In diesem Thema
Geschätzter Mittelwert
Formel
Der Mittelwert für die Poisson-Verteilung wird geschätzt als:
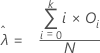
Berechnung
| Daten | 2 2 3 3 2 4 4 2 1 1 1 4 4 3 0 4 3 2 3 3 4 1 3 1 4 3 2 2 1 2 0 2 3 2 3 |
| Kategorie (i) | Beobachtet (Oi) | Geschätzter Mittelwert | Poisson-Wahrscheinlichkeit (pi) |
|---|---|---|---|
| 0 | 2 | 0 * 2 = 0 | p0 = e-2,4 = 0,090718 |
| 1 | 6 | 1 * 6 = 6 | p1 = e-2,4 * 2,4 = 0,217723 |
| 2 | 10 | 2 * 10 = 20 | p2 = e-2,4 * (2,4)2/ 2! = 0,261268 |
| 3 | 10 | 3 * 10 = 30 | p3 = e-2,4 * (2,4)3/ 3! = 0,209014 |
 |
7 | 4 * 7 = 28 | p4 = 1 - (p0 + p1 +p2 + p3) = 0,221267 |
N = 35
Σ (i * Oi) = 84
Geschätzter Mittelwert = 
Notation
| Begriff | Beschreibung |
|---|---|
| N | Summe aller beobachteten Werte (O0 + O1 + ... + Ok) |
| k | (Anzahl der Kategorien) - 1 |
| Oi | beobachtete Anzahl von Ereignissen in der i-ten Kategorie |
| pi | Poisson-Wahrscheinlichkeit |
Anzahl der Kategorien
Minitab bestimmt Kategorien mit Hilfe der folgenden iterativen Methoden:
Definieren der ersten Kategorie
Sei pi = P(X  xi )
xi )
Sei i = 1: Wenn N*pi  2, dann wird die erste Kategorie definiert als "
2, dann wird die erste Kategorie definiert als " x 1". Wenn N*pi < 2, dann wird i um eins hochgezählt und Folgendes wiederholt: Wenn N*p 2
x 1". Wenn N*pi < 2, dann wird i um eins hochgezählt und Folgendes wiederholt: Wenn N*p 2  2, dann wird die erste Kategorie definiert als "
2, dann wird die erste Kategorie definiert als " x 2". Wenn N*pi < 2, dann wird i um eins hochgezählt; dieser Vorgang wird wiederholt, bis N*pi
x 2". Wenn N*pi < 2, dann wird i um eins hochgezählt; dieser Vorgang wird wiederholt, bis N*pi  2. Die Iterationen werden beendet, wenn diese Bedingung erstmalig erfüllt wird oder wenn xi der drittgrößte Datenwert ist, und die erste Kategorie wird definiert als "
2. Die Iterationen werden beendet, wenn diese Bedingung erstmalig erfüllt wird oder wenn xi der drittgrößte Datenwert ist, und die erste Kategorie wird definiert als " xi ". Wenn der Wert der ersten Kategorie null ist, wird die erste Kategorie als „0“ ohne das „kleiner oder gleich“-Symbol definiert. Die Wahrscheinlichkeit und der erwartete Wert für die erste Kategorie lauten pi und N*pi . Der beobachtete Wert für die erste Kategorie ist die Anzahl aller Datenwerte
xi ". Wenn der Wert der ersten Kategorie null ist, wird die erste Kategorie als „0“ ohne das „kleiner oder gleich“-Symbol definiert. Die Wahrscheinlichkeit und der erwartete Wert für die erste Kategorie lauten pi und N*pi . Der beobachtete Wert für die erste Kategorie ist die Anzahl aller Datenwerte  xi .
xi .
Definieren der letzten Kategorie
Konzeptionell ähnelt die Definition der letzten Kategorie der Definition der ersten Kategorie, aber Minitab beginnt mit dem größten Datenwert und arbeitet rückwärts.
Die letzte Kategorie ist " xj ", wobei xj der größte Datenwert größer als (1 + Datenwert der ersten Kategorie) ist, so dass die Kategorie einen erwarteten Wert größer als 2 aufweist. Die Wahrscheinlichkeit und der erwartete Wert für die letzte Kategorie lauten pj und N*pj , und der beobachtete Wert ist die Anzahl der Datenwerte
xj ", wobei xj der größte Datenwert größer als (1 + Datenwert der ersten Kategorie) ist, so dass die Kategorie einen erwarteten Wert größer als 2 aufweist. Die Wahrscheinlichkeit und der erwartete Wert für die letzte Kategorie lauten pj und N*pj , und der beobachtete Wert ist die Anzahl der Datenwerte  xj .
xj .
Definieren der mittleren Kategorien
Nach Bestimmung der ersten und letzten Kategorie legt Minitab die Kategorien dazwischen fest. Sei "X  k" die erste Kategorie und "X
k" die erste Kategorie und "X  m" die letzte Kategorie. Wenn alle ganze Zahlen zwischen (k, m) erwartete Werte
m" die letzte Kategorie. Wenn alle ganze Zahlen zwischen (k, m) erwartete Werte  2 aufweisen, dann bilden sie alle eine mittlere Kategorie. Andernfalls verwendet Minitab eine rekursive Schleife zur Gruppierung mehrerer benachbarter ganzer Zahlen in Kategorien mit erwarteten Werten
2 aufweisen, dann bilden sie alle eine mittlere Kategorie. Andernfalls verwendet Minitab eine rekursive Schleife zur Gruppierung mehrerer benachbarter ganzer Zahlen in Kategorien mit erwarteten Werten  2. In manchen Situationen, z. B. bei einem Datensatz mit wenigen Beobachtungen, ist der erwartete Wert einer Kategorie kleiner als 2.
2. In manchen Situationen, z. B. bei einem Datensatz mit wenigen Beobachtungen, ist der erwartete Wert einer Kategorie kleiner als 2.
Notation
| Begriff | Beschreibung |
|---|---|
| N | Gesamtzahl der Beobachtungen |
| xi | i-ter Wert im Datensatz nach der Sortierung vom kleinsten zum größten |
| pi | Poisson-Wahrscheinlichkeit |
Poisson-Wahrscheinlichkeit
Formel
Die Poisson-Wahrscheinlichkeit der i-ten Kategorie (i < k) ist

Die Poisson-Wahrscheinlichkeit der letzten Kategorie, wobei i = k, ist
pi = 1 – (p0 + p1 + ...+ pk-1)
Notation
| Begriff | Beschreibung |
|---|---|
| k | Anzahl der Kategorien |
| λ | geschätzter Mittelwert der Stichprobe |
Erwartete Anzahl
Formel
Die erwartete Anzahl von Beobachtungen in der i-ten Kategorie beträgt N * pi .
Notation
| Begriff | Beschreibung |
|---|---|
| N | Stichprobenumfang |
| pi | Poisson-Wahrscheinlichkeit, die der i-ten Kategorie zugeordnet ist |
Beitrag zu Chi-Quadrat
Formel
Der Beitrag der I-ten Kategorie zum Chi-Quadrat-Wert wird wie folgt berechnet:
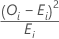
Notation
| Begriff | Beschreibung |
|---|---|
| OI | beobachtete Anzahl von Beobachtungen in der I-ten Kategorie |
| EI | erwartete Anzahl von Beobachtungen in der I-ten Kategorie |
Teststatistik
Formel
Die Teststatistik des Chi-Quadrat-Anpassungstests wird wie folgt berechnet:
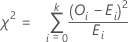
Notation
| Begriff | Beschreibung |
|---|---|
| k | (Anzahl der Kategorien) - 1 |
| Oi | beobachtete Anzahl von Beobachtungen in der i-ten Kategorie |
| Ei | erwartete Anzahl von Beobachtungen in der i-ten Kategorie |
p-Wert und Freiheitsgrade
Der p-Wert ist:
Wahrsch (X > Teststatistik)
wobei X einer Chi-Quadrat-Verteilung mit k - 1 Freiheitsgraden folgt, wenn Sie den Unterbefehl MEAN verwenden, oder k- 2 Freiheitsgraden, wenn Sie den Unterbefehl MEAN nicht verwenden.
Berechnung
| Daten | 2 2 3 3 2 4 4 2 1 1 1 4 4 3 0 4 3 2 3 3 4 1 3 1 4 3 2 2 1 2 0 2 3 2 3 |
| Kategorie (i) | Beobachtet (Oi) | Geschätzter Mittelwert | Poisson-Wahrscheinlichkeit (pi) |
|---|---|---|---|
| 0 | 2 | 0 * 2 = 0 | p0 = e -2,4 = 0,090718 |
| 1 | 6 | 1 * 6 = 6 | p1 = e -2,4 * 2,4 = 0,217723 |
| 2 | 10 | 2 * 10 = 20 | p2 = e -2,4 * (2,4)2/ 2! = 0,261268 |
| 3 | 10 | 3 * 10 = 30 | p3 = e -2,4 * (2,4)3/ 3! = 0,209014 |
 |
7 | 4 * 7 = 28 | p4 = 1 - (p0 + p1 +p2 + p3 ) = 0,221267 |
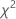 = ( 0,43492 + 0,344527 + 0,080058 + 0,985114 + 0,071545) = 1,91622
= ( 0,43492 + 0,344527 + 0,080058 + 0,985114 + 0,071545) = 1,91622
k = 5= Anzahl der Kategorien
DF = 5 - 2 = 3
p-Wert = P (X > 1,91622) = 0,590
Notation
| Begriff | Beschreibung |
|---|---|
| k | Anzahl der Kategorien |
| Oi | beobachtete Anzahl von Beobachtungen in der i-ten Kategorie |
| Ei | erwartete Anzahl von Beobachtungen in der i-ten Kategorie |
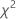 | Statistik des Chi-Quadrat-Anpassungstests |
| DF | Freiheitsgrade |