In diesem Thema
Anpassung
Angepasste Werte sind auch bekannt als Anpassungen oder 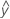 . Die angepassten Werte sind Punktschätzungen des Mittelwerts der Antwortvariablen für die gegebenen Werte der Prädiktoren. Die Werte der Prädiktoren werden auch als x-Werte bezeichnet.
. Die angepassten Werte sind Punktschätzungen des Mittelwerts der Antwortvariablen für die gegebenen Werte der Prädiktoren. Die Werte der Prädiktoren werden auch als x-Werte bezeichnet.
Interpretation
Angepasste Werte werden durch Einsetzen der spezifischen x-Werte für jede Beobachtung im Datensatz in die Modellgleichung berechnet.
Wenn die Gleichung beispielsweise y = 5 + 10x lautet, ergibt ein x-Wert von 2 den angepassten Wert 25 (25 = 5 + 10(2)).
Beobachtungen mit angepassten Werten, die stark vom beobachteten Wert abweichen, können ungewöhnlich sein. Beobachtungen mit ungewöhnlichen Prädiktorwerten üben möglicherweise einen starken Einfluss aus. Wenn Minitab feststellt, dass Ihre Daten ungewöhnliche oder einflussreiche Werte enthalten, enthält die Ausgabe die Tabelle „Anpassungen und Bewertung für ungewöhnliche Beobachtungen“, in der die betreffenden Beobachtungen identifiziert werden. Die von Minitab als ungewöhnlich gekennzeichneten Beobachtungen werden durch die vorgeschlagene Regressionsgleichung nicht gut modelliert. Es ist jedoch zu erwarten, dass einige ungewöhnliche Beobachtungen vorliegen. Entsprechend den Kriterien für große standardisierte Residuen ist beispielsweise zu erwarten, dass ca. 5 % der Beobachtungen als Beobachtungen mit einem großen standardisierten Residuum gekennzeichnet werden. Weitere Informationen zu ungewöhnlichen Werten finden Sie unter Ungewöhnliche Beobachtungen.
SE Anpassung
Der Standardfehler der Anpassung (SE Anpassung) ist ein Schätzwert der Streuung im geschätzten Mittelwert der Antwort für die angegebenen Variableneinstellungen. Der Standardfehler der Anpassung wird bei der Berechnung des Konfidenzintervalls für den Mittelwert der Antwortvariablen verwendet. Standardfehler sind immer nicht negativ. Die Analyse berechnet Standardfehler für Modelle aus dem Statistik Menü und Modelle aus Lineare Regression und Binäre logistische Regression aus der Predictive Analytics-Modul.
Interpretation
Verwenden Sie den Standardfehler der Anpassung, um zu ermitteln, wie genau der Schätzwert für den Mittelwert der Antwort ist. Je kleiner der Standardfehler, desto genauer ist der prognostizierte Mittelwert der Antwort. Ein Analytiker entwickelt beispielsweise ein Modell, um die Lieferzeit zu prognostizieren. Für einen Satz von Variableneinstellungen prognostiziert das Modell eine mittlere Lieferzeit von 3,80 Tagen. Der Standardfehler der Anpassung für diese Einstellungen beträgt 0,08 Tage. Für einen zweiten Satz von Variableneinstellungen errechnet das Modell dieselbe mittlere Lieferzeit mit einem Standardfehler der Anpassung von 0,02 Tagen. Der Analytiker kann sich sicherer sein, dass die mittlere Lieferzeit für den zweiten Satz von Variableneinstellungen nahe an 3,80 Tagen liegt.
Mit dem angepassten Wert können Sie den Standardfehler der Anpassung verwenden, um ein Konfidenzintervall für die mittlere Antwortvariablen zu erstellen. Abhängig von der Anzahl der Freiheitsgrade erstreckt sich ein Konfidenzintervall von 95 % beispielsweise über und unter den vorhergesagten Mittelwert. Für die Lieferzeiten beträgt das 95%-Konfidenzintervall des prognostizierten Mittelwerts von 3,80 Tagen bei einem Standardfehler von 0,08 (3,64; 3,96) Tage. Sie können zu 95 % sicher sein, dass der Mittelwert der Grundgesamtheit innerhalb dieses Bereichs liegt. Wenn der Standardfehler 0,02 beträgt, ist das 95%-Konfidenzintervall (3,76; 3,84) Tage. Das Konfidenzintervall für den zweiten Satz von Variableneinstellungen ist schmaler, weil der Standardfehler kleiner ist.
95%-KI
Das Konfidenzintervall für die Anpassung gibt einen Bereich wahrscheinlicher Werte für den Mittelwert der Antwortvariablen bei bestimmten Einstellungen der Prädiktoren an.
Interpretation
Verwenden Sie das Konfidenzintervall, um den Schätzwert des angepassten Werts für die beobachteten Werte der Variablen auszuwerten.
Bei einem 95%-Konfidenzniveau können Sie sich beispielsweise zu 95 % sicher sein, dass das Konfidenzintervall den Mittelwert der Grundgesamtheit für die angegebenen Werte der Variablen im Modell enthält. Anhand des Konfidenzintervalls können Sie die praktische Signifikanz Ihrer Ergebnisse beurteilen. Bestimmen Sie anhand Ihrer Fachkenntnisse, ob das Konfidenzintervall Werte umfasst, die in der jeweiligen Situation von praktischer Signifikanz sind. Ein breites Konfidenzintervall deutet darauf hin, dass Sie sich bezüglich des Mittelwerts von künftigen Werten weniger sicher sein können. Wenn das Intervall zu breit und damit nicht hilfreich ist, erwägen Sie, den Stichprobenumfang zu vergrößern.
95%-PI
Das Prognoseintervall ist ein Bereich, der bei bestimmten Einstellungen für die Prädiktoren wahrscheinlich einen einzelnen zukünftigen Wert der Antwortvariablen für einen bestimmten Wert der Prädiktorvariablen enthält.
Interpretation
Ein Materialtechniker in einem Möbelwerk entwickelt beispielsweise ein einfaches Regressionsmodell, um die Steife einer Spanplatte anhand der Dichte der Platte zu prognostizieren. Der Techniker vergewissert sich, dass das Modell die Annahmen der Analyse erfüllt. Anschließend verwendet er das Modell zum Prognostizieren der Steife.
Mit der Regressionsgleichung wird prognostiziert, dass die Steife für eine neue Beobachtung 66,995 beträgt und das Prognoseintervall [50; 85] lautet. Es ist zwar unwahrscheinlich, dass die Beobachtung eine Steife von genau 66,995 aufweist. Das Prognoseintervall weist jedoch darauf hin, dass sich der Techniker zu 95 % sicher sein kann, dass der tatsächliche Wert zwischen ungefähr 48 und 86 liegt.
Das Prognoseintervall ist immer breiter als das entsprechende Konfidenzintervall. Dies ist auf die zusätzliche Unsicherheit beim Prognostizieren eines einzelnen Werts der Antwortvariablen gegenüber dem Mittelwert der Antwortvariablen zurückzuführen.