Für jedes Fach 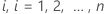 lass
lass  die Step-Funktion sein, die die Anzahl der Ereignisse darstellt, die
die Step-Funktion sein, die die Anzahl der Ereignisse darstellt, die
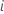 Erlebnisse
bis zur Zeit
Erlebnisse
bis zur Zeit  . Dann
. Dann
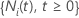 stellt einen Zählvorgang für das Subjekt dar
stellt einen Zählvorgang für das Subjekt dar 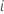 . Sei
. Sei
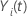 eine Indikatorvariable sein, die den Wert 1 hat, wenn das Subjekt
i zum Zeitpunkt
t gefährdet ist und andernfalls 0, was äquivalent ist zu
eine Indikatorvariable sein, die den Wert 1 hat, wenn das Subjekt
i zum Zeitpunkt
t gefährdet ist und andernfalls 0, was äquivalent ist zu
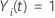 wenn
wenn
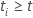 und
und 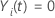 sonst
sonst
 Für
Einzelwerte
Für
Einzelwerte 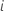 mit einem
Vektor von Prädiktorwerten
mit einem
Vektor von Prädiktorwerten 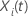 Hat die folgende Form:
Hat die folgende Form: 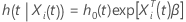
Dabei gilt:  ist die Baseline-Hazard-Rate, die die nicht spezifizierte Verteilung der
Überlebenszeit charakterisiert und
ist die Baseline-Hazard-Rate, die die nicht spezifizierte Verteilung der
Überlebenszeit charakterisiert und  ist ein
p-Komponentenvektor unbekannter Regressionskoeffizienten.
ist ein
p-Komponentenvektor unbekannter Regressionskoeffizienten.
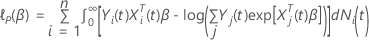
 Hat die folgende Form:
Hat die folgende Form: 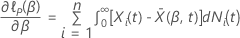
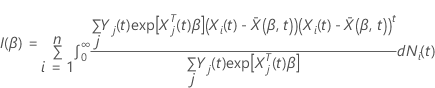
 Hat die
folgende Form:
Hat die
folgende Form: 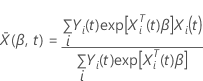
- Das Subjekt kann mehr als ein Ereignis von Interesse erleben.
- Das Subjekt kann ein Ereignis
mehrmals erleben. Diese Aussage bedeutet, dass die Indikatorvariable, die
angibt, ob das Subjekt gefährdet ist,
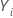 ,
kann zustände von 1 auf 0 und wieder zurück mehrmals ändern.
,
kann zustände von 1 auf 0 und wieder zurück mehrmals ändern.
- Das Subjekt kann nach Zeit 0 in die Studie eintreten. Diese Aussage entspricht der Vorstellung, dass ein Subjekt nach Zeit 0 in die Risikomenge eintreten kann. Eine Zeit wird links abgeschnitten, wenn der Betreff nach Zeit 0 eingegeben wird.
Das Eingabeformular für den Zählprozess
Im Eingabeformular des Zählprozesses stellen mehrere Zeilen jedes Thema dar. Jede Zeile beschreibt ein Zeitintervall, in dem die Werte aller Variablen konstant sind. Zeitabhängige Prädiktoren ändern sich zwischen Zeilen. Die Intervalle beginnen direkt nach der Startzeit und schließen die Endzeit ein. Die Startzeit für das Intervall ist die Eingabezeit für das Subjekt. Die Endzeit ist die Antwortvariable für das Subjekt. Die Zensurspalte gibt jede Zeile an, in der die Endzeit keine Ereigniszeit ist.
Korrelierte Beobachtungen und der robuste Kovarianzschätzer
Obwohl mehrere Zeilen jedes Subjekt im Eingabeformular des Zählprozesses
darstellen, trägt jeweils nur eine Zeile der Beobachtungen pro Subjekt zur
Wahrscheinlichkeit bei, es sei denn, es besteht eine Korrelation zwischen den
Beobachtungen in einer Untergruppe, die sich auf jedes Subjekt beziehen.
Beispielsweise werden die Beobachtungen der Probanden in Modellen korreliert,
die wiederholte oder wiederkehrende Ereignisse enthalten. Lin und Wei
(1989)4
eine Anpassung der Kovarianzmatrix vorschlagen, um die Korrelation zwischen
Beobachtungen innerhalb des Subjekts zu berücksichtigen. Sei
 die Matrix der Score-Residuen sein. Die Varianz-Kovarianz-Matrix hat die
folgende Form:
die Matrix der Score-Residuen sein. Die Varianz-Kovarianz-Matrix hat die
folgende Form:

Dabei gilt:  und
und  ist die reduzierte Score-Restmatrix. Um die reduzierte Bewertungsrestmatrix zu
erhalten, ersetzen Sie jeden Cluster von Bewertungsrestzeilen durch die Summe
dieser Restzeilen.
ist die reduzierte Score-Restmatrix. Um die reduzierte Bewertungsrestmatrix zu
erhalten, ersetzen Sie jeden Cluster von Bewertungsrestzeilen durch die Summe
dieser Restzeilen.
- Berechnungen für Inferenzen verwenden die robuste Varianz-Kovarianz-Matrix.
- Die Wald- und Score-Tests in der Goodness-of-Fit-Tabelle verwenden die robuste Varianz-Kovarianz-Matrix. Der Wahrscheinlichkeitsverhältnistest in der Goodness-of-Fit-Tabelle fehlt, da der Wahrscheinlichkeitsverhältnistest davon ausgeht, dass die Beobachtungen innerhalb eines Clusters unabhängig sind.
- Die ANOVA-Tabelle kann nur den Wald-Test verwenden.