In diesem Thema
Polynomiale Regressionsmodelle
Formel
Sie können die folgenden linearen, quadratischen oder kubischen Regressionsmodelle anpassen:
| Modelltyp | Ordnung | Statistisches Modell |
|---|---|---|
| linear | erste | y = β0+ β1x + e |
| quadratisch | zweite | y = β0+ β1x + β2x2+ e |
| kubisch | dritte | y = β0+ β1x + β2x2+ β3x3+ e |
Eine andere Möglichkeit, Krümmungen zu modellieren, besteht darin, anhand des log10 von x und/oder y für lineare, quadratische und kubische Modelle weitere Modelle zu erstellen. Außerdem lässt sich mit dem log10 von y eine Rechtsschiefe oder eine nicht konstante Varianz von Residuen reduzieren.
Bei der Anpassung von quadratischen oder kubischen Modellen standardisiert Minitab die Prädiktoren, bevor die Koeffizienten geschätzt werden. Mit der Standardisierung wird die Multikollinearität zwischen den Prädiktoren reduziert. Durch die Reduzierung wird sichergestellt, dass die Multikollinearität so gering ist, dass ein Ausschluss von Prädiktoren aus dem Modell durch Minitab unwahrscheinlich wird. Die Ausgabe zeigt die nicht standardisierten Koeffizienten in der ursprünglichen Einheit des Prädiktors.
Koeffizient (Koef)
Die Formel für den Koeffizienten oder die Steigung in der einfachen linearen Regression lautet:
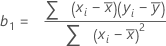
Die Formel für den Schnittpunkt mit der y-Achse (b0) lautet:

Ausgedrückt unter Verwendung von Matrizen lautet die Formel zum Berechnen des Vektors von Koeffizienten in der multiplen Regression:
b = (X'X)-1X'y
Notation
| Begriff | Beschreibung |
|---|---|
| yi | i-ter beobachteter Wert der Antwortvariablen |
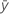 | Mittelwert der Antwortvariablen |
| xi | i-ter Prädiktorwert |
 | Mittelwert des Prädiktors |
| X | Designmatrix |
| y | Matrix der Antwortvariablen |
S

Notation
| Begriff | Beschreibung |
|---|---|
| MSE | Mittleres Fehlerquadrat |
R-Qd


R2 kann auch berechnet werden als quadrierte Korrelation von y und 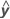 .
.
Notation
| Begriff | Beschreibung |
|---|---|
| SS | Summe der Quadrate |
| y | Antwortvariable |
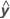 | angepasste Antwortvariable |
R-Qd(kor)

Notation
| Begriff | Beschreibung |
|---|---|
| MS | Mittel der Quadrate |
| SS | Summe der Quadrate |
| DF | Freiheitsgrade |
Freiheitsgrade (DF)
Die Freiheitsgrade für jede Komponente des Modells werden wie folgt ausgedrückt:
| Quellen der Streuung | DF |
|---|---|
| Regression | p |
| Fehler | n – p – 1 |
| Gesamt | n – 1 |
- Die Daten enthalten mehrere Beobachtungen mit denselben Prädiktorwerten.
- Die Daten enthalten die richtigen Punkte zum Schützen von zusätzlichen Termen, die sich nicht im Modell befinden.
Notation
| Begriff | Beschreibung |
|---|---|
| n | Anzahl der Beobachtungen |
| p | Anzahl der Koeffizienten im Modell ohne die Konstante |
Kor SS
Hierbei handelt es sich um die Summe der quadrierten Distanzen. SS Regression ist der Teil der Streuung, der durch das Modell erklärt wird. SS Fehler ist der Teil, der nicht durch das Modell erklärt wird und auf Fehler zurückzuführen ist. SS Gesamt gibt die Gesamtstreuung der Daten an.
Formel

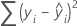
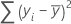
Notation
| Begriff | Beschreibung |
|---|---|
| yi | i-ter beobachteter Wert der Antwortvariablen |
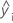 | i-ter angepasster Wert der Antwortvariablen |
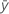 | Mittelwert der Antwortvariablen |
Kor MS – Fehler
Das mittlere Fehlerquadrat (das auch als MS Fehler oder MSE abgekürzt und als s2 angegeben wird) ist die Varianz um die angepasste Regressionslinie. Die Formel lautet wie folgt:

Notation
| Begriff | Beschreibung |
|---|---|
| yi | i-ter beobachteter Wert der Antwortvariablen |
 | i-ter angepasster Wert der Antwortvariablen |
| n | Anzahl der Beobachtungen |
| p | Anzahl der Koeffizienten im Modell, wobei die Konstante nicht gezählt wird |
Kor MS – Regression
Die Formel für das Mittel der Quadrate (MS) der Regression lautet wie folgt:
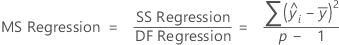
Notation
| Begriff | Beschreibung |
|---|---|
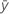 | Mittelwert der Antwortvariablen |
 | i-ter angepasster Wert der Antwortvariablen |
| p | Anzahl der Terme im Modell |
Kor MS – Gesamt
Die Formel für den Gesamtmittelwert (MS) lautet:

Notation
| Begriff | Beschreibung |
|---|---|
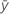 | Mittelwert der Antwortvariablen |
| yi | i-ter beobachteter Wert der Antwortvariablen |
| n | Anzahl der Beobachtungen |
F-Wert
Die Formeln für die F-Statistiken lauten wie folgt:
- F(Regression)
-

- F(Term)
-

- F(Fehlende Anpassung)
-

Notation
| Begriff | Beschreibung |
|---|---|
| MS Regression | Ein Maß der Streuung in der Antwortvariablen, die durch das aktuelle Modell erklärt wird. |
| MS Fehler | Ein Maß der Streuung, die durch das Modell nicht erklärt wird. |
| MS Term | Ein Maß der Streuung, die durch einen Term erklärt wird, nachdem die anderen Terme im Modell berücksichtigt wurden. |
| MS Fehlende Anpassung | Ein Maß der Streuung in der Antwortvariablen, die durch Hinzufügen weiterer Terme zum Modell modelliert werden könnte. |
| MS Reiner Fehler | Ein Maß der Streuung in replizierten Antwortdaten. |
p-Wert – Tabelle der Varianzanalyse
Der p-Wert ist ein Wahrscheinlichkeitsmaß, das aus einer F-Verteilung mit den Freiheitsgraden (DF) wie folgt berechnet wird:
- DF des Zählers
- Summe der Freiheitsgrade für den Term oder die Terme im Test
- DF des Nenners
- Freiheitsgrade für Fehler
Formel
1 − P(F ≤ fj)
Notation
| Begriff | Beschreibung |
|---|---|
| P(F ≤ f) | kumulative Verteilungsfunktion für die F-Verteilung |
| f | F-Statistik für den Test |
Residuum (Resid)
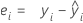
Notation
| Begriff | Beschreibung |
|---|---|
| ei | i-tes Residuum |
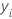 | i-ter beobachteter Wert der Antwortvariablen |
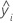 | i-ter angepasster Wert der Antwortvariablen |