Ein Produktionssicherheitstechniker möchte die Zuverlässigkeit eines neuen Typs von Schalldämpfern auswerten und den Anteil von Garantieansprüchen schätzen, der bei einer Garantie auf 50.000 Meilen zu erwarten ist. Der Techniker erfasst Ausfalldaten sowohl für den alten als auch für den neuen Typ von Schalldämpfern. Die Schalldämpfer wurden alle 10.000 Meilen auf einen Ausfall geprüft.
Der Techniker zeichnet die Anzahl der Ausfälle für jedes Intervall von 10.000 Meilen auf. Daher sind die Daten beliebig zensiert. Vor dem Analysieren der Ausfalldaten für die neuen Schalldämpfer mit der Option „Verteilungsgebundene Analyse (beliebige Zensierung)“ wählt der Techniker mit der Option „Verteilungsidentifikation (beliebige Zensierung)“ ein Verteilungsmodell für die Analyse aus.
- Öffnen Sie die Beispieldaten Schalldämpferzuverlässigkeit.MWX.
- Wählen Sie aus.
- Geben Sie im Feld Startvariablen die Spalte StartNeu ein.
- Geben Sie im Feld Endvariablen die Spalte EndeNeu ein.
- Geben Sie im Feld Häufigkeitenspalten (optional) die Spalte HäufNeu ein.
- Wählen Sie Angeben aus. Vergewissern Sie sich, dass die Standardverteilungen (Weibull, Lognormal, Exponential und Normal) ausgewählt sind.
- Klicken Sie auf OK.
Interpretieren der Ergebnisse
Im Weibull-Wahrscheinlichkeitsnetz folgen die Punkte annähernd der Geraden. Daher bietet die Weibull-Verteilung eine gute Anpassung. Der Techniker entscheidet sich, die Daten für die verteilungsgebundene Analyse (beliebige Zensierung) mit der Weibull-Verteilung zu modellieren.
In Minitab werden außerdem eine Tabelle der Perzentile und eine Tabelle der mittleren Zeit bis zum Ausfall (MTTF) angezeigt, die berechnete Ausfallzeiten für jede Verteilung enthalten. Sie können die berechneten Werte vergleichen, um festzustellen, ob Sie bei anderen Verteilungen andere Schlussfolgerungen ziehen würden. Wenn mehrere Verteilungen gut an Ihre Daten angepasst sind, empfiehlt es sich, die Verteilung zu wählen, die die konservativsten Ergebnisse liefert.
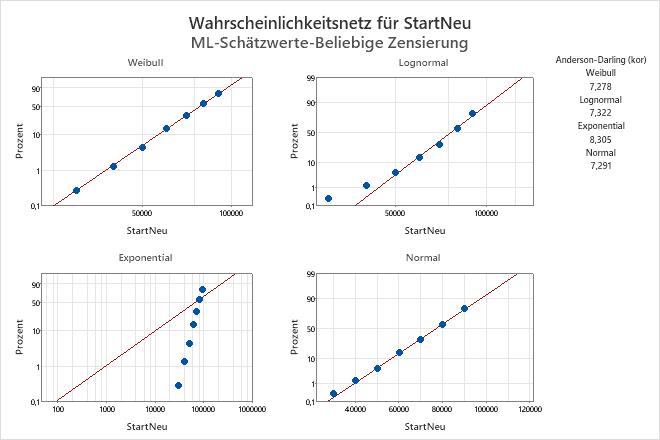
Güte der Anpassung
| Verteilung | Anderson-Darling (kor) |
|---|---|
| Weibull | 7,278 |
| Lognormal | 7,322 |
| Exponential | 8,305 |
| Normal | 7,291 |
Perzentiltabelle
| Normales 95%-KI | |||||
|---|---|---|---|---|---|
| Verteilung | Prozent | Perzentil | Standardfehler | Untergrenze | Obergrenze |
| Weibull | 1 | 37265,1 | 938,485 | 35470,3 | 39150,6 |
| Lognormal | 1 | 43817,7 | 688,033 | 42489,7 | 45187,2 |
| Exponential | 1 | 941,789 | 32,5296 | 880,143 | 1007,75 |
| Normal | 1 | 39810,3 | 1047,34 | 37757,6 | 41863,1 |
| Weibull | 5 | 49434,9 | 841,147 | 47813,5 | 51111,3 |
| Lognormal | 5 | 51458,9 | 624,451 | 50249,5 | 52697,5 |
| Exponential | 5 | 4806,55 | 166,019 | 4491,93 | 5143,21 |
| Normal | 5 | 50694,9 | 810,524 | 49106,3 | 52283,5 |
| Weibull | 10 | 56006,1 | 759,186 | 54537,7 | 57514,0 |
| Lognormal | 10 | 56063,1 | 585,905 | 54926,4 | 57223,3 |
| Exponential | 10 | 9873,05 | 341,017 | 9226,79 | 10564,6 |
| Normal | 10 | 56497,5 | 699,183 | 55127,1 | 57867,8 |
| Weibull | 50 | 77639,9 | 501,312 | 76663,5 | 78628,7 |
| Lognormal | 50 | 75850,3 | 576,625 | 74728,5 | 76988,9 |
| Exponential | 50 | 64952,9 | 2243,49 | 60701,3 | 69502,3 |
| Normal | 50 | 76966,0 | 514,756 | 75957,1 | 77974,9 |
Tabelle für MTTF
| Normales 95%-KI | ||||
|---|---|---|---|---|
| Verteilung | Mittelwert | Standardfehler | Untergrenze | Obergrenze |
| Weibull | 76585,0 | 488,71 | 75633,1 | 77549 |
| Lognormal | 77989,9 | 615,96 | 76792,0 | 79207 |
| Exponential | 93707,3 | 3236,67 | 87573,5 | 100271 |
| Normal | 76966,0 | 514,76 | 75957,1 | 77975 |