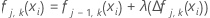TreeNet®-Modelle stellen einen Ansatz zum Beheben von Klassifizierungs- und Regressionsproblemen dar, die sowohl genauer als ein einzelner Klassifizierungs- oder Regressionsbaum als auch resistent gegen übermäßige Anpassung sind. Die grobe, allgemeine Beschreibung des Prozesses ist, dass ein kleiner Regressionsbaum das Ausgangsmodell darstellt. Aus diesem Baum ergeben sich Residuen für jede Zeile in den Daten, die zur Antwortvariablen für den nächsten Regressionsbaum werden. Anschließend wird ein weiterer kleiner Regressionsbaum erstellt, um die Residuen aus dem ersten Baum zu prognostizieren und die resultierenden Residuen zu berechnen. Diese Sequenz wiederholen wir, bis eine optimale Anzahl von Bäumen mit minimalem Prädiktionsfehler mithilfe einer Validierungsmethode identifiziert ist. Die resultierende Reihenfolge der Bäume ergibt das TreeNet® Klassifikationsmodell.
Für die Klassifizierung könnten einige weitere mathematische Details für eine Analyse mit einer binären Antwortvariablen und für eine Analyse mit einer multinomialen Antwortvariablen hinzugefügt werden.
Binäre Antwortvariable
Bei der Erstellung des Modells werden die folgenden Informationen verwendet:
Die Antwortvariable, , nimmt die folgenden Werte an: {-1; 1}.
Die anfänglichen angepassten Werte für die Berechnung der verallgemeinerten Residuen weisen die folgende Form auf:
Dabei gilt: ist die Anzahl der Ereignisse und ist die Anzahl der Nicht-Ereignisse.
Bei der Modellerstellung werden außerdem die folgenden Eingaben des Analytikers verwendet:
Eingabe
Symbol
Trainingsrate
Stichprobenrate
maximale Anzahl der Endknoten pro Baum
Anzahl der Bäume
Der Prozess umfasst die folgenden allgemeinen Schritte zum Aufbau des j-ten Baumes, j=1,..., J:
Zeichnen Sie aus den Trainingsdaten eine Zufallsstichprobe der Größe s * N, wobei N die Anzahl der Zeilen in den Trainingsdaten ist.
Berechnen Sie die verallgemeinerten Residuen, gi, j für :
Dabei gilt Folgendes:
und ist ein Vektor, der die i.-te Zeile der Prädiktorwerte in den Trainingsdaten darstellt.
Passen Sie einen Regressionsbaum mit höchstens M-Endknoten an die generalisierten Residuen an. Der Baum unterteilt die Beobachtungen in höchstens M sich gegenseitig ausschließende Gruppen.
Berechnen Sie für den m-ten Endknoten in der Regressionsstruktur die Aktualisierungen innerhalb des Knotens für angepasste Werte aus dem vorherigen Baum wie folgt:
Dabei gilt Folgendes:
Begriff
Beschreibung
Anzahl der Ereignisse im Endknoten m bei Baum j
Anzahl der Fälle im Endknoten m bei Baum j
arithmetisches Mittel von für alle Fälle im Endknoten m bei Baum j
Reduzieren Sie die Aktualisierungen innerhalb der Knoten um die Trainingsrate, und wenden Sie die Werte an, um die aktualisierten angepassten Werte fj(xi) zu erhalten:
Wiederholen Sie die Schritte 1–5 für jeden der J-Bäume in der Analyse.
Multinomiale Antwortvariable
Für eine multinomiale Antwortvariable mit K Stufen passt die Analyse bei jeder Iteration einen Baum auf jeder Stufe der Antwortvariablen an. Die anfänglich angepassten Werte für die Berechnung der verallgemeinerten Residuen für einen der Bäume weist die folgende Form auf:
Dabei gilt: ist die Anzahl der Fälle, in denen der Antwortwert k und N die Anzahl der Zeilen in den Trainingsdaten ist.
Bei der Modellerstellung werden außerdem die folgenden Eingaben des Analytikers verwendet:
Eingabe
Symbol
Trainingsrate
Stichprobenrate
maximale Anzahl der Endknoten pro Baum
Anzahl der Bäume
Die Berechnung der Wahrscheinlichkeiten aus den Anpassungen berücksichtigt die Abhängigkeit dieser Bäume. Andernfalls ist der Prozess im Wesentlichen derselbe wie für den binären Fall.
Ziehen Sie eine Zufallsstichprobe mit dem Umfang s * N aus den Trainingsdaten, wobei N die Anzahl der Zeilen im Trainingsdatensatz ist.
Berechnen Sie die verallgemeinerten Residuen, gi, j, k für , ist die Anzahl der Bäume in der Analyse und ist die Anzahl der Stufen der Antwortvariablen:
Dabei gilt Folgendes:
und ist ein Vektor, der die i-te Zeile der Prädiktorwerte im Trainingsdatensatz darstellt.
Beispielsweise hat die Wahrscheinlichkeit für ein als 1 kodiertes Ergebnis aus einer multinomialen Antwort mit 3 Stufen die folgende Form:
Dabei gilt: ist die Anpassung für die i-te Zeile am j–1-Baum für die k-te Stufe der Antwortvariablen.
Passen Sie einen Regressionsbaum mit höchstens M-Endknoten an die generalisierten Residuen an. Der Baum unterteilt die Beobachtungen in höchstens M sich gegenseitig ausschließende Gruppen.
Berechnen Sie für den m-ten Endknoten im j-ten Regressionsbaum die Aktualisierungen innerhalb des Knotens für angepasste Werte aus dem vorherigen Baum wie folgt:
Dabei gilt Folgendes:
Begriff
Beschreibung
Anzahl der Fälle für Kategorie k im Endknoten m bei Baum j
Anzahl der Fälle im Endknoten m bei Baum j
arithmetisches Mittel von für alle Fälle im Endknoten m bei Baum j.
Reduzieren Sie die Aktualisierungen innerhalb der Knoten um die Trainingsrate, und wenden Sie die Werte an, um die aktualisierten angepassten Werte fj, k, m(xi) zu erhalten:
Wiederholen Sie die Schritte 1–5 für jeden der J-Bäume in der Analyse und für jede der K-Ebenen der Antwortvariablen.
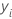 , nimmt die folgenden Werte an: {-1; 1}.
, nimmt die folgenden Werte an: {-1; 1}.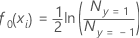
 ist die Anzahl der Ereignisse und
ist die Anzahl der Ereignisse und  ist die Anzahl der Nicht-Ereignisse.
ist die Anzahl der Nicht-Ereignisse.
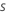
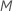
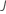
 :
:
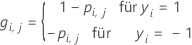

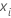 ist ein Vektor, der die i.-te Zeile der Prädiktorwerte in den Trainingsdaten darstellt.
ist ein Vektor, der die i.-te Zeile der Prädiktorwerte in den Trainingsdaten darstellt.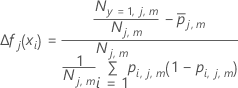 Dabei gilt Folgendes:
Dabei gilt Folgendes:

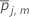
 für alle Fälle im Endknoten m bei Baum j
für alle Fälle im Endknoten m bei Baum j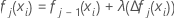
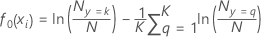
 ist die Anzahl der Fälle, in denen der Antwortwert k und N die Anzahl der Zeilen in den Trainingsdaten ist.
ist die Anzahl der Fälle, in denen der Antwortwert k und N die Anzahl der Zeilen in den Trainingsdaten ist.
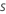
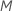
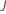
 ,
,  ist die Anzahl der Bäume in der Analyse und
ist die Anzahl der Bäume in der Analyse und 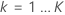 ist die Anzahl der Stufen der Antwortvariablen:
ist die Anzahl der Stufen der Antwortvariablen:
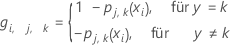
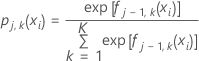
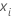 ist ein Vektor, der die i-te Zeile der Prädiktorwerte im Trainingsdatensatz darstellt.Beispielsweise hat die Wahrscheinlichkeit für ein als 1 kodiertes Ergebnis aus einer multinomialen Antwort mit 3 Stufen die folgende Form:Dabei gilt:
ist ein Vektor, der die i-te Zeile der Prädiktorwerte im Trainingsdatensatz darstellt.Beispielsweise hat die Wahrscheinlichkeit für ein als 1 kodiertes Ergebnis aus einer multinomialen Antwort mit 3 Stufen die folgende Form:Dabei gilt: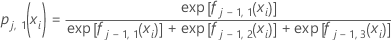
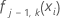 ist die Anpassung für die i-te Zeile am j–1-Baum für die k-te Stufe der Antwortvariablen.
ist die Anpassung für die i-te Zeile am j–1-Baum für die k-te Stufe der Antwortvariablen.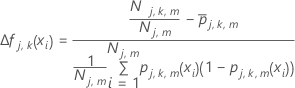
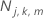

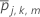
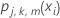 für alle Fälle im Endknoten m bei Baum j.
für alle Fälle im Endknoten m bei Baum j.