In diesem Thema
Schritt 1: Bestimmen, ob jeder Term im Modell signifikant ist
- p-Wert ≤ α: Der Term ist statistisch signifikant
- Wenn der p-Wert kleiner oder gleich dem Signifikanzniveau ist, können Sie schlussfolgern, dass der Koeffizient statistisch signifikant ist.
- p-Wert > α: Der Term ist nicht statistisch signifikant
- Wenn der p-Wert größer als das Signifikanzniveau ist, können Sie nicht schlussfolgern, dass der Koeffizient statistisch signifikant ist. Es empfiehlt sich möglicherweise, dass Modell ohne den Term erneut anzupassen.
Endgültige Schätzwerte der Parameter
| Typ | Koef | SE Koef | t-Wert | p-Wert |
|---|---|---|---|---|
| AR 1 | -0,504 | 0,114 | -4,42 | 0,000 |
| Konstante | 150,415 | 0,325 | 463,34 | 0,000 |
| Mittelwert | 100,000 | 0,216 |
Wichtigste Ergebnisse: p, Koef
Der autoregressive Term weist einen p-Wert auf, der unterhalb des Signifikanzniveaus von 0,05 liegt. Sie können schlussfolgern, dass der Koeffizient für den autoregressiven Term statistisch signifikant ist und Sie den Term im Modell beibehalten sollten.
Schritt 2: Ermitteln, wie gut das Modell an die Daten angepasst ist
Verwenden Sie das mittlere Fehlerquadrat (MS), um zu ermitteln, wie gut das Modell an die Daten angepasst ist. Je niedriger die Werte, desto besser ist das Modell angepasst.
Summen der Quadrate der Residuen
| DF | SS | MS |
|---|---|---|
| 58 | 366,733 | 6,32299 |
Wichtigste Ergebnisse: MS
Das mittlere Fehlerquadrat beträgt für dieses Modell 6,323. Dieser Wert ist an sich ist nicht sehr aussagekräftig, kann jedoch verwendet werden, um die Anpassung verschiedener ARIMA-Modelle zu vergleichen.
Schritt 3: Bestimmen, ob das Modell die Annahme der Analyse erfüllt
- Ljung-Box-Chi-Quadrat-Statistiken
- Um zu ermitteln, ob die Residuen unabhängig sind, vergleichen Sie den p-Wert jeder Chi-Quadrat-Statistik mit dem Signifikanzniveau. In der Regel ist ein Signifikanzniveau (als α oder Alpha bezeichnet) von 0,05 gut geeignet. Wenn der p-Wert größer als das Signifikanzniveau ist, können Sie schlussfolgern, dass die Residuen unabhängig sind und das Modell die Annahme erfüllt.
- Autokorrelationsfunktion der Residuen
- Wenn keine signifikanten Korrelationen vorhanden sind, können Sie schlussfolgern, dass die Residuen unabhängig sind. Es kann jedoch sein, dass Sie ein oder zwei signifikante Korrelationen bei Lags höherer Ordnung feststellen, bei denen es sich nicht um saisonale Lags handelt. Diese Korrelationen sind in der Regel auf zufällige Fehler zurückzuführen und kein Anzeichen dafür, dass die Annahme nicht zutrifft. Sie können in diesem Fall schlussfolgern, dass die Residuen unabhängig sind.
Modifizierte Box-Pierce (Ljung-Box) Chi-Quadrat-Statistik
| Lag | 12 | 24 | 36 | 48 |
|---|---|---|---|---|
| Chi-Quadrat | 4,05 | 12,13 | 25,62 | 32,09 |
| DF | 10 | 22 | 34 | 46 |
| p-Wert | 0,945 | 0,955 | 0,849 | 0,940 |
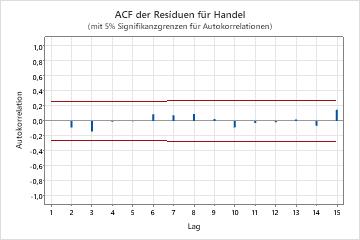
Wichtigste Ergebnisse: p-Wert, ACF der Residuen
In diesen Ergebnissen sind alle p-Werte für die Ljung-Box-Chi-Quadrat-Statistiken größer als 0,05, und keine der Korrelationen für die Autokorrelationsfunktion der Residuen ist signifikant. Sie können schlussfolgern, dass das Modell die Annahme von unabhängigen Residuen erfüllt.