R-Qd der Abweichung
Das R2 der Abweichung wird im Allgemeinen als Anteil der Gesamtabweichung der Antwortvariablen angesehen, der vom Modell erklärt wird.
Interpretation
Je höher das R2 der Abweichung ausfällt, desto besser ist das Modell an die Daten angepasst. Das R2 der Abweichung liegt immer zwischen 0 % und 100 %.
Das R2 der Abweichung nimmt beim Einbinden zusätzlicher Terme in ein Modell stets zu. Das beste Modell mit fünf Termen weist beispielsweise immer ein R2 auf, das mindestens so hoch wie das des besten Modells mit vier Termen ist. Daher ist das R2 der Abweichung am nützlichsten, wenn Sie Modelle derselben Größe vergleichen.
Statistiken für die Güte der Anpassung sind nur eines der Maße für die Güte der Anpassung des Modells an die Daten. Selbst wenn ein Modell einen erwünschten Wert aufweist, sollten Sie die Residuendiagramme und die Tests auf Güte der Anpassung untersuchen, um zu beurteilen, wie gut das Modell an die Daten angepasst ist.
Sie können eine Darstellung der Anpassungslinie verwenden, um verschiedene Werte des R2 der Abweichung grafisch zu veranschaulichen. Das erste Diagramm zeigt ein Modell, das ungefähr 96 % der Abweichung in der Antwortvariablen erklärt. Das zweite Diagramm zeigt ein Modell, das ungefähr 60 % der Abweichung in der Antwortvariablen erklärt. Je mehr der Abweichung durch das Modell erklärt wird, desto näher liegen die Datenpunkte an der Kurve. Würde ein Modell theoretisch 100 % der Abweichung erklären, wären die angepassten Werte immer gleich den beobachteten Werten, und alle Datenpunkte würden auf der Kurve liegen.
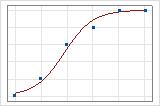
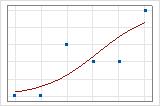
Die Anordnung der Daten beeinflusst den Wert des R2 der Abweichung. Das R2 der Abweichung ist im Allgemeinen für Daten mit mehreren Versuchen pro Zeile höher als für Daten mit einem einzigen Versuch pro Zeile. Werte des R2 der Abweichung sind nur bei Modellen vergleichbar, in denen dasselbe Datenformat verwendet wird. Weitere Informationen finden Sie unter Wie wirken sich Datenformate bei der binären logistischen Regression auf die Güte der Anpassung aus?.
R-Qd (kor) der Abweichung
Das korrigierte R2 der Abweichung ist der Anteil der Abweichung der Antwortvariablen, der durch das Modell erklärt wird, korrigiert nach der Anzahl der Prädiktoren im Modell in Bezug auf die Anzahl der Beobachtungen.
Interpretation
Verwenden Sie das korrigierte R2 der Abweichung, wenn Sie Modelle vergleichen möchten, die eine unterschiedliche Anzahl von Termen enthalten. Das R2 der Abweichung nimmt beim Einbinden eines Terms in das Modell stets zu. Der Wert des korrigierten R2 der Abweichung berücksichtigt die Anzahl der Terme im Modell, was die Auswahl des richtigen Modells erleichtert.
| Treppenförmig | %Kartoffel | Abkühlgeschwindigkeit | Frittiertemperatur | R2 der Abweichung | Korrigiertes R2 der Abweichung | p-Wert |
|---|---|---|---|---|---|---|
| 1 | X | 0,000 | ||||
| 1 | X | X | 63 | 0,000 | ||
| 3 | X | X | X | 65 | = | 0,000 |
Der erste Schritt ergibt ein statistisch signifikantes Regressionsmodell. Im zweiten Schritt wird dem Modell die Abkühlgeschwindigkeit hinzugefügt; dadurch nimmt das korrigierte R2 der Abweichung zu, was darauf hinweist, dass die Abkühlgeschwindigkeit das Modell verbessert. Im dritten Schritt, in dem die Frittiertemperatur zum Modell hinzugefügt wird, nimmt das R2 der Abweichung, nicht aber das korrigierte R2 der Abweichung zu. Diese Ergebnisse deuten darauf hin, dass das Modell durch „Frittiertemperatur“ nicht verbessert wird. Auf der Grundlage dieser Ergebnisse erwägen Sie, „Frittiertemperatur“ aus dem Modell zu entfernen.
Die Anordnung der Daten beeinflusst den Wert des korrigierten R2 der Abweichung. Bei den gleichen Daten ist das korrigierte R2 der Abweichung im Allgemeinen für Daten mit mehreren Versuchen pro Zeile höher als für Daten mit einem einzigen Versuch pro Zeile. Verwenden Sie das korrigierte R2 der Abweichung nur zum Vergleichen der Anpassung von Modellen, die dasselbe Datenformat aufweisen. Weitere Informationen finden Sie unter Wie wirken sich Datenformate bei der binären logistischen Regression auf die Güte der Anpassung aus?.
AIC, AICc und BIC
Akaikes Informationskriterium (AIC), Akaikes korrigiertes Informationskriterium (AICc) und das Bayessche Informationskriterium (BIC) sind Maße der relativen Qualität eines Modells, bei denen sowohl die Anpassung als auch die Anzahl der Terme im Modell berücksichtigt werden.
Interpretation
Für Darstellung der binären Anpassungslinie können Sie anhand der Informationskriterien die Anpassung der verschiedenen Linkfunktionen oder verschiedenen Prädiktoren vergleichen. Erwünscht sind kleinere Werte. Das Modell mit dem kleinsten Wert ist jedoch nicht zwangsläufig gut an die Daten angepasst. Verwenden Sie auch den Test und die Residuendiagramme, um zu beurteilen, wie gut das Modell an die Daten angepasst ist.