In diesem Thema
A-Quadrat
Mit der Anderson-Darling-Statistik für die Güte der Anpassung (A-Quadrat) wird die Fläche zwischen der Anpassungslinie (die auf der Normalverteilung basiert) und der empirischen Verteilungsfunktion (die auf den Datenpunkten basiert) gemessen. Die Anderson-Darling-Statistik ist eine quadrierte Distanz, die in den Randbereichen der Verteilung stärker gewichtet ist.
Interpretation
Minitab verwendet die Anderson-Darling-Statistik, um den p-Wert zu berechnen. Der p-Wert ist ein Wahrscheinlichkeitsmaß für die Anzeichen gegen die Annahme der Nullhypothese. Ein kleinerer p-Wert liefert stärkere Anzeichen dafür, dass die Nullhypothese nicht zutrifft. Ein kleinerer Wert der Anderson-Darling-Statistik gibt an, dass die Daten der Normalverteilung enger folgen.
p-Wert
Der p-Wert ist ein Wahrscheinlichkeitsmaß für die Anzeichen gegen die Annahme der Nullhypothese. Ein kleinerer p-Wert liefert stärkere Anzeichen dafür, dass die Nullhypothese nicht zutrifft.
Interpretation
Verwenden Sie den p-Wert, um zu ermitteln, ob die Daten keiner Normalverteilung folgen.
- p-Wert ≤ α: Die Daten folgen keiner Normalverteilung (H0 verwerfen)
- Wenn der p-Wert kleiner oder gleich dem Signifikanzniveau ist, weisen Sie die Nullhypothese zurück und schlussfolgern, dass die Daten keiner Normalverteilung folgen.
- p-Wert > α: Es kann nicht gefolgert werden, dass die Daten keiner Normalverteilung folgen (H0 nicht verwerfen)
- Wenn der p-Wert größer als das Signifikanzniveau ist, weisen Sie die Nullhypothese nicht zurück. Es liegen nicht genügend Anzeichen für die Schlussfolgerung vor, dass die Daten keiner Normalverteilung folgen.
Mittelwert
Der Mittelwert ist der Durchschnitt der Daten; hierbei handelt es sich um die Summe aller Beobachtungen dividiert durch die Anzahl der Beobachtungen.
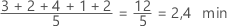
Interpretation
Verwenden Sie den Mittelwert, um die Stichprobe mit einem einzelnen Wert zu beschreiben, der das Zentrum der Daten darstellt. In vielen statistischen Analysen wird der Mittelwert als Standardmaß für die Lage der Datenverteilung verwendet.
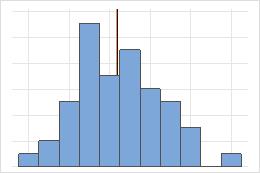
Symmetrisch
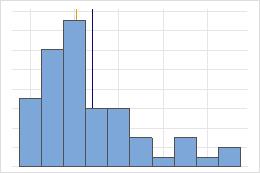
Nicht symmetrisch
Bei der symmetrischen Verteilung ähneln sich der Mittelwert (blaue Linie) und der Median (orangefarbene Linie) so sehr, dass die Linien nicht ohne weiteres unterschieden werden können. Die nicht symmetrische Verteilung ist jedoch rechtsschief.
StdAbw
Die Standardabweichung ist das am häufigsten verwendete Maß für die Streuung bzw. die Streubreite der Daten um den Mittelwert. Die Standardabweichung einer Grundgesamtheit wird häufig mit dem Zeichen σ (Sigma) angegeben, während mit s die Standardabweichung einer Stichprobe dargestellt wird. Eine zufällige oder natürliche Streuung eines Prozesses wird häufig auch als Rauschen bezeichnet.
Da die Standardabweichung in der gleichen Einheit wie die Daten angegeben wird, lässt sie sich in der Regel einfacher als die Varianz interpretieren.
Interpretation
Verwenden Sie die Standardabweichung, um die Streubreite der Daten um den Mittelwert zu ermitteln. Ein höherer Wert der Standardabweichung verweist auf eine größere Streubreite der Daten. Eine Faustregel für die Normalverteilung besagt, dass etwa 68 % der Werte innerhalb einer Standardabweichung vom Mittelwert, 95 % der Werte innerhalb zwei Standardabweichungen und 99,7 % der Werte innerhalb drei Standardabweichungen liegen.

Krankenhaus 1
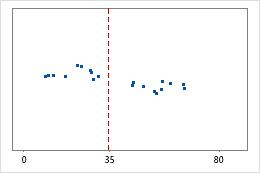
Krankenhaus 2
Zeit bis zur Entlassung in Krankenhäusern
Verwaltungsangestellte zeichnen die Zeit bis zur Entlassung von Patienten auf, die in der Notaufnahme zweier Krankenhäuser behandelt werden. Obwohl die durchschnittliche Zeit bis zur Entlassung in etwa identisch ist (35 Minuten), weichen die Standardabweichungen signifikant voneinander ab. Die Standardabweichung für Krankenhaus 1 beträgt etwa 6. Im Durchschnitt weicht die Zeit bis zur Entlassung eines Patienten um etwa 6 Minuten vom Mittelwert (gestrichelte Linie) ab. Die Standardabweichung für Krankenhaus 2 beträgt etwa 20. Im Durchschnitt weicht die Zeit bis zur Entlassung eines Patienten um ca. 20 Minuten vom Mittelwert (gestrichelte Linie) ab.
Varianz
Die Varianz ist ein Maß der Streuung der Daten um ihren Mittelpunkt. Die Varianz ist gleich dem Quadrat der Standardabweichung.
Interpretation
Je größer die Varianz, desto größer ist die Streubreite der Daten.
Da die Varianz (σ2) einen quadrierten Betrag darstellt, sind ihre Einheiten ebenfalls quadriert, was ihre praktische Verwendung möglicherweise erschwert. Die Standardabweichung lässt sich in der Regel einfacher interpretieren, da sie in den gleichen Einheiten wie die Daten vorliegt. Angenommen, eine Stichprobe von Wartezeiten an einer Bushaltestelle weist einen Mittelwert von 15 Minuten und eine Varianz von 9 min2 auf. Da die Varianz nicht in der gleichen Einheit wie die Daten angegeben wird, wird sie oft mit ihrer Quadratwurzel angezeigt, der Standardabweichung. Eine Varianz von 9 Minuten2 entspricht einer Standardabweichung von 3 Minuten.
Schiefe
Die Schiefe gibt das Ausmaß an, in dem die Daten asymmetrisch sind.
Interpretation
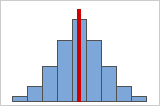
Abbildung A
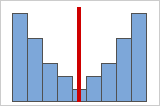
Abbildung B
Symmetrische oder nicht schiefe Verteilungen
Mit zunehmender Symmetrie der Daten nähert sich deren Schiefewert null an. Abbildung A zeigt normalverteilte Daten, die per definitionem eine relativ geringe Schiefe aufweisen. Wenn Sie eine Linie durch die Mitte dieses Histogramms von normalverteilten Daten zeichnen, wird ersichtlich, dass die beiden Seiten einander spiegeln. Eine fehlende Schiefe allein impliziert jedoch keine Normalverteilung. Abbildung B zeigt eine Verteilung, bei der beide Seiten einander immer noch spiegeln, die Daten jedoch keineswegs normalverteilt sind.
Positiv schiefe oder rechtsschiefe Verteilungen
Positiv schiefe oder rechtsschief verteilte Daten werden so bezeichnet, weil der Randbereich der Verteilung nach rechts zeigt und der Schiefewert größer als 0 (d. h. positiv) ist. Gehaltsdaten weisen häufig eine solche Schiefe auf: Viele Mitarbeiter eines Unternehmens erhalten ein relativ kleines Gehalt, während zunehmend weniger Personen sehr hohe Gehälter beziehen.
Negativ schiefe oder linksschiefe Verteilungen
Linksschiefe oder negativ schiefe Daten werden so bezeichnet, weil der Randbereich der Verteilung nach links weist und ein negativer Schiefewert vorliegt. Daten zu Ausfallraten sind häufig linksschief. Ein Beispiel sind Glühlampen: Sehr wenige brennen sofort durch, und die überwiegende Mehrzahl weist eine lange Lebensdauer auf.
Kurtosis
Die Kurtosis gibt an, wie weit die Randbereiche einer Verteilung von der Normalverteilung abweichen.
Interpretation
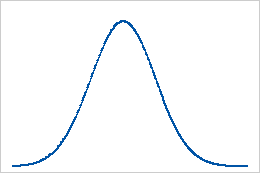
Basislinie: Kurtosis-Wert 0
Normalverteilte Daten bilden die Basislinie für die Kurtosis. Der Kurtosis-Wert 0 gibt an, dass die Daten der Normalverteilung perfekt folgen. Wenn ein Kurtosis-Wert wesentlich von 0 abweicht, kann dies darauf hinweisen, dass die Daten nicht normalverteilt sind.

Positive Kurtosis
Ein positiver Kurtosis-Wert für eine Verteilung deutet darauf hin, dass sich die Verteilung durch stärker ausgeprägte Randbereiche als die Normalverteilung auszeichnet. Daten, die einer t-Verteilung folgen, weisen beispielsweise einen positiven Kurtosis-Wert auf. Die durchgezogene Linie stellt die Normalverteilung und die gepunktete Linie eine Verteilung mit einem positiven Kurtosis-Wert dar.
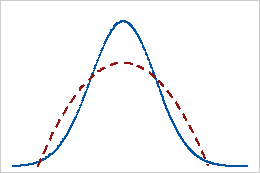
Negative Kurtosis
Ein negativer Kurtosis-Wert für eine Verteilung deutet darauf hin, dass sich die Verteilung durch schwächer ausgeprägte Randbereiche als die Normalverteilung auszeichnet. Daten, die einer Betaverteilung folgen, deren erster und zweiter Formparameter gleich 2 ist, weisen beispielsweise einen negativen Kurtosis-Wert auf. Die durchgezogene Linie stellt die Normalverteilung und die gepunktete Linie eine Verteilung mit einem negativen Kurtosis-Wert dar.
N
Die Anzahl der nicht fehlenden Werte in der Stichprobe.
| Gesamtanzahl | N | N* |
|---|---|---|
| 149 | 141 | 8 |
Minimum
Das Minimum ist der kleinste Datenwert.
In diesen Daten ist das Minimum 7.
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
Interpretation
Verwenden Sie das Minimum, um einen möglichen Ausreißer oder einen Fehler bei der Dateneingabe zu identifizieren. Eine der einfachsten Möglichkeiten, um die Streubreite in den Daten zu ermitteln, ist ein Vergleich von Minimum und Maximum. Wenn der Wert des Minimums sehr niedrig ist, selbst bei Berücksichtigung des Zentrums, der Streubreite und der Form der Daten, untersuchen Sie die Ursache für den Extremwert.
Erstes Quartil
Quartile sind die drei Werte – das erste Quartil bei 25 % (Q1), das zweite Quartil bei 50 % (Q2 oder Median) und das dritte Quartil bei 75 % (Q3) –, die eine Stichprobe von geordneten Daten in vier gleiche Teile teilen.
Das 1. Quartil ist das 25. Perzentil und gibt an, dass 25 % der Daten kleiner oder gleich diesem Wert sind.
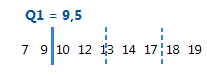
Für diese geordneten Daten beträgt das 1. Quartil (Q1) 9,5. Das heißt, 25 % der Daten sind kleiner oder gleich 9,5.
Median
Der Median ist der Mittelpunkt des Datensatzes. Dieser Wert gibt den Punkt an, an dem die Hälfte der Beobachtungen über dem Wert und die Hälfte der Beobachtungen unter dem Wert liegen. Der Median wird durch Bilden einer Rangfolge der Beobachtungen und Ermitteln der Beobachtung an der Stelle [N + 1] / 2 in der Rangfolge bestimmt. Wenn die Daten eine gerade Anzahl von Beobachtungen enthalten, ist der Median der Durchschnittswert der Beobachtungen an den Stellen N / 2 und [N / 2] + 1 in der Rangfolge.

Für diese geordneten Daten ist der Median 13. Das heißt, die Hälfte der Werte sind kleiner oder gleich 13, und die andere Hälfte der Werte sind größer oder gleich 13. Wenn Sie eine weitere Beobachtung mit dem Wert 20 hinzufügen, beträgt der Median 13,5; dies ist der Durchschnitt zwischen der 5. Beobachtung (13) und der 6. Beobachtung (14).
Interpretation
Symmetrisch
Nicht symmetrisch
Bei der symmetrischen Verteilung ähneln sich der Mittelwert (blaue Linie) und der Median (orangefarbene Linie) so sehr, dass die Linien nicht ohne weiteres unterschieden werden können. Die nicht symmetrische Verteilung ist jedoch rechtsschief.
Drittes Quartil
Quartile sind die drei Werte – das erste Quartil bei 25 % (Q1), das zweite Quartil bei 50 % (Q2 oder Median) und das dritte Quartil bei 75 % (Q3) –, die eine Stichprobe von geordneten Daten in vier gleiche Teile teilen.
Das dritte Quartil ist das 75. Perzentil und gibt an, dass 75 % der Daten kleiner oder gleich dem Wert sind.
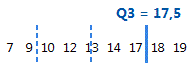
Für diese geordneten Daten beträgt das dritte Quartil (Q3) 17,5. Das heißt, 75 % der Daten sind kleiner oder gleich 17,5.
Maximum
Das Maximum ist der größte Datenwert.
In diesen Daten ist das Maximum 19.
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
Interpretation
Verwenden Sie das Maximum, um einen möglichen Ausreißer oder einen Fehler bei der Dateneingabe zu identifizieren. Eine der einfachsten Möglichkeiten, um die Streubreite in den Daten zu ermitteln, ist ein Vergleich von Minimum und Maximum. Wenn der Wert des Maximums sehr hoch ist, selbst bei Berücksichtigung des Zentrums, der Streubreite und der Form der Daten, untersuchen Sie die Ursache für den Extremwert.
Konfidenzintervall
Das Konfidenzintervall ist ein Bereich wahrscheinlicher Werte für den Parameter der Grundgesamtheit. Da die Stichproben zufällig sind, ist es unwahrscheinlich, dass zwei Stichproben aus einer Grundgesamtheit identische Konfidenzintervalle ergeben. Wenn Sie die Stichprobennahme jedoch viele Male wiederholen, enthält ein bestimmter Prozentsatz der resultierenden Konfidenzintervalle oder -grenzen den unbekannten Parameter der Grundgesamtheit. Der Prozentsatz dieser Konfidenzintervalle oder -grenzen, die den Parameter enthalten, stellt das Konfidenzniveau des Intervalls dar. Ein 95%-Konfidenzniveau gibt beispielsweise an, dass bei einer Entnahme von 100 Zufallsstichproben aus der Grundgesamtheit die Konfidenzintervalle für voraussichtlich ca. 95 der Stichproben den Parameter der Grundgesamtheit enthalten.
Eine Obergrenze ist der Wert, der wahrscheinlich größer als der Parameter der Grundgesamtheit ist. Eine Untergrenze ist der Wert, der wahrscheinlich kleiner als der Parameter der Grundgesamtheit ist.
Anhand des Konfidenzintervalls können Sie die praktische Signifikanz Ihrer Ergebnisse beurteilen. Bestimmen Sie anhand Ihrer Fachkenntnisse, ob das Konfidenzintervall Werte umfasst, die in der jeweiligen Situation von praktischer Signifikanz sind. Wenn das Intervall zu breit und damit nicht hilfreich ist, erwägen Sie, den Stichprobenumfang zu vergrößern. Weitere Informationen finden Sie unter Möglichkeiten zum Erhöhen der Genauigkeit des Konfidenzintervalls.
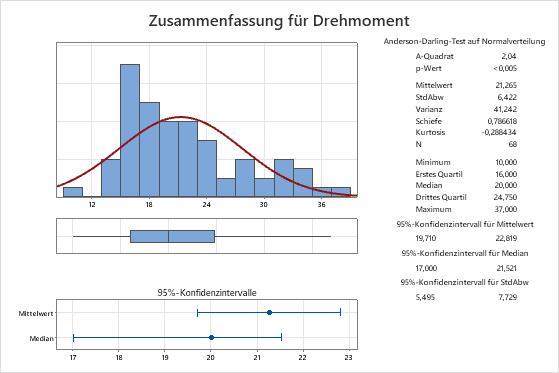
- Der Mittelwert der Grundgesamtheit für die Drehmoment-Messwerte liegt zwischen 19,710 und 22,819.
- Der Median der Grundgesamtheit für die Drehmoment-Messwerte liegt zwischen 17 und 21,521.
- Die Standardabweichung der Grundgesamtheit für die Drehmoment-Messwerte liegt zwischen 5,495 und 7,729.
Histogramm
In einem Histogramm werden die Stichprobenwerte in eine Reihe von Intervallen unterteilt, und die Häufigkeiten der Datenwerte in jedem Intervall werden in Form eines Balkens abgebildet.
Interpretation
Verwenden Sie ein Histogramm, um die Form und Streubreite der Daten auszuwerten. Für Histogramme sollte der Stichprobenumfang größer als 20 sein.
- Schiefe Daten
-
Mit einem Histogramm der Daten, das von einer Normalverteilungskurve überlagert wird, können Sie untersuchen, ob die Daten eine Normalverteilung aufweisen. Eine Normalverteilung ist symmetrisch und glockenförmig, wie durch die Kurve gezeigt. In kleinen Stichproben gestaltet sich eine Untersuchung der Normalverteilung häufig schwierig. Am besten eignet sich ein Wahrscheinlichkeitsnetz, um die Verteilungsanpassung zu beurteilen.
Gute Anpassung
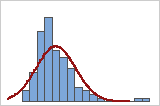
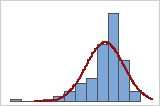
Schlechte Anpassung
- Ausreißer
-
Ausreißer, d. h. Daten, die sich weit entfernt von den anderen Datenwerten befinden, können starke Auswirkungen auf die Ergebnisse Ihrer Analyse haben. Häufig lassen sich Ausreißer am einfachsten in einem Boxplot erkennen.

In einem Histogramm stellen einzelne Balken an den Enden mögliche Ausreißer dar.
Versuchen Sie, die Ursache für die Ausreißer zu ermitteln. Korrigieren Sie sämtliche Dateneingabe- oder Messfehler. Erwägen Sie, Datenwerte zu entfernen, die auf ungewöhnliche, einmalige Ereignisse (so genannte Ausnahmebedingungen) zurückzuführen sind. Wiederholen Sie anschließend die Analyse. Weitere Informationen finden Sie unter Identifizieren von Ausreißern.
- Multimodale Daten
-
Multimodale Daten weisen mehrere Spitzen auf, die auch als Modalwerte bezeichnet werden. Multimodale Daten deuten oftmals darauf hin, dass wichtige Variablen noch nicht berücksichtigt wurden.
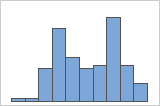
Einfach
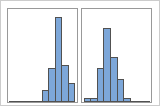
Mit Gruppen
Ein Manager in einer Bank erfasst beispielsweise Daten zu Wartezeiten und erstellt ein einfaches Histogramm. Das Histogramm weist zwei Spitzen auf. Nach eingehenderen Untersuchungen stellt der Manager fest, dass die Wartezeiten für Kunden, die Schecks einlösen, kürzer als die Wartezeiten für Kunden sind, die einen Eigenheimkredit beantragen. Der Manager fügt eine Gruppierungsvariable für den Besuchszweck hinzu und erstellt dann ein Histogramm mit Gruppen.
Wenn Sie über zusätzliche Informationen verfügen, die es Ihnen ermöglichen, die Beobachtungen in Gruppen zu gliedern, können Sie anhand dieser Informationen eine Gruppierungsvariable anlegen. Dann können Sie die Grafik mit den Gruppen erstellen, um zu ermitteln, ob die Gruppierungsvariable die Spitzen in den Daten erklärt.
Boxplot
Ein Boxplot stellt eine grafische Zusammenfassung der Verteilung einer Stichprobe dar. Das Boxplot zeigt die Form, Zentraltendenz und Streuung der Daten.
Interpretation
Verwenden Sie ein Boxplot, um die Streubreite der Daten zu untersuchen und potenzielle Ausreißer zu identifizieren. Für Boxplots sollte der Stichprobenumfang größer als 20 sein.
- Schiefe Daten
-
Untersuchen Sie die Streubreite der Daten, um zu ermitteln, ob die Daten schief sind. Wenn Daten schief sind, befinden sich die meisten Daten im oberen oder unteren Teil der Grafik. Schiefe ist häufig am einfachsten mit einem Histogramm oder Boxplot zu erkennen.
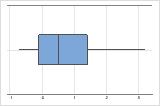
Rechtsschief
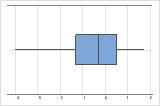
Linksschief
Das Boxplot mit rechtsschiefen Daten zeigt Wartezeiten. Der Großteil der Wartezeiten ist relativ kurz, nur wenige Wartezeiten sind lang. Das Boxplot mit linksschiefen Daten zeigt Daten zu Ausfallzeiten. Einige Elemente fallen sofort aus, deutlich mehr Elemente fallen später aus.
- Ausreißer
-
Ausreißer, d. h. Daten, die sich weit entfernt von den anderen Datenwerten befinden, können starke Auswirkungen auf die Ergebnisse Ihrer Analyse haben. Häufig lassen sich Ausreißer am einfachsten in einem Boxplot erkennen.
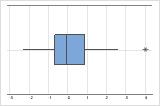
In einem Boxplot werden Ausreißer mit einem Asterisk (*) gekennzeichnet.
Versuchen Sie, die Ursache für die Ausreißer zu ermitteln. Korrigieren Sie sämtliche Dateneingabe- oder Messfehler. Erwägen Sie, Datenwerte zu entfernen, die auf ungewöhnliche, einmalige Ereignisse (so genannte Ausnahmebedingungen) zurückzuführen sind. Wiederholen Sie anschließend die Analyse. Weitere Informationen finden Sie unter Identifizieren von Ausreißern.