In diesem Thema
Die Varianzanalyse liefert einen Test der statistischen Signifikanz für jeden Prädiktor im Modell.
+ DF
Die Interpretation des Chancenverhältnisses hängt davon ab, ob es sich um einen stetigen oder einen kategorialen Prädiktor handelt. Für einen kategorialen Prädiktor sind die Freiheitsgrade 1 kleiner als die Anzahl der Ebenen, k, im Prädiktor (k – 1). Für einen kontinuierlichen Prädiktor sind die Freiheitsgrade immer 1. Für einen Begriff höherer Ordnung sind die Freiheitsgrade das Produkt der Freiheitsgrade in den zusammengesetzten Termen. Zum Beispiel ist der Freiheitsgrad für die Interaktion zwischen zwei 3-ufigen kategorialen Prädiktoren 2 x 2 = 4
Chi-Quadrat
- Wald-Test
- Likelihood-Quotienten-Test
- Score-Tests
Wenn Cluster im Entwurf vorhanden sind, stellt Minitab die ANOVA-Tabelle basierend auf dem Wald-Test bereit, da die Wahrscheinlichkeitsverhältnis- und Bewertungsmethoden davon ausgehen, dass Beobachtungen innerhalb von Clustern unabhängig sind.
Wenn die Antwortvariable keine gebundenen Antwortzeiten hat, ist der Bewertungstest identisch mit dem bekannten Log-Rank-Test.
Definitionen:
Die Berechnungen für alle 3 Testtypen verwenden die folgenden Definitionen.
Sei 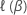 sei die Breslow-Teilwahrscheinlichkeitsfunktion oder die
Efron-Teilwahrscheinlichkeitsfunktion, die bei
β ausgewertet wird.
sei die Breslow-Teilwahrscheinlichkeitsfunktion oder die
Efron-Teilwahrscheinlichkeitsfunktion, die bei
β ausgewertet wird.
Sei 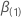 ein
q-Komponentenvektor sein und
ein
q-Komponentenvektor sein und 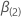 be a (p –
q) -Komponentenvektor, so dass die 2
p-Komponenten-Koeffizientenvektoren die folgenden Definitionen haben:
be a (p –
q) -Komponentenvektor, so dass die 2
p-Komponenten-Koeffizientenvektoren die folgenden Definitionen haben:
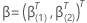 und
und 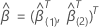 .
.
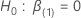

Sei 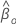 die (partielle) maximale Wahrscheinlichkeit von
die (partielle) maximale Wahrscheinlichkeit von
 nach dem eingeschränkten Modell, wobei
nach dem eingeschränkten Modell, wobei 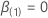 .
Dann hat die Maximum-Likelihood-Schätzung unter der Nullhypothese die folgende
Form:
.
Dann hat die Maximum-Likelihood-Schätzung unter der Nullhypothese die folgende
Form:
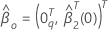
Dabei gilt: 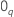 Ist ein
q-Komponentenvektor von Nullen und
Ist ein
q-Komponentenvektor von Nullen und  ist die (partielle) maximale Wahrscheinlichkeit von
ist die (partielle) maximale Wahrscheinlichkeit von
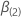 wann
wann 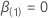 .
.
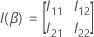
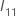 ist das folgende
q x
q-Matrix:
ist das folgende
q x
q-Matrix: 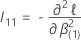
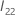 ist die folgende
p –
q x
p –
q-Matrix:
ist die folgende
p –
q x
p –
q-Matrix: 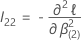
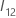 und
und  ist wie folgt definiert:
ist wie folgt definiert: 
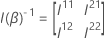
Unter der Nullhypothese hat die Teststatistik für jeden der drei Tests (Wald-, Likelihood-Ratio- und Score-Tests) eine asymptotische Chi-Quadrat-Verteilung mit q-Freiheitsgraden. Die asymptotische Verteilung ist gültig, wenn die Anzahl der beobachteten Ereignisse im Vergleich zur Anzahl der Parameter im Modell groß ist. Für kategoriale Prädiktoren muss die Anzahl der Ereignisse in jeder Ebene ebenfalls groß genug sein.
Wald-Test
Für den Wald-Test hat die Teststatistik folgende Form:
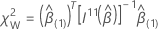
Dabei gilt: 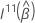 ist das obere
q x
q Submatrix von
ist das obere
q x
q Submatrix von  .
.
Wenn das Design Cluster hat, verwenden die Berechnungen die robuste
Varianz von Lin & Wei (1989)1.
Sei  die Matrix der Score-Residuen sein. Die Varianz-Kovarianz-Matrix hat die
folgende Form:
die Matrix der Score-Residuen sein. Die Varianz-Kovarianz-Matrix hat die
folgende Form:

Dabei gilt:  und
und  ist die reduzierte Score-Restmatrix. Um die reduzierte Bewertungsrestmatrix zu
erhalten, ersetzen Sie jeden Cluster von Bewertungsrestzeilen durch die Summe
dieser Restzeilen.
ist die reduzierte Score-Restmatrix. Um die reduzierte Bewertungsrestmatrix zu
erhalten, ersetzen Sie jeden Cluster von Bewertungsrestzeilen durch die Summe
dieser Restzeilen.
Likelihood-Quotienten-Test
Die Hypothesen für den Likelihood-Quotienten-Test lauten wie folgt:
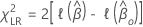
Dabei gilt: 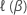 ist die geeignete partielle Log-Likelihood-Funktion des Modells.
ist die geeignete partielle Log-Likelihood-Funktion des Modells.
Wenn Cluster im Entwurf vorhanden sind, stellt Minitab die ANOVA-Tabelle basierend auf dem Wald-Test bereit, da die Wahrscheinlichkeitsverhältnis- und Bewertungsmethoden davon ausgehen, dass Beobachtungen innerhalb von Clustern unabhängig sind.
Score-Tests
Sei 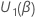 der Vektor partieller Ableitungen der Log-Likelihood-Funktion in Bezug auf
der Vektor partieller Ableitungen der Log-Likelihood-Funktion in Bezug auf
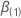 .
Insbesondere hat dieser
q-Komponentenvektor die folgende Form:
.
Insbesondere hat dieser
q-Komponentenvektor die folgende Form:
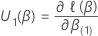
Dann hat die Teststatistik für den Score-Test folgende Form:
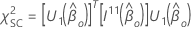
Wenn Cluster im Entwurf vorhanden sind, stellt Minitab die ANOVA-Tabelle basierend auf dem Wald-Test bereit, da die Wahrscheinlichkeitsverhältnis- und Bewertungsmethoden davon ausgehen, dass Beobachtungen innerhalb von Clustern unabhängig sind.
p-Wert
Der p-Wert hat folgende Form:

Dabei gilt:  ist eine Zufallsvariable, die einer Chi-Quadrat-Verteilung folgt mit
ist eine Zufallsvariable, die einer Chi-Quadrat-Verteilung folgt mit
 Freiheitsgraden.
Freiheitsgraden.  ist die Teststatistik.
ist die Teststatistik.