A posterior probability is the probability of assigning observations to groups given the data. A prior probability is the probability that an observation will fall into a group before you collect the data. For example, if you are classifying the buyers of a specific car, you might already know that 60% of purchasers are male and 40% are female. If you know or can estimate these probabilities, a discriminant analysis can use these prior probabilities in calculating the posterior probabilities. When you don't specify prior probabilities, Minitab assumes that the groups are equally likely.
With the assumption that the data have a normal distribution, the linear discriminant function is increased by ln(pi), where pi is the prior probability of group i. Because observations are assigned to groups by the smallest generalized distance, or equivalently the largest linear discriminant function, the effect is to increase the posterior probabilities for a group with a high prior probability.
Note
Specifying prior probabilities can greatly affect the accuracy of your results. Investigate whether the unequal proportions across groups show a real difference in the true population or whether the difference is a result of sampling error.
Now suppose there are prior probabilities and suppose fi(x) is the joint density for the data in group i (with the population parameters replaced by the sample estimates).
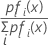
The largest posterior probability is equivalent to the largest value of ln [pifi(x)]
If fi(x) is the normal distribution, then:
ln [pifi(x)] = -0.5 [di2(x) – 2 ln pi] – (a constant)
The term in square brackets is called the generalized squared distance of x to group i and is denoted by di2(x). Notice,
di2(x) = -2[mi' Sp-1 x - 0.5 mi' Sp-1mi + ln pi] + x' Sp-1x
The term in square brackets is the linear discriminant function. The only difference from the case without prior probabilities is a change in the constant term. Notice, the largest posterior is equivalent to the smallest generalized distance, which is equivalent to the largest linear discriminant function.