Hinweis
Dieser Befehl ist mit Predictive Analytics-Modul verfügbar. Klicken Sie hier, um weitere Informationen zum Aktivieren des Moduls zu erhalten.
Ein Forscherteam sammelt Daten über Faktoren, die ein Qualitätsmerkmal von gebackenen Brezeln beeinflussen. Zu den Variablen gehören Prozesseinstellungen wie Mischwerkzeug und Korneigenschaften wie Mehlprotein.
Im Rahmen der ersten Erkundung der Daten entscheiden sich die Forscher für Ermitteln von wichtigen Prädiktoren den Vergleich von Modellen, indem sie nacheinander unwichtige Prädiktoren entfernen, um wichtige Prädiktoren zu identifizieren. Die Forscher hoffen, wichtige Prädiktoren zu identifizieren, die große Effekte auf das Qualitätsmerkmal haben, und mehr Einblicke in die Beziehungen zwischen dem Qualitätsmerkmal und den wichtigsten Prädiktoren zu gewinnen.
- Öffnen Sie die Beispieldaten Brezel_Akzeptanz.MWX.
- Wählen Sie aus.
- Wählen Sie in der Dropdown-Liste die Option Binäre Antwort aus.
- Geben Sie im Feld Antwort den Wert 'akzeptable Brezel' ein.
- Wählen Sie unter Antwortereignis 1 aus, um anzugeben, dass die Brezel akzeptabel ist.
- Geben Sie im Feld Stetige Prädiktoren Mehlprotein-Massendichte ein.
- Geben Sie im Feld Kategoriale Prädiktoren Mischwerkzeug-Ofenmethode ein.
- Klicken Sie auf Prädiktorelimination.
- Geben Sie in Maximale Anzahl von Eliminierungsschritten den Wert 29 ein.
- Klicken Sie in den einzelnen Dialogfeldern auf OK.
Interpretieren der Ergebnisse
Für diese Analyse vergleicht Minitab Statistical Software 28 Modelle. Die Anzahl der Schritte ist kleiner als die maximale Anzahl von Schritten, da der Schaumstabilität-Prädiktor im ersten Modell eine Wichtigkeitspunktzahl von 0 hat, sodass der Algorithmus im ersten Schritt 2 Variablen eliminiert. Das Sternchen in der Spalte Modell der Tabelle Modellauswertung zeigt, dass das Modell mit dem kleinsten Wert der durchschnittlichen –Log-Likelihood-Statistik das Modell 23 ist. Die Ergebnisse, die der Modellauswertungstabelle folgen, beziehen sich auf Modell 23.
Obwohl Modell 23 den kleinsten Wert der durchschnittlichen –Log-Likelihood-Statistik hat, weisen andere Modelle ähnliche Werte auf. Das Team kann auf Alternatives Modell auswählen klicken, um Ergebnisse für andere Modelle aus der Tabelle Modellauswertung zu erstellen.
In den Ergebnissen für Modell 23 zeigt das Diagramme Durchschnittliche –Log-Likelihood vs. Anzahl der Bäume, dass die optimale Anzahl von Bäumen nahezu der Anzahl der Bäume in der Analyse entspricht. Das Team kann auf Optimieren von Hyperparametern klicken, um die Anzahl der Bäume zu erhöhen und zu sehen, ob Änderungen an anderen Hyperparametern die Leistung des Modells verbessern.
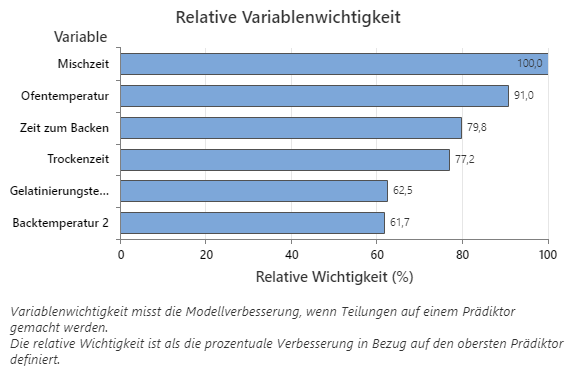
Das Diagramm „Relative Variablenwichtigkeit“ zeigt die Prädiktoren in der Reihenfolge ihrer Auswirkungen auf die Modellverbesserung, wenn Teilungen anhand eines Prädiktors über die Abfolge der Bäume hinweg vorgenommen werden. Die wichtigste Prädiktorvariable ist Mischzeit. Wenn die Wichtigkeit der obersten Prädiktorvariablen, Mischzeit, 100 % beträgt, hat die nächstwichtige Variable, Ofentemperatur, einen Beitrag von 91,0 %. Das bedeutet, dass Ofentemperatur 91,0 % so wichtig ist wie Mischzeit.
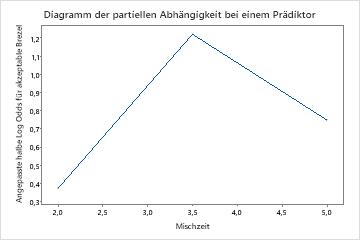
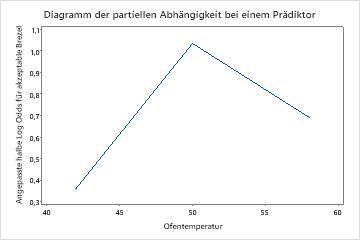
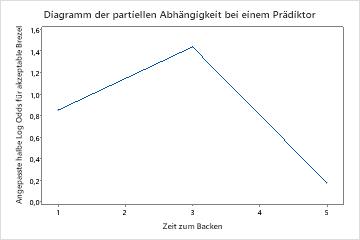
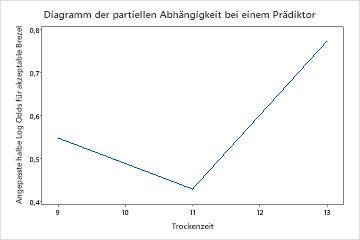
Verwenden Sie die partiellen Abhängigkeitsdiagramme, um einen Einblick in die Auswirkungen der wichtigen Variablen oder Variablenpaare auf die angepassten Antwortwerte zu erhalten. Die angepassten Antwortwerte liegen auf der 1/2 Log-Skala. Die Diagramme der partiellen Abhängigkeit zeigen, ob die Beziehung zwischen der Antwortvariablen und einer Variablen linear, monoton oder komplexer ist.
Die Diagramme der partiellen Abhängigkeit bei einem Prädiktor zeigen, dass mittlere Werte für Mischzeit, Ofentemperatur und Zeit zum Backen die Wahrscheinlichkeit einer akzeptablen Brezel erhöhen. Ein mittlerer Wert von Trockenzeit verringert die Wahrscheinlichkeit einer akzeptablen Brezel. Die Forscher können auswählen , ob sie Diagramme für andere Variablen erstellen möchten.
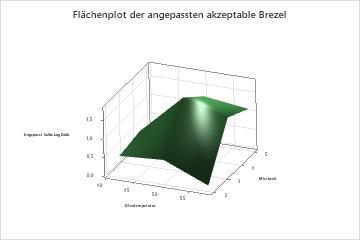
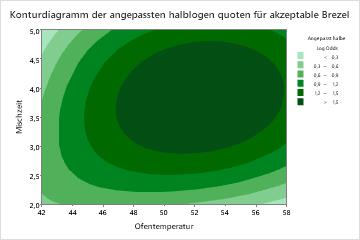
Das Diagramm der partiellen Abhängigkeit bei zwei Prädiktoren von Mischzeit und Ofentemperatur zeigt eine komplexere Beziehung zwischen den beiden Variablen und der Antwortvariablen. Während mittlere Werte von Mischzeit und Ofentemperatur die Wahrscheinlichkeit einer akzeptablen Brezel erhöhen, zeigt das Diagramm, dass die besten Quoten auftreten, wenn beide Variablen bei mittleren Werten liegen. Die Forscher können sich dafür entscheiden , Diagramme für andere Variablenpaare zu erstellen.
Methode
| Kriterium für Auswahl der optimalen Anzahl von Bäumen | Maximale Log-Likelihood |
|---|---|
| Modellvalidierung | 70/30% Trainings-/Testdatensätze |
| Trainingsrate | 0,05 |
| Auswahlmethode für Teilstichprobe | Vollständig zufällig |
| Teilstichprobenfraktion | 0,5 |
| Maximale Anzahl von Endknoten pro Baum | 6 |
| Minimale Endknotengröße | 3 |
| Anzahl der für die Knotenteilung ausgewählten Prädiktoren | Gesamtanzahl der Prädiktoren = 29 |
| Verwendete Zeilen | 5000 |
Informationen zur binären Antwort
| Trainings | Test | ||||
|---|---|---|---|---|---|
| Variable | Klasse | Anzahl | % | Anzahl | % |
| akzeptable Brezel | 1 (Ereignis) | 2160 | 61,82 | 943 | 62,62 |
| 0 | 1334 | 38,18 | 563 | 37,38 | |
| Alle | 3494 | 100,00 | 1506 | 100,00 | |
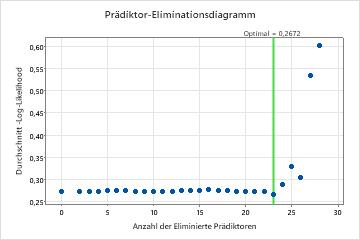
Modellauswahl durch Eliminierung unwichtiger Prädiktoren
| Modell | Optimale Anzahl von Bäumen | Durchschnitt -Log-Likelihood | Anzahl der Prädiktoren | Eliminierte Prädiktoren |
|---|---|---|---|---|
| 1 | 268 | 0,273936 | 29 | Keine |
| 2 | 268 | 0,274186 | 27 | Schaumstabilität; Massendichte |
| 3 | 234 | 0,273843 | 26 | GeringsteGelationskonzentrat |
| 4 | 233 | 0,274350 | 25 | Ofenmodus 2 |
| 5 | 232 | 0,274943 | 24 | Ofenmethode |
| 6 | 273 | 0,275553 | 23 | Ofenmodus 1 |
| 7 | 244 | 0,274811 | 22 | Mischgeschwindigkeit |
| 8 | 268 | 0,274258 | 21 | Ofenmodus 3 |
| 9 | 272 | 0,274185 | 20 | Ruhefläche |
| 10 | 232 | 0,274077 | 19 | Backtemperatur 3 |
| 11 | 287 | 0,273598 | 18 | Mischwerkzeug |
| 12 | 227 | 0,274358 | 17 | Backtemperatur 1 |
| 13 | 276 | 0,275374 | 16 | Ruhezeit |
| 14 | 272 | 0,276082 | 15 | Wasser |
| 15 | 268 | 0,275595 | 14 | kaustische Konzentration |
| 16 | 268 | 0,277810 | 13 | Schwellungskapazität |
| 17 | 253 | 0,276436 | 12 | Emulsionsstabilität |
| 18 | 231 | 0,276159 | 11 | Emulsionsaktivität |
| 19 | 268 | 0,273537 | 10 | Wasseraufnahmekapazität |
| 20 | 260 | 0,273455 | 9 | Ölaufnahmekapazität |
| 21 | 299 | 0,272848 | 8 | Mehlprotein |
| 22 | 278 | 0,272629 | 7 | Schaumkapazität |
| 23* | 299 | 0,267184 | 6 | Mehlgröße |
| 24 | 297 | 0,288621 | 5 | Backtemperatur 2 |
| 25 | 234 | 0,330342 | 4 | Trockenzeit |
| 26 | 290 | 0,305993 | 3 | Gelatinierungstemperatur |
| 27 | 245 | 0,534345 | 2 | Zeit zum Backen |
| 28 | 146 | 0,599837 | 1 | Ofentemperatur |
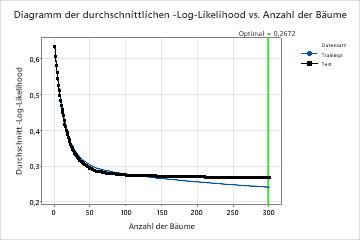
Zusammenfassung des Modells
| Prädiktoren gesamt | 6 |
|---|---|
| Wichtige Prädiktoren | 6 |
| Anzahl der aufgebauten Bäume | 300 |
| Optimale Anzahl von Bäumen | 299 |
| Statistiken | Trainings | Test |
|---|---|---|
| Durchschnittliche -Log-Likelihood | 0,2418 | 0,2672 |
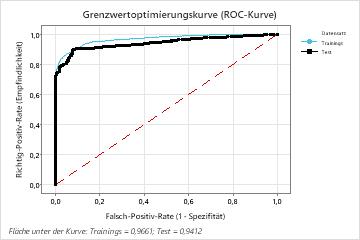
| Fläche unter der ROC-Kurve | 0,9661 | 0,9412 |
| 95%-KI | (0,9608; 0,9713) | (0,9295; 0,9529) |
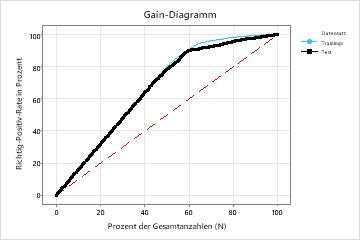
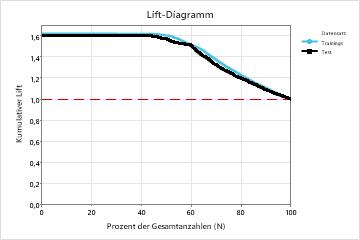
| Lift | 1,6176 | 1,5970 |
| Fehlklassifizierungsrate | 0,0970 | 0,0963 |
Konfusionsmatrix
| Prognostizierte Klasse (Trainings) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Tatsächliche Klasse | Prognostizierte Klasse (Test) | |||||||
| Anzahl | 1 | 0 | % Richtig | Anzahl | 1 | 0 | % Richtig | |
| 1 (Ereignis) | 2160 | 1942 | 218 | 89,91 | 943 | 846 | 97 | 89,71 |
| 0 | 1334 | 121 | 1213 | 90,93 | 563 | 48 | 515 | 91,47 |
| Alle | 3494 | 2063 | 1431 | 90,30 | 1506 | 894 | 612 | 90,37 |
| Statistiken | Trainings (%) | Test (%) |
|---|---|---|
| Richtig-Positiv-Rate (Empfindlichkeit oder Trennschärfe) | 89,91 | 89,71 |
| Falsch-Positiv-Rate (Fehler 1. Art) | 9,07 | 8,53 |
| Falsch-Negativ-Rate (Fehler 2. Art) | 10,09 | 10,29 |
| Richtig-Negativ-Rate (Spezifität) | 90,93 | 91,47 |
Fehlklassifikation
| Tatsächliche Klasse | Trainings | Test | ||||
|---|---|---|---|---|---|---|
| Anzahl | Fehlklassifiziert | % Fehler | Anzahl | Fehlklassifiziert | % Fehler | |
| 1 (Ereignis) | 2160 | 218 | 10,09 | 943 | 97 | 10,29 |
| 0 | 1334 | 121 | 9,07 | 563 | 48 | 8,53 |
| Alle | 3494 | 339 | 9,70 | 1506 | 145 | 9,63 |