In diesem Thema
Nullhypothese und Alternativhypothese
- Nullhypothese
- Die Nullhypothese besagt, dass ein Parameter einer Grundgesamtheit (z. B. der Mittelwert, die Standardabweichung usw.) gleich einem Hypothesenwert ist. Die Nullhypothese ist oft eine anfängliche Behauptung auf der Grundlage von früheren Analysen oder Fachwissen.
- Alternativhypothese
- Die Alternativhypothese besagt, dass ein Parameter einer Grundgesamtheit kleiner, größer oder ungleich dem hypothetischen Wert in der Nullhypothese ist. Die Alternativhypothese ist die Hypothese, die Sie als wahr annehmen oder deren Wahrheit Sie nachweisen möchten.
Interpretation
In der Ausgabe können Sie mit Hilfe der Nullhypothese und der Alternativhypothese überprüfen, ob Sie den korrekten Wert für das hypothetische Verhältnis eingegeben haben.
Signifikanzniveau
Das Signifikanzniveau (als α oder Alpha bezeichnet) ist das maximal akzeptable Risiko, dass die Nullhypothese zurückgewiesen wird, wenn sie tatsächlich wahr ist (Fehler 1. Art). Im Allgemeinen wählen Sie das Signifikanzniveau aus, bevor Sie die Daten analysieren. In Minitab können Sie das Signifikanzniveau auswählen, indem Sie das Konfidenzniveau angeben, da das Signifikanzniveau gleich 1 minus dem Konfidenzniveau ist. Da das Standardkonfidenzniveau in Minitab 0,95 ist, ist das Standardsignifikanzniveau 0,05.
Interpretation
Vergleiche Sie das Signifikanzniveau mit dem p-Wert, um zu entscheiden, ob die Nullhypothese (H0) zurückgewiesen oder nicht zurückgewiesen werden sollte. Wenn der p-Wert kleiner als das Signifikanzniveau ist, sind die Ergebnisse nach gängiger Interpretation statistisch signifikant, und Sie weisen H0 zurück.
- Wählen Sie ein höheres Signifikanzniveau wie 0,10, um möglicherweise vorhandene Differenzen mit größerer Gewissheit zu erkennen. Ein Qualitätstechniker vergleicht beispielsweise die Stabilität von neuen Kugellagern mit der Stabilität der derzeit verwendeten Kugellager. Der Techniker muss mit großer Sicherheit schlussfolgern können, dass die neuen Kugellager stabil sind, denn instabile Kugellager können schwere Unfälle nach sich ziehen. Er wählt ein Signifikanzniveau von 0,10, um mit größerer Sicherheit mögliche Differenzen in der Stabilität der Kugellager zu erkennen.
- Wählen Sie niedrigeres Signifikanzniveau wie 0,01, um mit größerer Sicherheit davon ausgehen zu können, dass nur tatsächlich vorhandene Differenzen erkannt werden. Ein Forscher in einem Pharmaunternehmen muss sich beispielsweise sehr sicher über die Behauptung sein, dass das neue Medikament des Unternehmens die Symptome signifikant reduziert. Er wählt ein Signifikanzniveau von 0,001, um mit größerer Sicherheit behaupten zu können, dass signifikante Differenzen hinsichtlich der Symptome tatsächlich vorhanden sind.
N
Der Stichprobenumfang (N) gibt die Gesamtzahl der Beobachtungen in der Stichprobe an.
Interpretation
Der Stichprobenumfang wirkt sich auf das Konfidenzintervall und auf die Trennschärfe des Tests aus.
Eine größere Stichprobe führt in der Regel zu einem schmaleren Konfidenzintervall. Bei größeren Stichprobenumfängen verfügt der Test außerdem über eine höhere Trennschärfe zum Erkennen einer Differenz. Weitere Informationen finden Sie unter Was ist die Trennschärfe?.
StdAbw
Die Standardabweichung ist das am häufigsten verwendete Maß für die Streuung bzw. die Streubreite der Daten um den Mittelwert. Die Standardabweichung einer Grundgesamtheit wird häufig mit dem Zeichen σ (Sigma) angegeben, während mit s die Standardabweichung einer Stichprobe dargestellt wird. Eine zufällige oder natürliche Streuung eines Prozesses wird häufig auch als Rauschen bezeichnet.
Für die Standardabweichung wird die gleiche Einheit wie für die Daten verwendet.
Interpretation
Die Standardabweichung jeder Stichprobe ist ein Schätzwert der Standardabweichung jeder Grundgesamtheit. Minitab verwendet die Standardabweichung, um das Verhältnis zwischen den Standardabweichungen der Grundgesamtheiten zu schätzen. Sie sollten sich auf dieses Verhältnis konzentrieren.

Krankenhaus 1
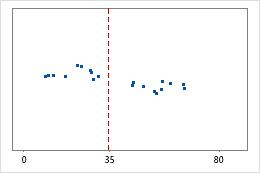
Krankenhaus 2
Zeit bis zur Entlassung in Krankenhäusern
Verwaltungsangestellte zeichnen die Zeit bis zur Entlassung von Patienten auf, die in der Notaufnahme zweier Krankenhäuser behandelt werden. Obwohl die durchschnittliche Zeit bis zur Entlassung in etwa identisch ist (35 Minuten), weichen die Standardabweichungen signifikant voneinander ab. Die Standardabweichung für Krankenhaus 1 beträgt etwa 6. Im Durchschnitt weicht die Zeit bis zur Entlassung eines Patienten um etwa 6 Minuten vom Mittelwert (gestrichelte Linie) ab. Die Standardabweichung für Krankenhaus 2 beträgt etwa 20. Im Durchschnitt weicht die Zeit bis zur Entlassung eines Patienten um ca. 20 Minuten vom Mittelwert (gestrichelte Linie) ab.
Varianz
Die Varianz ist ein Maß der Streuung der Daten um ihren Mittelpunkt. Die Varianz ist gleich dem Quadrat der Standardabweichung.
Interpretation
Die Varianz jeder Stichprobe ist ein Schätzwert der Varianz der betreffenden Grundgesamtheit. Minitab verwendet die Varianzen, um das Verhältnis zwischen den Varianzen der Grundgesamtheiten zu schätzen. Sie sollten sich auf dieses Verhältnis konzentrieren.
Geschätztes Verhältnis der Standardabweichungen
Das Verhältnis der Standardabweichungen ist die Standardabweichung der ersten Stichprobe dividiert durch die Standardabweichung der zweiten Stichprobe.
Interpretation
Das geschätzte Verhältnis zwischen den Standardabweichungen der Stichprobendaten ist ein Schätzwert des Verhältnisses zwischen den Standardabweichungen der Grundgesamtheiten.
Da das geschätzte Verhältnis auf Stichprobendaten und nicht auf der vollständigen Grundgesamtheit basiert, ist es unwahrscheinlich, dass das Verhältnis der Stichprobe gleich dem Verhältnis der Grundgesamtheit ist. Verwenden Sie das Konfidenzintervall, um das Verhältnis besser schätzen zu können.
Geschätztes Verhältnis der Varianzen
Das Verhältnis der Varianzen ist die Varianz der ersten Stichprobe dividiert durch die Varianz der zweiten Stichprobe.
Interpretation
Das geschätzte Verhältnis zwischen den Varianzen der Stichprobendaten ist ein Schätzwert des Verhältnisses zwischen den Varianzen der Grundgesamtheiten.
Da das geschätzte Verhältnis auf Stichprobendaten und nicht auf der vollständigen Grundgesamtheit basiert, ist es unwahrscheinlich, dass das Verhältnis der Stichprobe gleich dem Verhältnis der Grundgesamtheit ist. Verwenden Sie das Konfidenzintervall, um das Verhältnis besser schätzen zu können.
Konfidenzintervall (KI) und Konfidenzgrenzen
Das Konfidenzintervall ist ein Bereich wahrscheinlicher Werte für das Verhältnis der Grundgesamtheit. Da die Stichproben zufällig sind, ist es unwahrscheinlich, dass zwei Stichproben aus einer Grundgesamtheit identische Konfidenzintervalle ergeben. Wenn Sie die Stichprobennahme jedoch viele Male wiederholen, enthält ein bestimmter Prozentsatz der resultierenden Konfidenzintervalle oder -grenzen das unbekannte Verhältnis der Grundgesamtheit. Der Prozentsatz dieser Konfidenzintervalle oder -grenzen, die das Verhältnis enthalten, stellt das Konfidenzniveau des Intervalls dar. Ein 95%-Konfidenzniveau gibt beispielsweise an, dass bei einer Entnahme von 100 Zufallsstichproben aus der Grundgesamtheit die Konfidenzintervalle für voraussichtlich ca. 95 der Stichproben das Verhältnis der Grundgesamtheit enthalten.
Eine Obergrenze ist der Wert, der wahrscheinlich größer als das Verhältnis der Grundgesamtheit ist. Eine Untergrenze ist der Wert, der wahrscheinlich kleiner als das Verhältnis der Grundgesamtheit ist.
Anhand des Konfidenzintervalls können Sie die praktische Signifikanz Ihrer Ergebnisse beurteilen. Bestimmen Sie anhand Ihrer Fachkenntnisse, ob das Konfidenzintervall Werte umfasst, die in der jeweiligen Situation von praktischer Signifikanz sind. Wenn das Intervall zu breit und damit nicht hilfreich ist, erwägen Sie, den Stichprobenumfang zu vergrößern. Weitere Informationen finden Sie unter Möglichkeiten zum Erhöhen der Genauigkeit des Konfidenzintervalls.
Standardmäßig werden beim Test auf Varianzen bei zwei Stichproben die Ergebnisse für die Levene-Methode und die Ergebnisse für die Bonett-Methode angezeigt. Die Bonett-Methode ist in der Regel zuverlässiger als die Levene-Methode. Bei extrem schiefen Verteilungen und Verteilungen mit stark ausgeprägten Randbereichen ist im Allgemeinen jedoch die Levene-Methode zuverlässiger als die Bonett-Methode. Verwenden Sie den F-Test nur, wenn Sie sich sicher sind, dass die Daten einer Normalverteilung folgen. Selbst geringfügige Abweichungen von der Normalverteilung können die Ergebnisse des F-Tests erheblich beeinflussen. Weitere Informationen finden Sie unter Sollte für Test auf Varianzen, 2 Stichproben die Bonett-Methode oder die Levene-Methode verwendet werden?.
Verhältnis der Standardabweichungen
| Geschätztes Verhältnis | 95%-KI für Verhältnis unter Verwendung von Bonett | 95%-KI für Verhältnis unter Verwendung von Levene |
|---|---|---|
| 0,658241 | (0,372; 1,215) | (0,378; 1,296) |
In diesen Ergebnissen beträgt der Schätzwert des Verhältnisses zwischen den Standardabweichungen der Grundgesamtheiten für die Bewertungen von zwei Krankenhäusern 0,658. Bei Verwendung der Bonett-Methode können Sie sich zu 95 % sicher sein, dass das Verhältnis zwischen den Standardabweichungen der Grundgesamtheiten für die Krankenhausbewertungen zwischen 0,372 und 1,215 liegt.
DF
Freiheitsgrade (DF) bezeichnen die Menge der von den Daten gelieferten Informationen, die Sie „verbrauchen“ können, um die Werte der unbekannten Parameter der Grundgesamtheit zu schätzen und die Streuung dieser Schätzwerte zu berechnen. Für einen Test auf Varianzen bei zwei Stichproben werden die Freiheitsgrade durch die Anzahl der Beobachtungen in der Stichprobe bestimmt und hängen außerdem von der Methode ab, die Minitab verwendet.
Interpretation
Minitab verwendet die Freiheitsgrade, um die Teststatistik zu berechnen. Die Freiheitsgrade werden durch den Stichprobenumfang bestimmt. Wenn Sie die Stichprobe vergrößern, stehen Ihnen mehr Informationen über die Grundgesamtheit und somit auch mehr Freiheitsgrade zur Verfügung.
Teststatistik für die Bonett-Methode
Die Teststatistik ist eine Statistik, die Minitab für die Bonett-Methode berechnet, indem das Konfidenzintervall invertiert wird. Die Teststatistik für die Bonett-Methode ist nicht für zusammengefasste Daten oder Daten verfügbar, die nicht balanciert sind.
Interpretation
Sie können die Teststatistik mit kritischen Werten der Chi-Quadrat-Verteilung vergleichen, um zu bestimmen, ob die Nullhypothese zurückzuweisen ist. Es jedoch im Allgemeinen praktischer, hierfür den p-Wert des Tests heranzuziehen. Der p-Wert hat für Tests jeden Umfangs dieselbe Bedeutung, dieselbe Chi-Quadrat-Statistik kann hingegen abhängig vom Stichprobenumfang auf entgegengesetzte Schlussfolgerungen hindeuten.
- Die kritischen Werte für einen beidseitigen Test sind
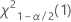 und
und  . Wenn die Teststatistik kleiner als der erste Wert oder größer als der zweite Wert ist, verwerfen Sie die Nullhypothese. Wenn die Teststatistik zwischen dem ersten und dem zweiten Wert liegt, verwerfen Sie die Nullhypothese nicht.
. Wenn die Teststatistik kleiner als der erste Wert oder größer als der zweite Wert ist, verwerfen Sie die Nullhypothese. Wenn die Teststatistik zwischen dem ersten und dem zweiten Wert liegt, verwerfen Sie die Nullhypothese nicht. - Der kritische Wert für einen einseitigen Test mit einer „Kleiner als“-Alternativhypothese ist
 . Wenn die Teststatistik kleiner als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht.
. Wenn die Teststatistik kleiner als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht. - Der kritische Wert für einen einseitigen „Größer als“-Test ist
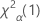 . Wenn die Teststatistik größer als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht.
. Wenn die Teststatistik größer als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht.
Die Teststatistik wird verwendet, um den p-Wert zu berechnen.
Teststatistik für die Levene-Methode
Bei dem Test wird die F-Statistik der einfachen ANOVA auf die absolute Medianabweichung der Beobachtungen angewendet. Daher entspricht die Anwendung der Levene-Methode der Anwendung einer einfachen ANOVA auf die absolute Medianabweichung der Beobachtungen. Bei Fällen mit zwei Stichproben entspricht diese Methode außerdem der Anwendung des t-Verfahrens bei zwei Stichproben auf die absolute Medianabweichung der Beobachtungen.
Interpretation
Sie können die Teststatistik mit kritischen Werten der F-Verteilung vergleichen, um zu bestimmen, ob die Nullhypothese zurückzuweisen ist. Es jedoch im Allgemeinen praktischer, hierfür den p-Wert des Tests heranzuziehen.
- Die kritischen Werte für einen beidseitigen Test sind
 und
und 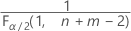 . Wenn die Teststatistik kleiner als der erste Wert oder größer als der zweite Wert ist, verwerfen Sie die Nullhypothese. Wenn die Teststatistik zwischen dem ersten und dem zweiten Wert liegt, verwerfen Sie die Nullhypothese nicht.
. Wenn die Teststatistik kleiner als der erste Wert oder größer als der zweite Wert ist, verwerfen Sie die Nullhypothese. Wenn die Teststatistik zwischen dem ersten und dem zweiten Wert liegt, verwerfen Sie die Nullhypothese nicht. - Der kritische Wert für einen einseitigen Test mit einer „Kleiner als“-Alternativhypothese ist
 . Wenn die Teststatistik kleiner als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht.
. Wenn die Teststatistik kleiner als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht. - Der kritische Wert für einen einseitigen „Größer als“-Test ist
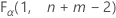 . Wenn die Teststatistik größer als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht.
. Wenn die Teststatistik größer als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht.
Die Teststatistik wird verwendet, um den p-Wert zu berechnen.
Teststatistik für die F-Methode
Die Teststatistik ist eine Statistik für F-Tests, die das Verhältnis zwischen den beobachteten Varianzen misst.
Interpretation
Sie können die Teststatistik mit kritischen Werten der F-Verteilung vergleichen, um zu bestimmen, ob die Nullhypothese zurückzuweisen ist. Es jedoch im Allgemeinen praktischer, hierfür den p-Wert des Tests heranzuziehen.
- Die kritischen Werte für einen beidseitigen Test sind
 und
und 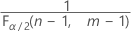 . Wenn die Teststatistik kleiner als der erste Wert oder größer als der zweite Wert ist, verwerfen Sie die Nullhypothese. Wenn die Teststatistik zwischen dem ersten und dem zweiten Wert liegt, verwerfen Sie die Nullhypothese nicht.
. Wenn die Teststatistik kleiner als der erste Wert oder größer als der zweite Wert ist, verwerfen Sie die Nullhypothese. Wenn die Teststatistik zwischen dem ersten und dem zweiten Wert liegt, verwerfen Sie die Nullhypothese nicht. - Der kritische Wert für einen einseitigen Test mit einer „Kleiner als“-Alternativhypothese ist
 . Wenn die Teststatistik kleiner als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht.
. Wenn die Teststatistik kleiner als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht. - Der kritische Wert für einen einseitigen „Größer als“-Test ist
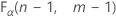 . Wenn die Teststatistik größer als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht.
. Wenn die Teststatistik größer als der kritische Wert ist, verwerfen Sie die Nullhypothese. Andernfalls verwerfen Sie die Nullhypothese nicht.
Die Teststatistik wird verwendet, um den p-Wert zu berechnen.
p-Wert
Der p-Wert ist ein Wahrscheinlichkeitsmaß für die Anzeichen gegen die Annahme der Nullhypothese. Ein kleinerer p-Wert liefert stärkere Anzeichen dafür, dass die Nullhypothese nicht zutrifft.
Interpretation
Verwenden Sie den p-Wert, um zu ermitteln, ob die Differenz zwischen den Standardabweichungen oder Varianzen der Grundgesamtheiten statistisch signifikant ist.
- p-Wert ≤ α: Das Verhältnis zwischen den Standardabweichungen oder Varianzen ist statistisch signifikant (H0 verwerfen)
- Wenn der p-Wert kleiner oder gleich dem Signifikanzniveau ist, weisen Sie die Nullhypothese zurück. Sie können schlussfolgern, dass das Verhältnis zwischen den Standardabweichungen oder Varianzen der Grundgesamtheiten ungleich dem hypothetischen Verhältnis ist. Wenn Sie kein hypothetisches Verhältnis angegeben haben, testet Minitab, ob keine Differenz zwischen den Standardabweichungen oder Varianzen vorliegt Hypothetisches Verhältnis = 1). Bestimmen Sie anhand Ihres Fachwissens, ob die Differenz praktisch signifikant ist. Weitere Informationen finden Sie unter Statistische und praktische Signifikanz.
- p-Wert > α: Das Verhältnis zwischen den Standardabweichungen oder Varianzen ist statistisch nicht signifikant (H0 nicht verwerfen)
- Wenn der p-Wert größer als das Signifikanzniveau ist, weisen Sie die Nullhypothese nicht zurück. Es liegen nicht genügend Anzeichen für die Schlussfolgerung vor, dass das Verhältnis zwischen den Standardabweichungen oder Varianzen der Grundgesamtheiten statistisch signifikant ist. Vergewissern Sie sich, dass der Test über eine ausreichende Trennschärfe verfügt, um eine praktisch signifikante Differenz zu erkennen. Weitere Informationen finden Sie unter Trennschärfe und Stichprobenumfang für Test auf Varianzen, 2 Stichproben.
- Der Bonett-Test ist für jede stetige Verteilung genau und erfordert keine normalverteilten Daten. Der Bonett-Test ist in der Regel zuverlässiger als der Levene-Test.
- Der Levene-Test ist bei stetigen Verteilungen ebenfalls genau. Bei extrem schiefen Verteilungen und bei Verteilungen mit stark ausgeprägten Randbereichen ist die Levene-Methode hingegen eher zuverlässiger als die Bonett-Methode.
- Der F-Test ist nur genau, wenn normalverteilte Daten vorliegen. Selbst geringfügige Abweichung von der Normalverteilung können auch bei großen Stichproben dazu führen, dass der F-Test ungenau ist. Wenn die Daten jedoch der Normalverteilung folgen, weist der F-Test in der Regel eine höhere Trennschärfe als der Bonett- und der Levene-Test auf.
Weitere Informationen finden Sie unter Sollte für Test auf Varianzen, 2 Stichproben die Bonett-Methode oder die Levene-Methode verwendet werden?.
Zusammenfassendes Diagramm
Das zusammenfassende Diagramm zeigt Konfidenzintervalle für das Verhältnis sowie Konfidenzintervalle für die Standardabweichungen oder Varianzen jeder Stichprobe. Das zusammenfassende Diagramm zeigt außerdem Boxplots der Stichprobendaten und p-Werte für die Hypothesentests.
Konfidenzintervalle
Das Konfidenzintervall ist ein Bereich wahrscheinlicher Werte für das Verhältnis der Grundgesamtheit. Da die Stichproben zufällig sind, ist es unwahrscheinlich, dass zwei Stichproben aus einer Grundgesamtheit identische Konfidenzintervalle ergeben. Wenn Sie die Stichprobennahme jedoch viele Male wiederholen, enthält ein bestimmter Prozentsatz der resultierenden Konfidenzintervalle oder -grenzen das unbekannte Verhältnis der Grundgesamtheit. Der Prozentsatz dieser Konfidenzintervalle oder -grenzen, die das Verhältnis enthalten, stellt das Konfidenzniveau des Intervalls dar. Ein 95%-Konfidenzniveau gibt beispielsweise an, dass bei einer Entnahme von 100 Zufallsstichproben aus der Grundgesamtheit die Konfidenzintervalle für voraussichtlich ca. 95 der Stichproben das Verhältnis der Grundgesamtheit enthalten.
Eine Obergrenze ist der Wert, der wahrscheinlich größer als das Verhältnis der Grundgesamtheit ist. Eine Untergrenze ist der Wert, der wahrscheinlich kleiner als das Verhältnis der Grundgesamtheit ist.
Interpretation
Anhand des Konfidenzintervalls können Sie die praktische Signifikanz Ihrer Ergebnisse beurteilen. Bestimmen Sie anhand Ihrer Fachkenntnisse, ob das Konfidenzintervall Werte umfasst, die in der jeweiligen Situation von praktischer Signifikanz sind. Wenn das Intervall zu breit und damit nicht hilfreich ist, erwägen Sie, den Stichprobenumfang zu vergrößern. Weitere Informationen finden Sie unter Möglichkeiten zum Erhöhen der Genauigkeit des Konfidenzintervalls.
Standardmäßig werden beim Test auf Varianzen bei zwei Stichproben die Ergebnisse für die Levene-Methode und die Ergebnisse für die Bonett-Methode angezeigt. Die Bonett-Methode ist in der Regel zuverlässiger als die Levene-Methode. Bei extrem schiefen Verteilungen und Verteilungen mit stark ausgeprägten Randbereichen ist im Allgemeinen jedoch die Levene-Methode zuverlässiger als die Bonett-Methode. Verwenden Sie den F-Test nur, wenn Sie sich sicher sind, dass die Daten einer Normalverteilung folgen. Selbst geringfügige Abweichungen von der Normalverteilung können die Ergebnisse des F-Tests erheblich beeinflussen. Weitere Informationen finden Sie unter Sollte für Test auf Varianzen, 2 Stichproben die Bonett-Methode oder die Levene-Methode verwendet werden?.
Boxplot
Ein Boxplot stellt eine grafische Zusammenfassung der Verteilung jeder Stichprobe dar. Mit dem Boxplot lassen sich die Form, Zentraltendenz und Streuung der Stichproben leicht vergleichen.
Interpretation
Verwenden Sie ein Boxplot, um die Streubreite der Daten zu untersuchen und potenzielle Ausreißer zu identifizieren. Für Boxplots sollte der Stichprobenumfang größer als 20 sein.
- Schiefe Daten
-
Untersuchen Sie die Streubreite der Daten, um zu ermitteln, ob die Daten schief sind. Wenn Daten schief sind, befinden sich die meisten Daten im oberen oder unteren Teil der Grafik. Schiefe ist häufig am einfachsten mit einem Histogramm oder Boxplot zu erkennen.
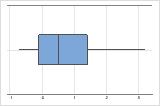
Rechtsschief
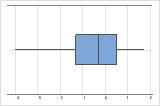
Linksschief
Das Boxplot mit rechtsschiefen Daten zeigt Wartezeiten. Der Großteil der Wartezeiten ist relativ kurz, nur wenige Wartezeiten sind lang. Das Boxplot mit linksschiefen Daten zeigt Daten zu Ausfallzeiten. Einige Elemente fallen sofort aus, deutlich mehr Elemente fallen später aus.
Daten, die eine sehr starke Schiefe aufweisen, können die Gültigkeit des p-Werts beeinträchtigen, wenn die Stichprobe klein ist (weniger als 20 Werte pro Stichprobe). Wenn Ihre Daten stark schief sind und Ihre Stichprobe klein ist, ziehen Sie in Betracht, die Stichprobe zu vergrößern.
- Ausreißer
-
Ausreißer, d. h. Daten, die sich weit entfernt von den anderen Datenwerten befinden, können starke Auswirkungen auf die Ergebnisse Ihrer Analyse haben. Häufig lassen sich Ausreißer am einfachsten in einem Boxplot erkennen.
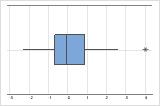
In einem Boxplot werden Ausreißer mit einem Asterisk (*) gekennzeichnet.
Versuchen Sie, die Ursache für die Ausreißer zu ermitteln. Korrigieren Sie sämtliche Dateneingabe- oder Messfehler. Erwägen Sie, Datenwerte zu entfernen, die auf ungewöhnliche, einmalige Ereignisse (so genannte Ausnahmebedingungen) zurückzuführen sind. Wiederholen Sie anschließend die Analyse. Weitere Informationen finden Sie unter Identifizieren von Ausreißern.
Einzelwertdiagramm
Ein Einzelwertdiagramm veranschaulicht die einzelnen Werte in jeder Stichprobe. Mit einem Einzelwertdiagramm lassen sich die Stichproben leicht vergleichen. Jeder Kreis stellt eine Beobachtung dar. Ein Einzelwertdiagramm ist besonders dann nützlich, wenn Ihnen relativ wenige Beobachtungen vorliegen und Sie außerdem den Effekt jeder Beobachtung auswerten müssen.
Interpretation
Verwenden Sie ein Einzelwertdiagramm, um die Streubreite der Daten zu untersuchen und potenzielle Ausreißer zu identifizieren. Für Einzelwertdiagramme sollte der Stichprobenumfang größer als 50 sein.
- Schiefe Daten
-
Untersuchen Sie die Streubreite der Daten, um zu ermitteln, ob die Daten schief sind. Wenn Daten schief sind, befinden sich die meisten Daten im oberen oder unteren Teil der Grafik. Schiefe ist häufig am einfachsten mit einem Histogramm oder Boxplot zu erkennen.
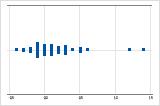
Rechtsschief

Linksschief
Das Einzelwertdiagramm mit rechtsschiefen Daten zeigt Wartezeiten. Der Großteil der Wartezeiten ist relativ kurz, nur wenige Wartezeiten sind lang. Das Einzelwertdiagramm mit linksschiefen Daten zeigt Daten zu Ausfallzeiten. Einige Elemente fallen sofort aus, deutlich mehr Elemente fallen später aus.
Daten, die eine sehr starke Schiefe aufweisen, können die Gültigkeit des p-Werts beeinträchtigen, wenn die Stichprobe klein ist (weniger als 20 Werte pro Stichprobe). Wenn Ihre Daten stark schief sind und Ihre Stichprobe klein ist, ziehen Sie in Betracht, die Stichprobe zu vergrößern.
- Ausreißer
-
Ausreißer, d. h. Daten, die sich weit entfernt von den anderen Datenwerten befinden, können starke Auswirkungen auf die Ergebnisse Ihrer Analyse haben. Häufig lassen sich Ausreißer am einfachsten in einem Boxplot erkennen.
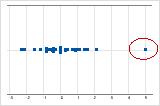
In einem Einzelwertdiagramm weisen ungewöhnlich hohe oder niedrige Datenwerte auf mögliche Ausreißer hin.
Versuchen Sie, die Ursache für die Ausreißer zu ermitteln. Korrigieren Sie sämtliche Dateneingabe- oder Messfehler. Erwägen Sie, Datenwerte zu entfernen, die auf ungewöhnliche, einmalige Ereignisse (so genannte Ausnahmebedingungen) zurückzuführen sind. Wiederholen Sie anschließend die Analyse. Weitere Informationen finden Sie unter Identifizieren von Ausreißern.
Histogramm
In einem Histogramm werden die Stichprobenwerte in eine Reihe von Intervallen unterteilt, und die Häufigkeiten der Datenwerte in jedem Intervall werden in Form eines Balkens abgebildet.
Interpretation
Verwenden Sie ein Histogramm, um die Form und Streubreite der Daten auszuwerten. Für Histogramme sollte der Stichprobenumfang größer als 20 sein.
- Schiefe Daten
-
Untersuchen Sie die Streubreite der Daten, um zu ermitteln, ob die Daten schief sind. Wenn Daten schief sind, befinden sich die meisten Daten im oberen oder unteren Teil der Grafik. Schiefe ist häufig am einfachsten mit einem Histogramm oder Boxplot zu erkennen.
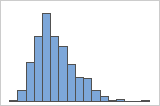
Rechtsschief
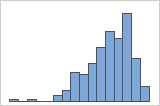
Linksschief
Das Histogramm mit rechtsschiefen Daten zeigt Wartezeiten. Der Großteil der Wartezeiten ist relativ kurz, nur wenige Wartezeiten sind lang. Das Histogramm mit linksschiefen Daten zeigt Daten zu Ausfallzeiten. Einige Elemente fallen sofort aus, deutlich mehr Elemente fallen später aus.
Daten, die eine sehr starke Schiefe aufweisen, können die Gültigkeit des p-Werts beeinträchtigen, wenn die Stichprobe klein ist (weniger als 20 Werte pro Stichprobe). Wenn Ihre Daten stark schief sind und Ihre Stichprobe klein ist, ziehen Sie in Betracht, die Stichprobe zu vergrößern.
- Ausreißer
-
Ausreißer, d. h. Daten, die sich weit entfernt von den anderen Datenwerten befinden, können starke Auswirkungen auf die Ergebnisse Ihrer Analyse haben. Häufig lassen sich Ausreißer am einfachsten in einem Boxplot erkennen.

In einem Histogramm stellen einzelne Balken an den Enden mögliche Ausreißer dar.
Versuchen Sie, die Ursache für die Ausreißer zu ermitteln. Korrigieren Sie sämtliche Dateneingabe- oder Messfehler. Erwägen Sie, Datenwerte zu entfernen, die auf ungewöhnliche, einmalige Ereignisse (so genannte Ausnahmebedingungen) zurückzuführen sind. Wiederholen Sie anschließend die Analyse. Weitere Informationen finden Sie unter Identifizieren von Ausreißern.