Hinweis
Dieser Befehl ist mit Predictive Analytics-Modul verfügbar. Klicken Sie hier, um weitere Informationen zum Aktivieren des Moduls zu erhalten.
Prädiktoren gesamt
Die Gesamtzahl der für das Random Forests®-Modell verfügbaren Prädiktoren. Die Gesamtzahl ist die Summe der angegebenen stetigen und kategorialen Prädiktoren.
Wichtige Prädiktoren
Die Anzahl der wichtigen Prädiktoren im Random Forests®-Modell. Wichtige Prädiktoren haben Wichtigkeitswerte, die größer als 0,0 sind. Mit dem Diagramm „Relative Variablenwichtigkeit“ können Sie die Rangfolge der relativen Variablenwichtigkeit anzeigen. Wenn z. B. 10 von 20 Prädiktoren im Modell wichtig sind, werden die Variablen im Diagramm „Relative Variablenwichtigkeit“ in der Reihenfolge ihrer Wichtigkeit angezeigt.
R-Quadrat
R2 ist der Prozentsatz der Streuung in der Antwortvariablen, den das Modell erklärt.
Interpretation
Verwenden Sie das R2, um zu bestimmen, wie gut das Modell für Ihre Daten passend ist. Je höher das R2, desto besser ist das Modell für Ihre Daten passend. R2 liegt immer zwischen 0 % und 100 %.
Hinweis
Da Random Forests® zwar Daten von außerhalb des Segments verwenden, um R2 zu berechnen, aber nicht, um an das Modell anzupassen, ist eine Überanpassung des Modells kein Problem.
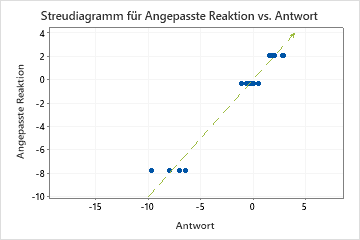
Wurzel des mittleren quadrierten Fehlers (RMSE)
Die Wurzel des mittleren quadrierten Fehlers (RMSE) ist ein Maß für die Genauigkeit des Modells. Ausreißer haben eine größere Auswirkung auf die RMSE als auf die MAD und den MAPE.
Interpretation
Hiermit können Sie die Anpassungen verschiedener Modelle vergleichen. Kleinere Werte weisen auf eine bessere Anpassung hin.
Mittlerer quadrierter Fehler (MSE)
Der mittlere quadrierte Fehler (MSE) ist ein Maß für die Genauigkeit des Modells. Ausreißer haben eine größere Auswirkung auf den MSE als auf die MAD und den MAPE.
Interpretation
Hiermit können Sie die Anpassungen verschiedener Modelle vergleichen. Kleinere Werte weisen auf eine bessere Anpassung hin.
Mittlere absolute Abweichung (MAD)
Die mittlere absolute Abweichung (MAD) drückt die Genauigkeit in der gleichen Einheit wie die Daten aus. Auf diese Weise kann der Fehleranteil leichter erfasst werden. Ausreißer haben eine geringere Auswirkung auf die MAD als auf das R2, die RMSE und den MSE.
Interpretation
Hiermit können Sie die Anpassungen verschiedener Modelle vergleichen. Kleinere Werte weisen auf eine bessere Anpassung hin.
Mittlerer absoluter prozentualer Fehler (MAPE)
Der mittlere absolute prozentuale Fehler (MAPE) gibt die Größe des Fehlers relativ zur Größe des Antwortwerts an. Daher hat der Fehler gleicher Größe einen größeren MAPE-Wert für einen kleineren Wert der Antwortvariablen als für einen größeren Wert. Da es sich bei dem MAPE um einen Prozentsatz handelt, ist dieser Wert möglicherweise verständlicher als die anderen Genauigkeitsmaße. Wenn der MAPE beispielsweise durchschnittlich 0,05 beträgt, ist das durchschnittliche Verhältnis zwischen dem angepassten Fehler und dem tatsächlichen Wert für alle Fälle 5 %. Ausreißer haben eine geringere Auswirkung auf den MAPE als auf das R2, die RMSE und den MSE.
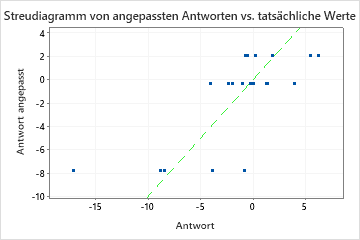
In einigen Fällen kann jedoch ein sehr großer MAPE auftreten, obwohl das Modell gut für die Daten passend zu sein scheint. Untersuchen Sie das Diagramm der angepassten vs. tatsächlichen Werte der Antwortvariablen auf Datenwerte, die nahe 0 liegen. Da beim MAPE der absolute Fehler durch die tatsächlichen Daten dividiert wird, können Werte, die nah bei 0 liegen, den MAPE stark ansteigen lassen.
Interpretation
Hiermit können Sie die Anpassungen verschiedener Modelle vergleichen. Kleinere Werte weisen auf eine bessere Anpassung hin.