Um festzustellen, wie gut das Modell zu Ihren Daten passt, prüfen Sie die Statistiken in der Modellübersichtstabelle.
Prädiktoren gesamt
Die Anzahl der für das Modell verfügbaren Gesamtprädiktoren. Dies ist die Summe der angegebenen stetigen und kategorialen Prädiktoren.
Wichtige Prädiktoren
Die Anzahl wichtiger Prädiktoren im Modell. Wichtige Prädiktoren sind die Variablen, die mindestens 1 Basisfunktion im Modell haben.
Interpretation
Mit dem Diagramm „Relative Variablenwichtigkeit“ können Sie die Rangfolge der relative Variablenwichtigkeit anzeigen. Angenommen, 10 von 20 Prädiktoren haben Basisfunktionen im Modell, zeigt das Diagramm "Relative Variablenwichtigkeit" die Variablen in der Reihenfolge der Wichtigkeit an.
Maximale Anzahl von Basisfunktionen
Die Anzahl der Basisfunktionen, die der Algorithmus erstellt, um nach dem optimalen Modell zu suchen.
Interpretation
Standardmäßig setzt Minitab Statistical Software die maximale Anzahl der Basisfunktionen auf 30. Ziehen Sie einen größeren Wert in Betracht, wenn 30 Basisfunktionen für die Daten zu klein erscheinen. Betrachten Sie beispielsweise einen größeren Wert, wenn Sie der Meinung sind, dass mehr als 30 Prädiktoren wichtig sind.
Optimale Anzahl von Basisfunktionen
Die Anzahl der Basisfunktionen im optimalen Modell.
Interpretation
Nachdem die Analyse das Modell mit der maximalen Anzahl von Basisfunktionen geschätzt hat, verwendet die Analyse ein Rückwärtseliminationsverfahren, um Basisfunktionen aus dem Modell zu entfernen. Die Analyse entfernt nacheinander die Basisfunktion, die am wenigsten zur Modellanpassung beiträgt. Bei jedem Schritt berechnet die Analyse den Wert des Optimalitätskriteriums für die Analyse, entweder R-Quadrat oder mittlere absolute Abweichung. Nach Abschluss des Eliminationsverfahrens ist die optimale Anzahl der Basisfunktionen die Zahl aus dem Eliminationsverfahren, die den optimalen Wert des Kriteriums erzeugt.
R-Quadrat
R2 ist der Prozentsatz der Streuung in der Antwortvariablen, den das Modell erklärt. Ausreißer haben eine größere Auswirkung auf das R2 als auf die MAD und den MAPE.
Wenn Sie eine Validierungsmethode verwenden, enthält die Tabelleeine R2-Statistik für den Trainingsdatensatz und eine R2-Statistik für die Validierungsmethode. Wenn die Validierungsmethode eine k-fache Kreuzvalidierung ist, verwendet die Validierung jede Faltung, wenn der Baumbau diese Faltung ausschließt. Die R2-Statistik aus den Validierungsergebnissen ist typischerweise ein besseres Maß dafür, wie das Modell für neue Daten funktioniert.
Interpretation
Verwenden Sie das R2, um zu bestimmen, wie gut das Modell für Ihre Daten passend ist. Je höher das R2, desto besser ist das Modell für Ihre Daten passend. R2 liegt immer zwischen 0 % und 100 %.
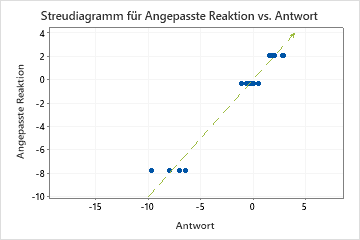
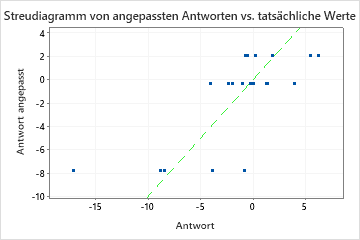
Eine Validierung von R2 , die wesentlich geringer ist als das Training R2 , zeigt, dass das Modell die Antwortwerte für neue Fälle möglicherweise nicht so gut vorhersagt und das Modell zum aktuellen Datensatz passt.
Wurzel des mittleren quadrierten Fehlers (RMSE)
Die Wurzel des mittleren quadrierten Fehlers (RMSE) ist ein Maß für die Genauigkeit des Modells. Ausreißer haben eine größere Auswirkung auf den RMSE als auf die MAD und den MAPE.
Wenn Sie eine Validierungsmethode verwenden, enthält die Tabelle eine RMSE-Statistik für den Trainingsdatensatz und eine RMSE-Statistik für die Validierungsergebnisse. Wenn die Validierungsmethode eine k-fache Kreuzvalidierung ist, verwendet die Validierung jede Faltung, wenn der Baumbau diese Faltung ausschließt. Die Validierungs-RMSE-Statistik ist typischerweise ein besseres Maß dafür, wie das Modell für neue Daten funktioniert.
Interpretation
Hiermit können Sie die Anpassungen verschiedener Modelle vergleichen. Kleinere Werte weisen auf eine bessere Anpassung hin. Ein Validierungs-RMSE, das deutlich niedriger ist als das Trainings-RMSE, zeigt, dass das Modell die Antwortwerte für neue Fälle möglicherweise nicht so gut vorhersagt und das Modell zum aktuellen Datensatz passt.
Mittlerer quadrierter Fehler (MSE)
Der mittlere quadrierte Fehler (MSE) ist ein Maß für die Genauigkeit des Modells. Ausreißer haben eine größere Auswirkung auf den MSE als auf die MAD und den MAPE.
Wenn Sie eine Validierungsmethode verwenden, enthält die Tabelle eine MSE-Statistik für den Trainingsdatensatz und eine MSE-Statistik für die Validierungsergebnisse. Wenn die Validierungsmethode eine k-fache Kreuzvalidierung ist, verwendet die Validierung jede Faltung, wenn das Modell diese Faltung ausschließt. Die Validierungs-MSE-Statistik ist typischerweise ein besseres Maß dafür, wie das Modell für neue Daten funktioniert.
Interpretation
Hiermit können Sie die Anpassungen verschiedener Modelle vergleichen. Kleinere Werte weisen auf eine bessere Anpassung hin. Ein Validierungs-MSE, das deutlich niedriger ist als das Trainings-MSE, zeigt, dass das Modell die Antwortwerte für neue Fälle möglicherweise nicht so gut vorhersagt und das Modell zum aktuellen Datensatz passt.
Mittlere absolute Abweichung (MAD)
Die mittlere absolute Abweichung (MAD) drückt die Genauigkeit in der gleichen Einheit wie die Daten aus. Auf diese Weise kann der Fehleranteil leichter erfasst werden. Ausreißer haben eine geringere Auswirkung auf den MAD als auf das R2, die RMSE und den MSE.
Wenn Sie eine Validierungsmethode verwenden, enthält die Tabelle eine MAD-Statistik für den Trainingsdatensatz und eine MAD-Statistik für die Validierungsergebnisse. Wenn die Validierungsmethode eine k-fache Kreuzvalidierung ist, verwendet die Validierung jede Faltung, wenn das Modell diese Faltung ausschließt. Die Validierungs-MAD-Statistik ist typischerweise ein besseres Maß dafür, wie das Modell für neue Daten funktioniert.
Interpretation
Hiermit können Sie die Anpassungen verschiedener Modelle vergleichen. Kleinere Werte weisen auf eine bessere Anpassung hin. Ein Validierungs-MAD, das deutlich niedriger ist als das Trainings-MAD, zeigt, dass das Modell die Antwortwerte für neue Fälle möglicherweise nicht so gut vorhersagt und das Modell zum aktuellen Datensatz passt.