In diesem Thema
Koeffizienten
[1] P. McCullagh und J. A. Nelder (1989). Generalized Linear Models, 2nd Ed., Chapman & Hall/CRC, London.
Standardfehler der Koeffizienten
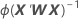
W ist eine Diagonalmatrix, bei der die Diagonalelemente mit der folgenden Formel angegeben werden:
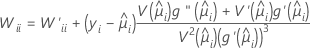
Dabei gilt Folgendes:

Diese Varianz-Kovarianz-Matrix beruht nicht auf der Fisher-Informationsmatrix, sondern auf der beobachteten Hesse-Matrix. Minitab verwendet die beobachtete Hesse-Matrix, da das resultierende Modell robuster gegenüber fehlerhaften Angaben der bedingten Mittelwerte ist.
Wenn die kanonische Linkfunktion verwendet wird, sind die beobachtete Hesse-Matrix und die Fisher-Informationsmatrix identisch.
Notation
| Begriff | Beschreibung |
|---|---|
| yi | Wert der Antwortvariablen für die i-te Zeile |
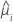 | geschätzter Mittelwert der Antwortvariablen für die i-te Zeile |
| V(·) | Varianzfunktion aus der folgenden Tabelle |
| g(·) | Linkfunktion |
| V '(·) | erste Ableitung der Varianzfunktion |
| g'(·) | erste Ableitung der Linkfunktion |
| g''(·) | zweite Ableitung der Linkfunktion |
Die Varianzfunktion hängt vom Modell ab:
| Modell | Varianzfunktion |
| Binomial | 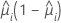 |
| Poisson | 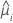 |
Weitere Informationen finden Sie unter [1] und [2].
[1] A. Agresti (1990). Categorical Data Analysis. John Wiley & Sons, Inc.
[2] P. McCullagh und J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.
z
Mit der z-Statistik wird ermittelt, ob die Beziehung zwischen dem Prädiktor und der Antwortvariablen signifikant ist. Größere Absolutwerte von z weisen auf eine signifikante Beziehung hin. Die Formel lautet wie folgt:
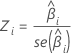
Notation
| Begriff | Beschreibung |
|---|---|
| Zi | Teststatistik für eine Standardnormalverteilung |
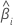 | Geschätzter Koeffizient |
 | Standardfehler des geschätzten Koeffizienten |
Bei kleinen Stichproben ist der Likelihood-Quotienten-Test möglicherweise zuverlässiger zum Erkennen der Signifikanz. Die p-Werte für den Likelihood-Quotienten befinden sich in der Abweichungstabelle. Wenn der Stichprobenumfang ausreichend groß ist, nähern sich die p-Werte für die z-Statistik den p-Werten für die Likelihood-Quotienten-Statistik an.
p-Wert (p)
p-Werte werden in Hypothesentests verwendet, um Ihnen die Entscheidung zu ermöglichen, ob eine Nullhypothese zurückgewiesen oder nicht zurückgewiesen werden sollte. Der p-Wert stellt die Wahrscheinlichkeit dar, eine Teststatistik zu erhalten, die mindestens so extrem wie der tatsächlich berechnete Wert ist, wenn die Nullhypothese wahr ist. Ein häufig verwendeter Trennwert für den p-Wert ist 0,05. Wenn beispielsweise der berechnete p-Wert einer Teststatistik kleiner als 0,05 ist, weisen Sie die Nullhypothese zurück.
Konfidenzintervall
Das Konfidenzintervall bei großen Stichproben für einen geschätzten Koeffizienten lautet:
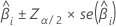
Bei der binären logistischen Regression stellt Minitab Konfidenzintervalle für die Chancenverhältnisse bereit. Um das Konfidenzintervall für das Chancenverhältnis zu erhalten, potenzieren Sie die Unter- und die Obergrenze des Konfidenzintervalls. Das Intervall gibt den Bereich an, in dem die Chance für jede Änderung des Prädiktors um eine Einheit liegen kann.
Notation
| Begriff | Beschreibung |
|---|---|
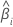 | i-ter Koeffizient |
 | inverse kumulative Wahrscheinlichkeit der Standardnormalverteilung bei 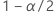 |
 | Signifikanzniveau |
 | Standardfehler des geschätzten Koeffizienten |
Varianz-Kovarianz-Matrix
Hierbei handelt es sich um eine d x d-Matrix, wobei d die Anzahl der Prädiktoren plus eins ist. Die Varianz jedes Koeffizienten befindet sich in der Diagonalzelle, und die Kovarianz jedes Koeffizientenpaars befindet sich in der entsprechenden nicht diagonalen Zelle. Die Varianz ist der quadrierte Standardfehler des Koeffizienten.
Die Varianz-Kovarianz-Matrix stammt aus der letzten Iteration der Umkehrung der Informationsmatrix. Die Varianz-Kovarianz-Matrix hat die folgende Form:
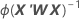
W ist eine Diagonalmatrix, bei der die Diagonalelemente mit der folgenden Formel angegeben werden:

Dabei gilt Folgendes:

Diese Varianz-Kovarianz-Matrix beruht nicht auf der Fisher-Informationsmatrix, sondern auf der beobachteten Hesse-Matrix. Minitab verwendet die beobachtete Hesse-Matrix, da das resultierende Modell robuster gegenüber fehlerhaften Angaben der bedingten Mittelwerte ist.
Wenn die kanonische Linkfunktion verwendet wird, sind die beobachtete Hesse-Matrix und die Fisher-Informationsmatrix identisch.
Notation
| Begriff | Beschreibung |
|---|---|
| yi | Wert der Antwortvariablen für die i-te Zeile |
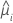 | geschätzter Mittelwert der Antwortvariablen für die i-te Zeile |
| V(·) | Varianzfunktion aus der folgenden Tabelle |
| g(·) | Linkfunktion |
| V '(·) | erste Ableitung der Varianzfunktion |
| g'(·) | erste Ableitung der Linkfunktion |
| g''(·) | zweite Ableitung der Linkfunktion |
Die Varianzfunktion hängt vom Modell ab:
| Modell | Varianzfunktion |
| Binomial | 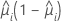 |
| Poisson | 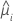 |
Weitere Informationen finden Sie in [1] und [2].
[1] A. Agresti (1990). Categorical Data Analysis. John Wiley & Sons, Inc.
[2] P. McCullagh und J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.