In diesem Thema
Hebelwirkungen (Hoch)
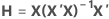
Die Hebelwirkung der i-ten Beobachtung ist das i-te Diagonalelement hi von H. Wenn hi groß ist, weist die i-te Beobachtung ungewöhnliche Prädiktoren (X1i, X2i, ..., Xpi) auf. Das heißt, die Prädiktorwerte liegen weit entfernt vom mittleren Vektor 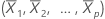 , wobei als Maß die Mahalanobis-Distanz verwendet wird.
, wobei als Maß die Mahalanobis-Distanz verwendet wird.
Hebelwirkungswerte liegen zwischen 0 und 1. Minitab kennzeichnet Beobachtungen mit Hebelwirkungswerten größer als 3p/n oder, falls kleiner, 0,99 in der Tabelle der ungewöhnlichen Beobachtungen mit einem X. Im Allgemeinen sollten Sie Werte mit großen Hebelwirkungen untersuchen.
Notation
| Begriff | Beschreibung |
|---|---|
| X | Versuchsplanmatrix |
| hi | i-tes Diagonalelement der „Dach-Matrix“ (Hat-Matrix) |
| p | Anzahl der Terme im Modell, einschließlich der Konstanten |
| n | Anzahl der Beobachtungen |
Hebelwirkungen (hoch) mit Validierung
Formel

Bei der gewichteten Regression enthält die Formel die Gewichtung:
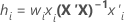
Notation
| Begriff | Beschreibung |
|---|---|
| X | design matrix for the rows in the training data set or the folds that act as the training data set |
| xi | the vector of predictors in the i-te validation row |
| wi | weight for the i-te validation row |
Cook-Distanz
Hierbei handelt es sich um das Gesamtmaß D der kombinierten Auswirkungen aller geschätzten Regressionskoeffizienten auf eine Beobachtung. Minitab berechnet D mit Hebelwirkungswerten und standardisierten Residuen; dabei wird berücksichtigt, ob eine Beobachtung in Bezug auf die x- und y-Werte ungewöhnlich ist. Beobachtungen mit großen D-Werten können Ausreißer sein.
Formel
Die Cook-Distanz ist der Abstand zwischen den Koeffizienten, der mit und ohne die i-te Beobachtung berechnet wurde. Minitab berechnet die Cook-Distanz, ohne dass bei jeder ausgelassenen Beobachtung eine neue Regressionsgleichung angepasst wird. Diese Berechnung lautet wie folgt:

Notation
| Begriff | Beschreibung |
|---|---|
| ei | i-tes Residuum |
| hi | i-tes Diagonalelement von 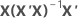 |
| p | Anzahl der Modellparameter, einschließlich der Konstanten |
| s 2 | mittleres Fehlerquadrat |
| b | Vektor der Koeffizienten |
| b(i) | Vektor der Koeffizienten, der nach dem Entfernen der i-ten Beobachtung berechnet wird |
| X | Versuchsplanmatrix |
DFITS
Hiermit werden die Hebelwirkung und das studentisierte Residuum (entfernte t-Residuen) in einem Gesamtmaß zusammengefasst, das ausdrückt, wie ungewöhnlich eine Beobachtung ist. Mit DFITS wird der Einfluss der einzelnen Beobachtungen auf die angepassten Werte in Regressions- und ANOVA-Modellen gemessen. Bei Beobachtungen mit großen DFITS-Werten handelt es sich möglicherweise um Ausreißer.
DFITS stellt die ungefähre Anzahl der Standardabweichungen dar, um die sich der angepasste Wert ändert, wenn je eine Beobachtung aus dem Datensatz entfernt und das Modell erneut angepasst wird. Minitab kann den DFITS-Wert berechnen, ohne dass bei jeder entfernten Beobachtung eine neue Regressionsgleichung angepasst wird.
Formel

Notation
| Begriff | Beschreibung |
|---|---|
| ei | i-tes Residuum |
| hi | i-tes Diagonalelement von 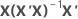 |
| X | Versuchsplanmatrix |
 | i-ter angepasster Wert der Antwortvariablen |
 | angepasster Wert, berechnet ohne die i-te Beobachtung |
| MSE (i) | mittlerer quadrierter Fehler, berechnet ohne die i-te Beobachtung |
| n | Anzahl der Beobachtungen |
| p | Anzahl der Modellparameter |
Varianzinflationsfaktor (VIF)
Der VIF lässt sich durch Regression der einzelnen Prädiktoren auf die jeweils übrigen Prädiktoren und Aufzeichnen des R2 berechnen.
Formel
Für Prädiktor xj lautet der VIF:

Notation
| Begriff | Beschreibung |
|---|---|
| R2( xj) | Determinationskoeffizient mit xj als Antwortvariable und den anderen Termen im Modell als Prädiktoren |
Durbin-Watson-Statistik
Hiermit wird ein Test auf Autokorrelation in den Residuen durchgeführt, indem ermittelt wird, ob die Korrelation zwischen zwei benachbarten Fehlertermen null ist. Dieser Test basiert auf der Annahme, dass Fehler von einem autoregressiven Prozess erster Ordnung erzeugt werden. Minitab nimmt an, dass die Beobachtungen in einer sinnvollen Reihenfolge vorliegen, z. B. in zeitlicher Reihenfolge.

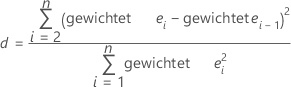
Notation
| Begriff | Beschreibung |
|---|---|
| ei | i-tes Residuum |
| ei – 1 | Residuum für die vorherige Beobachtung |
| n | Anzahl der Beobachtungen |