Hinweis
Dieser Befehl ist mit dem Predictive Analytics-Modul verfügbar. Klicken Sie hier, um weitere Informationen zum Aktivieren des Moduls zu erhalten.
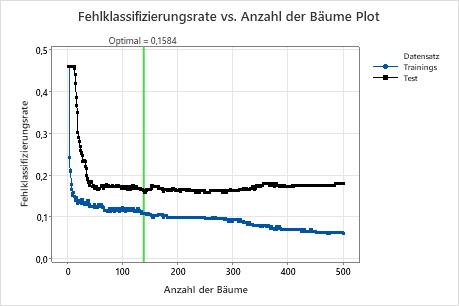
Das Diagramm der Fehlklassifizierungsrate vs. Anzahl der Bäume zeigt die Fehlklassifizierungsrate auf der y-Achse und die Anzahl der Bäume auf der x-Achse an. Die minimale Fehlklassifikationsquote gibt an, ob das Modell ein guter Klassifikator ist. Verwenden Sie die Testergebnisse, um die Fähigkeit des Modells zum Prognostizieren neuer Beobachtungen auszuwerten. Vergleichen Sie die Trainingsergebnisse und die Testergebnisse, um festzustellen, ob es Probleme mit dem Modell in Bezug auf eine übermäßige Anpassung an den Trainingsdatensatz gibt.
Wenn die Fläche unter der ROC-Kurve die Anzahl der Bäume für das optimale Modell bestimmt, zeigt Minitab das Diagramm der Fläche unterhalb der ROC-Kurve vs. Anzahl der Bäume an. Wenn der Maximum-Likelihood-Wert die Anzahl der Bäume für das optimale Modell bestimmt, zeigt Minitab das Diagramm der durchschnittlichen –Log-Likelihood vs. Anzahl der Bäume an.
Interpretation
Die Fehlklassifizierungsraten müssen ≥ 0 sein. Je niedriger die Werte, desto besser ist das Klassifikationsmodell. Die Referenzlinie gibt die optimale Fehlklassifizierungsrate für die Testdaten und die Anzahl der Bäume im Modell an. Wenn die Testkurve auf ein unzureichendes Modell hindeutet, erwägen Sie, die Analyse mit alternativen Einstellungen noch einmal auszuführen, z. B. mit größeren oder kleineren Trainingsraten oder einer größeren Fraktion für die Teilstichprobe.