Hinweis
Dieser Befehl ist mit Predictive Analytics-Modul. Klicken Sie hier, um weitere Informationen zum Aktivieren des Moduls zu erhalten.
Ein Random Forests®-Modell ist ein Ansatz zur Lösung von Klassifizierungs- und Regressionsproblemen. Der Ansatz ist sowohl genauer als auch robuster für Änderungen in Prädiktorvariablen als ein einzelner Klassifizierungs- oder Regressionsbaum. Eine grobe, allgemeine Beschreibung des Prozesses ist, dass die Minitab Statistical Software einen einzelnen Baum aus einer Bootstrap-Stichprobe erstellt. Minitab wählt nach dem Zufallsprinzip eine kleinere Anzahl von Prädiktoren aus der Gesamtzahl der Prädiktoren aus, um den besten Teiler an jedem Knoten zu bewerten. Minitab wiederholt diesen Vorgang, um viele Bäume zu erhalten. Im Fall der Klassifizierung ist die Klassifizierung aus jedem Baum eine Stimme für die prognostizierte Klassifizierung. Für eine bestimmte Zeile der Daten ist die Klasse mit den meisten Stimmen die prognostizierte Klasse für diese Zeile im Datensatz.
Um einen Klassifizierungsbaum zu erstellen, verwendet der Algorithmus das Gini-Kriterium, um die Verunreinigung von Knoten zu messen. Für die Desktopanwendung wächst jede Struktur, bis ein Knoten nicht mehr geteilt werden kann oder ein Knoten die Mindestanzahl von Fällen erreicht, um einen internen Knoten aufzuteilen. Die minimale Anzahl von Fällen ist eine Option für die Analyse. Für die Web-App fügt die Analyse die Einschränkung hinzu, dass jeder Baum ein Limit von 4.000 Endknoten hat. Weitere Einzelheiten zum Aufbau eines Klassifizierungsbaums finden Sie unter Knotenteilungsmethoden in CART® Klassifikation. Einzelheiten, die spezifisch für Random Forests® sind, folgen.
Bootstrap-Stichproben
Zum Erstellen der einzelnen Bäume wählt der Algorithmus eine zufällige Stichprobe mit Zurücklegen (Bootstrap-Beispiel) aus dem vollständigen Datensatz aus. Normalerweise ist jedes Bootstrap-Beispiel anders und kann eine andere Anzahl eindeutiger Zeilen aus dem ursprüngliche Datensatz enthalten. Wenn Sie nur die Validierung von außerhalb des Segments verwenden, ist die Standardgröße der Bootstrap-Stichprobe die Größe des ursprünglichen Datensatzes. Wenn Sie das Beispiel in einen Trainingsdatensatz und einen Testdatensatz unterteilen, entspricht die Standardgröße der Bootstrap-Stichprobe der Größe des Trainingsdatensatzes. In beiden Fällen haben Sie die Möglichkeit anzugeben, dass die Bootstrap-Stichprobe kleiner als die Standardgröße ist. Im Durchschnitt enthält eine Bootstrap-Stichprobe etwa 2/3 der Datenzeilen. Die eindeutigen Datenzeilen, die sich nicht in der Bootstrap-Stichprobe befinden, sind die Daten von außerhalb des Segments für die Validierung.
Zufällige Auswahl von Prädiktoren
An jedem Knoten in der Struktur wählt der Algorithmus nach dem Zufallsprinzip eine Teilmenge der Gesamtzahl der Prädiktoren aus, 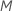 , um sie als Teiler zu bewerten. Standardmäßig wählt der Algorithmus
, um sie als Teiler zu bewerten. Standardmäßig wählt der Algorithmus  Prädiktoren zur Bewertung an jedem Knoten. Sie haben die Möglichkeit, eine andere Anzahl von Prädiktoren für die Bewertung auszuwählen, von 1 bis
Prädiktoren zur Bewertung an jedem Knoten. Sie haben die Möglichkeit, eine andere Anzahl von Prädiktoren für die Bewertung auszuwählen, von 1 bis 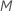 . Wenn Sie
. Wenn Sie 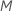 Prädiktoren wählen, dann wertet der Algorithmus jeden Prädiktor an jedem Knoten aus, was zu einer Analyse mit dem Namen „Bootstrap-Wald“ führt.
Prädiktoren wählen, dann wertet der Algorithmus jeden Prädiktor an jedem Knoten aus, was zu einer Analyse mit dem Namen „Bootstrap-Wald“ führt.
In einer Analyse, die eine Teilmenge von Prädiktoren an jedem Knoten verwendet, sind die ausgewerteten Prädiktoren in der Regel an jedem Knoten unterschiedlich. Durch die Auswertung verschiedener Prädiktoren sind die Bäume im Wald weniger miteinander korreliert. Die weniger korrelierten Bäume erzeugen einen langsamen Lerneffekt, sodass sich die Prognosen verbessern, wenn Sie mehr Bäume erstellen.
Validierung mit Daten von außerhalb des Segments
Die eindeutigen Datenzeilen, die nicht Teil des Baumerstellungsprozesses für einen bestimmten Baum sind, sind die Daten von außerhalb des Segments. Berechnungen für die Messung der Modellleistung, z. B. die durchschnittliche –Log-Likelihood, greifen auf die Daten von außerhalb des Segments zurück. Weitere Informationen finden Sie unter Methoden und Formeln für die Zusammenfassung des Modells in Random Forests®-Klassifikation.
Für einen bestimmten Baum im Wald ist eine Klassenabstimmung für eine Zeile in den Daten von außerhalb des Segments die prognostizierte Klasse für die Zeile aus dem einzelnen Baum. Die prognostizierte Klasse für eine Zeile von Daten von außerhalb des Segment ist die Klasse mit der höchsten Stimmenanzahl unter allen Bäumen im Wald.
Die prognostizierte Klassenwahrscheinlichkeit für eine Zeile in den Daten von außerhalb des Segments ist das Verhältnis zwischen der Anzahl der Stimmen für die Klasse und den Gesamtstimmen für die Zeile. Die Modellvalidierung verwendet die prognostizierten Klassen, die prognostizierten Klassenwahrscheinlichkeiten und die tatsächlichen Antwortwerte für alle Zeilen, die mindestens einmal in den Daten von außerhalb des Segments erscheinen.
Bestimmung der prognostizierten Klasse für eine Zeile im Trainingsdatensatz
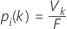
wobei Vk die Anzahl der Bäume ist, die dafür stimmen, dass Zeile i in Klasse k ist, und F die Anzahl der Bäume im Wald angibt.