted values. The lower the value of S, the better the model describes the response. However, a low S value by itself does not indicate that the model meets the model assumptions. You should check the residual plots to verify the assumptions.
For example, you work for a potato chip company that examines the factors that affect the percentage of crumbled potato chips per container. You reduce the model to the significant predictors, and S is calculated as 1.79. This result indicates that the standard deviation of the data points around the fitted values is 1.79. If you are comparing models, values that are lower than 1.79 indicate a better fit, and higher values indicate a worse fit.
R-sq
R2 is the percentage of variation in the response that is explained by the model. It is calculated as 1 minus the ratio of the error sum of squares (which is the variation that is not explained by model) to the total sum of squares (which is the total variation in the model).
Interpretation
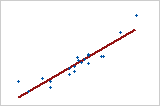
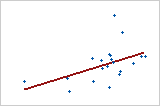
Use R2 to determine how well the model fits your data. The higher the R2 value, the better the model fits your data. R2 is always between 0% and 100%.
-
R2 always increases when you add additional predictors to a model. For example, the best five-predictor model will always have an R2 that is at least as high as the best four-predictor model. Therefore, R2 is most useful when you compare models of the same size.
-
Small samples do not provide a precise estimate of the strength of the relationship between the response and predictors. For example, if you need R2 to be more precise, you should use a larger sample (typically, 40 or more).
-
Goodness-of-fit statistics are just one measure of how well the model fits the data. Even when a model has a desirable value, you should check the residual plots to verify that the model meets the model assumptions.
R-sq (adj)
Adjusted R2 is the percentage of the variation in the response that is explained by the model, adjusted for the number of predictors in the model relative to the number of observations. Adjusted R2 is calculated as 1 minus the ratio of the mean square error (MSE) to the mean square total (MS Total).
Interpretation
Use adjusted R2 when you want to compare models that have different numbers of predictors. R2 always increases when you add a predictor to the model, even when there is no real improvement to the model. The adjusted R2 value incorporates the number of predictors in the model to help you choose the correct model.
| Model | % Potato | Cooling rate | Cooking temp | R2 | Adjusted R2 |
|---|---|---|---|---|---|
| 1 | X | 52% | 51% | ||
| 2 | X | X | 63% | 62% | |
| 3 | X | X | X | 65% | 62% |
The first model yields an R2 of more than 50%. The second model adds cooling rate to the model. Adjusted R2 increases, which indicates that cooling rate improves the model. The third model, which adds cooking temperature, increases the R2 but not the adjusted R2. These results indicate that cooking temperature does not improve the model. Based on these results, you consider removing cooking temperature from the model.
PRESS
The prediction error sum of squares (PRESS) is a measure of the deviation between the fitted values and the observed values. PRESS is similar to the sum of squares of the residual error (SSE), which is the summation of the squared residuals. However, PRESS uses a different calculation for the residuals. The formula used to calculate PRESS is equivalent to a process of systematically removing each observation from the data set, estimating the regression equation, and determining how well the model predicts the removed observation.
Interpretation
Use PRESS to assess your model's predictive ability. Usually, the smaller the PRESS value, the better the model's predictive ability. Minitab uses PRESS to calculate the predicted R2, which is usually more intuitive to interpret. Together, these statistics can prevent over-fitting the model. An over-fit model occurs when you add terms for effects that are not important in the population, although they may appear important in the sample data. The model becomes tailored to the sample data and therefore, may not be useful for making predictions about the population.
R-sq (pred)
Predicted R2 is calculated with a formula that is equivalent to systematically removing each observation from the data set, estimating the regression equation, and determining how well the model predicts the removed observation. The value of predicted R2 ranges between 0% and 100%. (While the calculations for predicted R2 can produce negative values, Minitab displays zero for these cases.)
Interpretation
Use predicted R2 to determine how well your model predicts the response for new observations. Models that have larger predicted R2 values have better predictive ability.
A predicted R2 that is substantially less than R2 may indicate that the model is over-fit. An over-fit model occurs when you add terms for effects that are not important in the population. The model becomes tailored to the sample data and, therefore, may not be useful for making predictions about the population.
Predicted R2 can also be more useful than adjusted R2 for comparing models because it is calculated with observations that are not included in the model calculation.
For example, an analyst at a financial consulting company develops a model to predict future market conditions. The model looks promising because it has an R2 of 87%. However, the predicted R2 is 52%, which indicates that the model may be over-fit.