Variablen
„Variablen“ gibt die Anzahl der in jedem Modell enthaltenen Prädiktoren an. Für jede Anzahl von Prädiktoren wählt Minitab standardmäßig die zwei Modelle mit den höchsten R2-Werten aus. Auf der rechten Seite der Tabelle wird durch ein „X“ angezeigt, welche Prädiktoren im Modell enthalten sind.
Antwortvariable ist Wärmefluss
| Variablen | R-Qd | R-Qd(kor) | R-Qd(prog) | Mallows-Cp | S | I s o l i e r u n g | O s t | S ü d | N o r d | T a g e s z e i t |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 72,1 | 71,0 | 66,9 | 38,5 | 12,328 | X | ||||
| 1 | 39,4 | 37,1 | 26,3 | 112,7 | 18,154 | X | ||||
| 2 | 85,9 | 84,8 | 81,4 | 9,1 | 8,9321 | X | X | |||
| 2 | 82,0 | 80,6 | 74,2 | 17,8 | 10,076 | X | X | |||
| 3 | 87,4 | 85,9 | 79,0 | 7,6 | 8,5978 | X | X | X | ||
| 3 | 86,5 | 84,9 | 81,4 | 9,7 | 8,9110 | X | X | X | ||
| 4 | 89,1 | 87,3 | 80,6 | 5,8 | 8,1698 | X | X | X | X | |
| 4 | 88,0 | 86,0 | 79,3 | 8,2 | 8,5550 | X | X | X | X | |
| 5 | 89,9 | 87,7 | 78,8 | 6,0 | 8,0390 | X | X | X | X | X |
R-Quadrat
R2 ist der Prozentsatz der Streuung in der Antwortvariablen, der durch das Modell erklärt wird. Sie wird berechnet als 1 minus das Verhältnis der Fehlersumme der Quadrate (was die Variation ist, die vom Modell nicht erklärt wird) zur Gesamtsumme der Quadrate (die die Gesamtvariation im Modell darstellt).
Interpretation
Verwenden Sie das R2, um zu bestimmen, wie gut das Modell für Ihre Daten passend ist. Je höher das R2, desto besser ist das Modell für Ihre Daten passend. R2 liegt immer zwischen 0 % und 100 %.
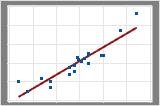
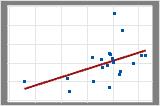
- Der Wert von R2 nimmt beim Einbinden zusätzlicher Prädiktoren in das Modell stets zu. Das beste Modell mit fünf Prädiktoren weist beispielsweise immer ein R2 auf, das mindestens so hoch wie das des besten Modells mit vier Prädiktoren ist. Daher ist R2 am nützlichsten, wenn Sie Modelle derselben Größe vergleichen.
- Kleine Stichproben ermöglichen keinen genauen Schätzwert für die Stärke der Beziehung zwischen der Antwortvariablen und den Prädiktoren. Wenn z. B. das R2 genauer sein muss, sollten Sie einen größeren Stichprobenumfang (im Allgemeinen 40 oder mehr) wählen.
- Statistiken für die Güte der Anpassung sind nur eines der Maße für die Güte der Anpassung des Modells an die Daten. Selbst wenn ein Modell einen erwünschten Wert aufweist, sollten Sie die Residuendiagramme untersuchen, um sich zu vergewissern, dass das Modell die Modellannahmen erfüllt.
R-Qd(kor)
Das korrigierte R2 gibt den Prozentsatz der Streuung der Antwortvariablen an, der vom Modell erklärt wird, korrigiert nach der Anzahl der Prädiktoren im Modell in Bezug auf die Anzahl der Beobachtungen. Das korrigierte R2 wird als 1 minus dem Verhältnis zwischen dem mittleren quadrierten Fehler (MSE) und dem Gesamtmittel der Quadrate (MS Gesamt) berechnet.
Interpretation
Verwenden Sie das korrigierte R2, wenn Sie Modelle vergleichen möchten, die eine unterschiedliche Anzahl von Prädiktoren enthalten. R2 nimmt stets zu, wenn Sie einen zusätzlichen Prädiktor in das Modell aufnehmen, selbst wenn damit keine tatsächliche Verbesserung des Modells verbunden ist. Der Wert des korrigierten R2 berücksichtigt die Anzahl der Prädiktoren im Modell, so dass Ihnen das Auswählen des richtigen Modells erleichtert wird.
| Modell | %Kartoffel | Abkühlgeschwindigkeit | Frittiertemperatur | R2 | korrigiertes R2 |
|---|---|---|---|---|---|
| 1 | X | 52 | |||
| 1 | X | X | 63 | 62 | |
| 3 | X | X | X |
Das erste Modell ergibt ein R2 von über 50 %. Beim zweiten Modell wird der Prädiktor „Abkühlgeschwindigkeit“ hinzugefügt. Das korrigierte R2 nimmt zu, und dies weist darauf hin, dass „Abkühlgeschwindigkeit“ das Modell verbessert. Im dritten Modell, bei dem der Prädiktor „Frittiertemperatur“ hinzugefügt wird, nimmt das R2 zu, jedoch nicht das korrigierte R2. Diese Ergebnisse deuten darauf hin, dass das Modell durch „Frittiertemperatur“ nicht verbessert wird. Auf der Grundlage dieser Ergebnisse erwägen Sie, „Frittiertemperatur“ aus dem Modell zu entfernen.
PRESS
Die Summe der quadrierten Prognosefehler (PRESS) ist ein Maß der Abweichung zwischen den angepassten Werten und den beobachteten Werten. PRESS ähnelt der Summe der Quadrate der Residuenfehler (SSE), d. h. der Summe der quadrierten Residuen. Die Berechnung der Residuen für PRESS erfolgt jedoch nach einem anderen Verfahren. PRESS wird mit einer Formel berechnet, die diesem Verfahren entspricht: Jede einzelne Beobachtung wird systematisch aus dem Datensatz entfernt, die Regressionsgleichung wird geschätzt, und es wird ermittelt, wie genau das Modell die entfernte Beobachtung prognostiziert.
Interpretation
Verwenden Sie PRESS, um die Prognosefähigkeit des Modells zu beurteilen. Im Allgemeinen gilt: Je kleiner der PRESS-Wert, desto besser ist die Prognosefähigkeit des Modells. Minitab verwendet PRESS, um das prognostizierte R2 zu berechnen, das im Allgemeinen intuitiver zu interpretieren ist. Kombiniert können diese Statistiken eine übermäßige Anpassung des Modells verhindern. Ein übermäßig angepasstes Modell liegt vor, wenn Sie Terme für Effekte hinzufügen, die in der Grundgesamtheit unbedeutend sind, obwohl sie in den Stichprobendaten als wichtig erscheinen. Das Modell wird somit an die Stichprobendaten angepasst und ist daher möglicherweise beim Aufstellen von Prognosen für die Grundgesamtheit nicht nützlich.
R-Qd(prog)
Das prognostizierte R2 wird mit einer Formel berechnet, die diesem Verfahren entspricht: Jede einzelne Beobachtung wird systematisch aus dem Datensatz entfernt, die Regressionsgleichung wird geschätzt, und es wird ermittelt, wie genau das Modell die jeweils entfernte Beobachtung prognostiziert. Der Wert des prognostizierten R2 liegt im Bereich von 0 % bis 100 %. (Obwohl die Berechnungen für das prognostizierte R2 negative Werte ergeben können, zeigt Minitab in derartigen Fällen null an.)
Interpretation
Verwenden Sie das prognostizierte R2, um zu ermitteln, wie genau das Modell Werte der Antwortvariablen für neue Beobachtungen prognostiziert. Modelle mit einem höheren prognostizierten R2 zeichnen sich durch eine bessere Prognosefähigkeit aus.
Ein prognostiziertes R2, das wesentlich kleiner als R2 ist, kann auf eine übermäßige Anpassung des Modells hinweisen. Ein übermäßig angepasstes Modell liegt vor, wenn Sie Terme für Effekte hinzufügen, die in der Grundgesamtheit unbedeutend sind. Das Modell wird somit an die Stichprobendaten angepasst und ist daher möglicherweise beim Aufstellen von Prognosen für die Grundgesamtheit nicht nützlich.
Das prognostizierte R2 kann zudem beim Vergleichen von Modellen nützlicher als das korrigierte R2 sein, da der Wert mit Beobachtungen berechnet wird, die in der Modellberechnung nicht enthalten sind.
Ein Analytiker bei einem Finanzberatungsunternehmen entwickelt beispielsweise ein Modell zum Prognostizieren künftiger Marktbedingungen. Das Modell sieht vielversprechend aus, denn es weist ein R2 von 87 % auf. Das prognostizierte R2 beträgt hingegen lediglich 52 %, was darauf hinweist, dass das Modell möglicherweise übermäßig angepasst ist.
Mallows-Cp
Mallows-Cp kann Sie dabei unterstützen, eine Auswahl zwischen mehreren konkurrierenden Regressionsmodellen zu treffen. Das Mallows-Cp stellt einen Vergleich zwischen dem vollständigen Modell und Modellen mit Teilmengen von Prädiktoren dar. Dieses Maß unterstützt Sie beim Ermitteln einer ausgeglichenen Anzahl von Prädiktoren im Modell. Ein Modell mit zu vielen Prädiktoren kann relativ ungenau sein, während ein Modell mit zu wenigen Prädiktoren verzerrte Schätzwerte ergeben kann. Ein Vergleich von Regressionsmodellen unter Verwendung des Mallows-Cp ist nur gültig, wenn Sie mit dem gleichen vollständigen Satz von Prädiktoren beginnen.
Interpretation
Ein Mallows-Cp, das annähernd gleich der Anzahl der Prädiktoren plus der Konstanten ist, weist darauf hin, dass das Modell relativ genaue und unverzerrte Schätzwerte liefert.
Ein Mallows-Cp, das größer als die Anzahl der Prädiktoren plus der Konstanten ist, weist darauf hin, dass das Modell verzerrt und nicht gut an die Daten angepasst ist.
S
S stellt die Standardabweichung der Distanz zwischen den Datenwerten und den angepassten Werten dar. S wird in der Maßeinheit der Antwortvariablen ausgedrückt.
Interpretation
Verwenden Sie S, um zu ermitteln, wie genau das Modell die Antwortvariable beschreibt. S wird in der Maßeinheit der Antwortvariablen ausgedrückt und stellt den Abstand der Datenwerte von den angepassten Werten dar. Je niedriger der Wert von S, desto genauer beschreibt das Modell die Antwortvariable. Ein niedriger Wert von S allein bedeutet jedoch nicht zwangsläufig, dass das Modell die Modellannahmen erfüllt. Prüfen Sie die Annahmen anhand der Residuendiagramme.
Angenommen, Sie sind für einen Hersteller von Kartoffelchips tätig, der die Faktoren untersucht, die den Prozentsatz der zerkrümelten Kartoffelchips in jeder Packung beeinflussen. Sie reduzieren das Modell auf die signifikanten Prädiktoren, und für S wird der Wert 1,79 berechnet. Dieses Ergebnis gibt an, dass die Standardabweichung der Datenpunkte um die angepassten Werte 1,79 beträgt. Beim Vergleichen von Modellen weisen Werte kleiner als 1,79 auf eine bessere und Werte größer als 1,79 auf eine schlechtere Anpassung hin.
AICc und BIC
Akaikes korrigiertes Informationskriterium (AICc) und das Bayessche Informationskriterium (BIC) sind Maße der relativen Qualität eines Modells, bei dem sowohl die Anpassung als auch die Anzahl der Terme im Modell berücksichtigt werden.
Interpretation
Anhand des AICc und des BIC können Sie verschiedene Modelle vergleichen. Erwünscht sind kleinere Werte. Das Modell mit dem kleinsten Wert für eine Gruppe von Prädiktoren ist jedoch nicht zwangsläufig gut an die Daten angepasst. Verwenden Sie auch die Tests und Residuendiagramme, um zu beurteilen, wie gut das Modell an die Daten angepasst ist.
Sowohl AICc als auch BIC werten die Likelihood des Modells aus und wenden dann einen Abzug für das Hinzufügen von Termen zum Modell an. Durch den Abzug wird die Tendenz zur Überanpassung des Modells an die Stichprobendaten reduziert. Durch diese Reduzierung kann ein Modell zustande kommen, das insgesamt eine bessere Leistung erbringt.
Als Faustregel gilt: Wenn die Anzahl der Parameter im Verhältnis zum Stichprobenumfang klein ist, ist der Abzug für das Hinzufügen der einzelnen Parameter für BIC größer als für AICc. In diesen Fällen ist das Modell, bei dem BIC minimiert wird, tendenziell kleiner als das Modell, bei dem AICc minimiert wird.
In einigen gängigen Fällen, z. B. bei Screening-Versuchsplänen, ist die Anzahl der Parameter im Verhältnis zum Stichprobenumfang in der Regel groß. In diesen Fällen ist das Modell, bei dem AICc minimiert wird, tendenziell kleiner als das Modell, bei dem BIC minimiert wird. Bei einem definitiven Screening-Versuchsplan mit 13 Durchläufen ist beispielsweise in der Gruppe der Modelle mit 6 oder mehr Parametern das Modell, bei dem AICc minimiert wird, tendenziell kleiner als das Modell, bei dem BIC minimiert wird.
Weitere Informationen zu AICc und BIC finden Sie in Burnham und Anderson.1
Bedingungszahl
Die Bedingungszahl drückt die Multikollinearität zwischen Modelltermen aus. Multikollinearität ist eine Bedingung, die eintritt, wenn Terme im Modell mit anderen Termen korrelieren. Beim Vergleich von Modellen ist eine kleinere Bedingungszahl besser.
Interpretation
Verwenden Sie die Bedingungszahl, um Modelle mit unterschiedlichen Termen miteinander zu vergleichen. Die Bedingungszahl 1 gibt an, dass die Modellterme unkorreliert sind. Größere Werte weisen auf eine höhere Multikollinearität hin.
Während die Auswirkungen einer bestimmten Bedingungszahl von verschiedenen Bedingungen abhängen, weisen Werte über 100 in der Regel darauf hin, dass eine nähere Untersuchung erforderlich ist. Wenn Terme im Modell multikollinear sind, ist die Interpretation des Modells komplizierter als bei einem Modell mit unkorrelierten Termen. Weitere Informationen finden Sie unter Multikollinearität bei der Regression.
In diesen Ergebnissen ist die Bedingungszahl 1, wenn das Modell nur einen Term aufweist. (Die Bedingungszahl ist immer 1, wenn das Modell einen stetigen Prädiktor aufweist.) Keines der Modelle weist eine Bedingungszahl größer als 100 auf; es ist also unwahrscheinlich, dass die Multikollinearität unter den Prädiktoren große Auswirkungen auf die Ergebnisse hat.
Antwortvariable ist Wärmefluss
| Variablen | R-Qd | R-Qd(kor) | PRESS | R-Qd(prog) | Mallows-Cp | S | AICc | BIC | Bed.-Nr. | I s o l i e r u n g | O s t | S ü d | N o r d | T a g e s z e i t |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 72,1 | 71,0 | 4855,9 | 66,9 | 38,5 | 12,328 | 232,873 | 236,015 | 1,000 | X | ||||
| 1 | 39,4 | 37,1 | 10822,6 | 26,3 | 112,7 | 18,154 | 255,321 | 258,463 | 1,000 | X | ||||
| 2 | 85,9 | 84,8 | 2736,5 | 81,4 | 9,1 | 8,9321 | 215,798 | 219,600 | 1,807 | X | X | |||
| 2 | 82,0 | 80,6 | 3786,4 | 74,2 | 17,8 | 10,076 | 222,788 | 226,590 | 5,344 | X | X | |||
| 3 | 87,4 | 85,9 | 3089,7 | 79,0 | 7,6 | 8,5978 | 215,390 | 219,618 | 2,428 | X | X | X | ||
| 3 | 86,5 | 84,9 | 2725,9 | 81,4 | 9,7 | 8,9110 | 217,466 | 221,693 | 5,141 | X | X | X | ||
| 4 | 89,1 | 87,3 | 2847,2 | 80,6 | 5,8 | 8,1698 | 214,454 | 218,840 | 5,988 | X | X | X | X | |
| 4 | 88,0 | 86,0 | 3045,7 | 79,3 | 8,2 | 8,5550 | 217,127 | 221,512 | 20,427 | X | X | X | X | |
| 5 | 89,9 | 87,7 | 3109,9 | 78,8 | 6,0 | 8,0390 | 215,799 | 220,037 | 22,614 | X | X | X | X | X |