Hinweis
Dieser Befehl ist mit Predictive Analytics-Modul verfügbar. Klicken Sie hier, um weitere Informationen zum Aktivieren des Moduls zu erhalten.
In diesem Thema
Außerhalb des Segments
Für einen bestimmten Baum im Wald ist eine Klassenabstimmung für eine Zeile in den Daten von außerhalb des Segments die prognostizierte Klasse für die Zeile aus dem einzelnen Baum. Die prognostizierte Klasse für eine Zeile von Daten von außerhalb des Segment ist die Klasse mit der höchsten Stimmenanzahl unter allen Bäumen im Wald. Die prognostizierte Klassenwahrscheinlichkeit für eine Zeile in den Daten von außerhalb des Segments ist das Verhältnis zwischen der Anzahl der Stimmen für die Klasse und den Gesamtstimmen für die Zeile.
Beim Diagramm für die Daten von außerhalb des Segments stellt jeder Punkt im Diagramm eine eindeutige prognostizierte Klassenwahrscheinlichkeit dar. Die höchste Ereigniswahrscheinlichkeit ist der erste Punkt im Diagramm, der links außen angezeigt wird. Die anderen Wahrscheinlichkeiten sind absteigend geordnet.
Die Punkte auf dem kumulativen Lift-Diagramm ergeben sich aus der Berechnung der Punkte auf dem ROC-Kurvendiagramm. Die y-Koordinate des kumulativen Lift-Diagramms ist (Richtig-Positiv-Rate in Prozent / kumulierte % der Bevölkerung an der x-Koordinate). Die Berechnung der Richtig-Positiv-Rate erfolgt genauso wie beim ROC-Kurvendiagramm.
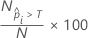
Dabei gilt: 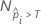 ist die Anzahl der Zeilen, in denen die angepasste Wahrscheinlichkeit größer als der Schwellenwert, und N ist die Gesamtzahl der Zeilen. Weitere Einzelheiten zu den Schwellenwerten finden Sie unter Methoden und Formeln für die Grenzwertoptimierungskurve (ROC-Kurve) für Random Forests®-Klassifikation.
ist die Anzahl der Zeilen, in denen die angepasste Wahrscheinlichkeit größer als der Schwellenwert, und N ist die Gesamtzahl der Zeilen. Weitere Einzelheiten zu den Schwellenwerten finden Sie unter Methoden und Formeln für die Grenzwertoptimierungskurve (ROC-Kurve) für Random Forests®-Klassifikation.
Separater Testdatensatz
Führen Sie die gleichen Schritte wie beim Trainingsdatensatz aus, berechnen Sie jedoch die Ereigniswahrscheinlichkeit aus den Fällen für den Testdatensatz.