Hinweis
Dieser Befehl ist mit Predictive Analytics-Modul verfügbar. Klicken Sie hier, um weitere Informationen zum Aktivieren des Moduls zu erhalten.
Suche nach dem besten Modelltyp
Forscher für ein Gesundheitssystem sammeln Daten aus ihren regionalen medizinischen Kliniken. Das Forschungsteam interessiert sich insbesondere für Daten aus ärztlichen Erstuntersuchungen kranker Patienten. Am Ende der Erstuntersuchungen weisen die Ärzte jedem Patienten eine Punktzahl für die Schwere seiner Erkrankung zu. Die Forscher wollen einen kurzen Fragebogen entwickeln, um die kranksten Patienten vor der Untersuchung durch einen Arzt zu priorisieren. Durch Rücksprache mit Fachexperten und eine erste Untersuchung der Daten wählt das Team 8 Variablen aus, um den Schweregrad vorherzusagen. Die Forscher wollen den besten Modelltyp bestimmen, um den Schweregrad vorherzusagen, bevor sie das Modell weiter verfeinern.
Die Forscher verwenden Bestes Modell ermitteln (stetige Antwort) sie, um die Vorhersageleistung von 5 Arten von Modellen zu vergleichen: multiple Regression, TreeNet®, Random Forests® CART® und MARS®. Das Team plant, den Modelltyp mit der besten Vorhersageleistung weiter zu untersuchen.
- Öffnen Sie die Beispieldaten Krankheit.MWX.
- Wählen Sie aus.
- Geben Sie im Feld Antwort die Spalte 'Schweregrad der Erkrankung' ein.
- Geben Sie im Feld Stetige Prädiktoren die Spalte 'Anzahl der Symptome jetzt' ein.
- Geben Sie in Kategoriale Prädiktoren'Hohe Schleimproduktion'-''Beschränkungen für Aktivitätenein.
- Klicken Sie auf OK.
Interpretieren der Ergebnisse
In der Tabelle Modellauswahl wird die Leistung der Modelltypen verglichen. Das multiple Regressionsmodell hat den Maximalwert R2. Die folgenden Ergebnisse beziehen sich auf das beste multiple Regressionsmodell.
Um zu bestimmen, ob die Assoziation zwischen der Antwortvariablen und jedem Term im Modell statistisch signifikant ist, vergleichen Sie den p-Wert für den Term mit dem Signifikanzniveau, um die Nullhypothese auszuwerten. Die Nullhypothese besagt, dass keine Assoziation zwischen dem Term und der Antwortvariablen besteht. In der Regel ist ein Signifikanzniveau (als α oder Alpha bezeichnet) von 0,05 gut geeignet. Ein Signifikanzniveau von 0,05 bedeutet ein Risiko, dass auf eine vorhandene Assoziation geschlossen wird, während tatsächlich keine vorhanden ist, von 5 %. In diesen Ergebnissen haben zwei der Interaktionsterme p-Werte größer als 0,05: Schwere Kurzatmigkeit*Starke Kopfschmerzen und Schwere Schlafstörungen*Starke Kopfschmerzen. Wenn die Forscher andere multiple Regressionsmodelle untersuchen, werden sie Modellleistungsmetriken und Restdiagramme verwenden, um die Auswirkungen der Einbeziehung dieser Begriffe in das Modell zu untersuchen.
Die Modellübersichtstabelle zeigt, dass das Training R2 und der Test R2 beide etwa 91% betragen. Der mittlere quadratische Fehler (RMSE) des Teststamms, der angibt, wie weit die Datenwerte von den angepassten Werten abweichen, beträgt ungefähr 4. Da der RMSE auf der Skala des Krankheitswerts klein ist, sind die Forscher optimistisch, dass eine kleine Anzahl von Fragen genug Informationen ist, um Patienten zu priorisieren.
Die Tabelle der Anpassungen und Diagnosen für ungewöhnliche Informationen zeigt Datenpunkte, die der vorgeschlagenen Regressionsgleichung nicht gut entsprechen. Dies sind die Fits und Diagnosen aus dem vollständigen Datensatz.
Der Buchstabe R kennzeichnet einen Punkt mit einem großen Rest. Untersuchen Sie die ungewöhnlichen Datenpunkte, um die Prädiktorwerte zu ermitteln, bei denen das Modell möglicherweise nicht gut passend ist. Der Buchstabe X kennzeichnet einen Punkt mit hohem Hebel. Punkte mit hoher Hebelwirkung haben ungewöhnliche Prädiktorkombinationen im Vergleich zum Rest des Datensatzes.
Große Residuen und hohe Leverage Points sind potenziell einflussreiche Punkte. Das Einbinden oder Ausschließen eines einflussreichen Punkts könnte beispielsweise ändern, ob ein Koeffizient statistisch signifikant ist. Wenn Sie eine einflussreiche Beobachtung feststellen, ermitteln Sie, ob es sich bei der Beobachtung um einen Dateneingabe- oder Messfehler handelt. Wenn es sich bei der Beobachtung nicht um einen Fehler handelt, bestimmen Sie, wie stark die Beobachtung die Ergebnisse beeinflusst. Wenn die Forscher das Modell weiter erforschen, werden sie das Modell mit und ohne die Beobachtungen anpassen. Anschließend vergleichen sie die Koeffizienten, p-Werte, R2und andere Modellinformationen. Wenn sich das Modell nach Entfernen der einflussreichen Beobachtung signifikant ändert, untersuchen Sie das Modell eingehender, um festzustellen, ob Sie das Modell falsch angegeben haben. Möglicherweise müssen Sie weitere Daten erfassen, um das Problem zu beheben.
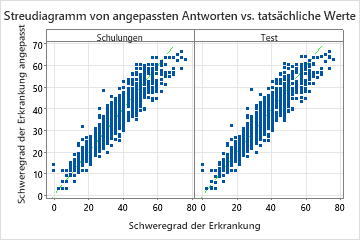
Das Streudiagramm der angepassten Krankheitswerte im Vergleich zu den tatsächlichen Krankheitswerten zeigt die Beziehung zwischen den angepassten und den tatsächlichen Werten sowohl für die Trainings- als auch für die Testdaten. Die Punkte liegen ungefähr nahe der Referenzlinie von y=x, was darauf hinweist, dass das Modell gut zu den Daten passt.
Methode
| Ein Regressionsmodell mit linearen Termen und Termen 2. Ordnung anpassen. |
|---|
| 6 TreeNet®-Regressionsmodell(e) mit der Verlustfunktion „Quadriert“ anpassen. |
| 3 Random Forests®-Regressionsmodell(e) mit Bootstrap-Stichprobenumfang gleich dem Trainingsdatenumfang von 1546 anpassen. |
| Ein optimales CART®-Regressionsmodell anpassen. |
| Ein optimales MARS®-Regressionsmodell anpassen. |
| Das Modell mit dem maximalen R-Quadrat aus der Kreuzvalidierung mit 5 Faltungen auswählen. |
| Gesamtzahl der Zeilen: 1546 |
| Für Regressionsmodell verwendete Zeilen: 1546 |
| Für baumbasierte Modelle verwendete Zeilen: 1546 |
Informationen zur Antwortvariablen
| Mittelwert | StdAbw | Minimum | Q1 | Median | Q3 | Maximum |
|---|---|---|---|---|---|---|
| 31,0110 | 14,0820 | 0 | 19,05 | 30,95 | 40,48 | 76,19 |
| Bestes Modell innerhalb des Typs | R-Quadrat (%) | Mittlere absolute Abweichung |
|---|---|---|
| Multiple Regression* | 91,23 | 3,1011 |
| MARS® | 91,05 | 3,1604 |
| TreeNet® | 90,90 | 3,1613 |
| Random Forests® | 89,93 | 3,3248 |
| CART® | 86,11 | 3,9369 |
Vorwärtsauswahl der Terme mit Validierung für bestes Modell der multiplen Regression
Starke Kopfschmerzen; Schwere Schlafstörungen; Generell sehr schlecht fühlen; Beschränkungen
für Aktivitäten; Anzahl der Symptome jetzt*Schwere Kurzatmigkeit; Anzahl der Symptome
jetzt*Starke Brustschmerzen; Schwere Kurzatmigkeit*Schwere Schlafstörungen; Generell sehr
schlecht fühlen*Beschränkungen für Aktivitäten
Regressionsgleichung
| Schweregrad der Erkrankung | = | 1,241 + 2,5386 Anzahl der Symptome jetzt + 0,0 Hohe Schleimproduktion_0 + 3,900 Hohe Schleimproduktion_1 + 0,0 Schwere Kurzatmigkeit_0 + 0,94 Schwere Kurzatmigkeit_1 + 0,0 Starke Kopfschmerzen_0 + 4,094 Starke Kopfschmerzen_1 + 0,0 Schwere Schlafstörungen_0 + 3,884 Schwere Schlafstörungen_1 + 0,0 Generell sehr schlecht fühlen_0 + 3,473 Generell sehr schlecht fühlen_1 + 0,0 Beschränkungen für Aktivitäten_0 + 3,140 Beschränkungen für Aktivitäten_1 + 0,0 Anzahl der Symptome jetzt*Schwere Kurzatmigkeit_0 + 0,373 Anzahl der Symptome jetzt*Schwere Kurzatmigkeit_1 + 0,0 Anzahl der Symptome jetzt*Starke Brustschmerzen_0 + 0,4765 Anzahl der Symptome jetzt*Starke Brustschmerzen_1 + 0,0 Schwere Kurzatmigkeit*Schwere Schlafstörungen_0 0 + 0,0 Schwere Kurzatmigkeit*Schwere Schlafstörungen_0 1 + 0,0 Schwere Kurzatmigkeit*Schwere Schlafstörungen_1 0 + 1,337 Schwere Kurzatmigkeit*Schwere Schlafstörungen_1 1 + 0,0 Generell sehr schlecht fühlen*Beschränkungen für Aktivität en_0 0 + 0,0 Generell sehr schlecht fühlen*Beschränkungen für Aktivität en_0 1 + 0,0 Generell sehr schlecht fühlen*Beschränkungen für Aktivität en_1 0 + 1,372 Generell sehr schlecht fühlen*Beschränkungen für Aktivit äten_1 1 |
|---|
Koeffizienten
| Term | Koef | SE Koef | t-Wert | p-Wert |
|---|---|---|---|---|
| Konstante | 1,241 | 0,385 | 3,22 | 0,001 |
| Anzahl der Symptome jetzt | 2,5386 | 0,0593 | 42,81 | 0,000 |
| Hohe Schleimproduktion | ||||
| 1 | 3,900 | 0,225 | 17,35 | 0,000 |
| Schwere Kurzatmigkeit | ||||
| 1 | 0,94 | 1,18 | 0,80 | 0,424 |
| Starke Kopfschmerzen | ||||
| 1 | 4,094 | 0,253 | 16,18 | 0,000 |
| Schwere Schlafstörungen | ||||
| 1 | 3,884 | 0,284 | 13,69 | 0,000 |
| Generell sehr schlecht fühlen | ||||
| 1 | 3,473 | 0,343 | 10,14 | 0,000 |
| Beschränkungen für Aktivitäten | ||||
| 1 | 3,140 | 0,424 | 7,40 | 0,000 |
| Anzahl der Symptome jetzt*Schwere Kurzatmigkeit | ||||
| 1 | 0,373 | 0,133 | 2,81 | 0,005 |
| Anzahl der Symptome jetzt*Starke Brustschmerzen | ||||
| 1 | 0,4765 | 0,0312 | 15,26 | 0,000 |
| Schwere Kurzatmigkeit*Schwere Schlafstörungen | ||||
| 1 1 | 1,337 | 0,528 | 2,53 | 0,011 |
| Generell sehr schlecht fühlen*Beschränkungen für Aktivitäten | ||||
| 1 1 | 1,372 | 0,527 | 2,61 | 0,009 |
| Term | VIF |
|---|---|
| Konstante | |
| Anzahl der Symptome jetzt | 1,95 |
| Hohe Schleimproduktion | |
| 1 | 1,10 |
| Schwere Kurzatmigkeit | |
| 1 | 23,23 |
| Starke Kopfschmerzen | |
| 1 | 1,25 |
| Schwere Schlafstörungen | |
| 1 | 1,73 |
| Generell sehr schlecht fühlen | |
| 1 | 2,62 |
| Beschränkungen für Aktivitäten | |
| 1 | 3,98 |
| Anzahl der Symptome jetzt*Schwere Kurzatmigkeit | |
| 1 | 26,80 |
| Anzahl der Symptome jetzt*Starke Brustschmerzen | |
| 1 | 1,25 |
| Schwere Kurzatmigkeit*Schwere Schlafstörungen | |
| 1 1 | 3,26 |
| Generell sehr schlecht fühlen*Beschränkungen für Aktivitäten | |
| 1 1 | 5,73 |
Zusammenfassung des Modells
| Statistiken | Trainings | Test |
|---|---|---|
| R-Quadrat | 91,35% | 91,23% |
| Wurzel des mittleren quadrierten Fehlers (RMSE) | 4,1562 | 4,1679 |
| Mittlerer quadrierter Fehler (MSE) | 17,2741 | 17,3714 |
| Mittlere abs. Abweichung (MAD) | 3,0798 | 3,1011 |
| R-Quadrat (kor) | 91,29% | |
| R-Quadrat (prog) | 91,19% |
Varianzanalyse
| Quelle | DF | Kor SS | Kor MS |
|---|---|---|---|
| Regression | 11 | 279881 | 25443,7 |
| Anzahl der Symptome jetzt | 1 | 31655 | 31654,8 |
| Hohe Schleimproduktion | 1 | 5202 | 5201,8 |
| Schwere Kurzatmigkeit | 1 | 11 | 11,1 |
| Starke Kopfschmerzen | 1 | 4520 | 4520,0 |
| Schwere Schlafstörungen | 1 | 3239 | 3238,8 |
| Generell sehr schlecht fühlen | 1 | 1776 | 1775,6 |
| Beschränkungen für Aktivitäten | 1 | 945 | 945,4 |
| Anzahl der Symptome jetzt*Schwere Kurzatmigkeit | 1 | 136 | 136,4 |
| Anzahl der Symptome jetzt*Starke Brustschmerzen | 1 | 4023 | 4023,4 |
| Schwere Kurzatmigkeit*Schwere Schlafstörungen | 1 | 111 | 110,7 |
| Generell sehr schlecht fühlen*Beschränkungen für Aktivitäten | 1 | 117 | 117,3 |
| Fehler | 1534 | 26498 | 17,3 |
| Fehlende Anpassung | 484 | 9247 | 19,1 |
| Reiner Fehler | 1050 | 17251 | 16,4 |
| Gesamt | 1545 | 306379 |
| Quelle | F-Wert | p-Wert |
|---|---|---|
| Regression | 1472,94 | 0,000 |
| Anzahl der Symptome jetzt | 1832,51 | 0,000 |
| Hohe Schleimproduktion | 301,14 | 0,000 |
| Schwere Kurzatmigkeit | 0,64 | 0,424 |
| Starke Kopfschmerzen | 261,66 | 0,000 |
| Schwere Schlafstörungen | 187,50 | 0,000 |
| Generell sehr schlecht fühlen | 102,79 | 0,000 |
| Beschränkungen für Aktivitäten | 54,73 | 0,000 |
| Anzahl der Symptome jetzt*Schwere Kurzatmigkeit | 7,90 | 0,005 |
| Anzahl der Symptome jetzt*Starke Brustschmerzen | 232,92 | 0,000 |
| Schwere Kurzatmigkeit*Schwere Schlafstörungen | 6,41 | 0,011 |
| Generell sehr schlecht fühlen*Beschränkungen für Aktivitäten | 6,79 | 0,009 |
| Fehler | ||
| Fehlende Anpassung | 1,16 | 0,025 |
| Reiner Fehler | ||
| Gesamt |
Anpassungen und Bewertung für ungewöhnliche Beobachtungen
| Beob | Schweregrad der Erkrankung | Anpassung | Resid | Std. Resid | ||
|---|---|---|---|---|---|---|
| 11 | 66,670 | 56,757 | 9,913 | 2,40 | R | |
| 13 | 52,380 | 41,177 | 11,203 | 2,71 | R | |
| 16 | 59,520 | 48,604 | 10,916 | 2,64 | R | |
| 33 | 50,000 | 60,657 | -10,657 | -2,57 | R | |
| 48 | 64,290 | 55,416 | 8,874 | 2,14 | R | |
| 52 | 61,900 | 53,369 | 8,531 | 2,06 | R | |
| 54 | 50,000 | 41,598 | 8,402 | 2,03 | R | |
| 56 | 50,000 | 58,328 | -8,328 | -2,02 | R | |
| 58 | 38,100 | 46,485 | -8,385 | -2,03 | R | |
| 106 | 59,520 | 49,028 | 10,492 | 2,53 | R | |
| 114 | 59,520 | 47,160 | 12,360 | 2,99 | R | |
| 128 | 69,050 | 58,328 | 10,722 | 2,59 | R | |
| 144 | 50,000 | 40,471 | 9,529 | 2,30 | R | |
| 173 | 47,620 | 56,757 | -9,137 | -2,21 | R | |
| 174 | 42,860 | 34,000 | 8,860 | 2,14 | R | |
| 191 | 42,860 | 52,051 | -9,191 | -2,23 | R | |
| 198 | 59,520 | 48,411 | 11,109 | 2,68 | R | |
| 202 | 73,810 | 64,046 | 9,764 | 2,36 | R | |
| 205 | 47,620 | 37,559 | 10,061 | 2,43 | R | |
| 213 | 35,710 | 34,970 | 0,740 | 0,18 | X | |
| 217 | 16,670 | 19,053 | -2,383 | -0,58 | X | |
| 239 | 47,620 | 58,328 | -10,708 | -2,59 | R | |
| 241 | 71,430 | 66,311 | 5,119 | 1,25 | X | |
| 243 | 14,290 | 24,088 | -9,798 | -2,36 | R | |
| 304 | 50,000 | 41,130 | 8,870 | 2,14 | R | |
| 307 | 14,290 | 10,920 | 3,370 | 0,83 | X | |
| 352 | 64,290 | 51,254 | 13,036 | 3,15 | R | |
| 369 | 38,100 | 49,275 | -11,175 | -2,70 | R | |
| 391 | 16,670 | 32,073 | -15,403 | -3,72 | R | |
| 392 | 0,000 | 11,395 | -11,395 | -2,75 | R | |
| 395 | 0,000 | 13,934 | -13,934 | -3,36 | R | |
| 424 | 40,480 | 52,504 | -12,024 | -2,90 | R | |
| 425 | 47,620 | 34,597 | 13,023 | 3,16 | R | |
| 474 | 47,620 | 38,538 | 9,082 | 2,21 | R | |
| 479 | 40,480 | 30,896 | 9,584 | 2,31 | R | |
| 489 | 16,670 | 25,023 | -8,353 | -2,02 | R | |
| 491 | 30,950 | 24,348 | 6,602 | 1,61 | X | |
| 493 | 57,140 | 44,339 | 12,801 | 3,09 | R | |
| 495 | 35,710 | 25,480 | 10,230 | 2,47 | R | |
| 509 | 38,100 | 26,696 | 11,404 | 2,77 | R | |
| 520 | 73,810 | 58,328 | 15,482 | 3,75 | R | |
| 537 | 38,100 | 28,358 | 9,742 | 2,35 | R | |
| 550 | 14,290 | 24,458 | -10,168 | -2,45 | R | |
| 583 | 42,860 | 53,369 | -10,509 | -2,54 | R | |
| 694 | 19,050 | 21,817 | -2,767 | -0,68 | X | |
| 720 | 59,520 | 65,602 | -6,082 | -1,49 | X | |
| 722 | 40,480 | 32,066 | 8,414 | 2,03 | R | |
| 802 | 30,950 | 42,586 | -11,636 | -2,81 | R | |
| 805 | 30,950 | 39,868 | -8,918 | -2,16 | R | |
| 814 | 40,480 | 32,073 | 8,407 | 2,03 | R | |
| 823 | 61,900 | 48,148 | 13,752 | 3,33 | R | |
| 833 | 33,330 | 44,054 | -10,724 | -2,60 | R | |
| 859 | 38,100 | 49,275 | -11,175 | -2,70 | R | |
| 868 | 47,620 | 37,789 | 9,831 | 2,38 | R | |
| 891 | 30,950 | 19,945 | 11,005 | 2,66 | R | |
| 893 | 28,570 | 48,860 | -20,290 | -4,92 | R | |
| 905 | 45,240 | 55,416 | -10,176 | -2,46 | R | |
| 924 | 54,760 | 56,019 | -1,259 | -0,31 | X | |
| 977 | 64,290 | 53,107 | 11,183 | 2,72 | R | |
| 983 | 57,140 | 47,683 | 9,457 | 2,29 | R | |
| 988 | 50,000 | 44,501 | 5,499 | 1,34 | X | |
| 993 | 73,810 | 64,046 | 9,764 | 2,36 | R | |
| 997 | 33,330 | 24,458 | 8,872 | 2,14 | R | |
| 1003 | 54,760 | 45,128 | 9,632 | 2,33 | R | |
| 1025 | 33,330 | 47,705 | -14,375 | -3,49 | R | |
| 1059 | 57,140 | 48,663 | 8,477 | 2,05 | R | |
| 1105 | 47,620 | 37,319 | 10,301 | 2,49 | R | |
| 1150 | 59,520 | 44,339 | 15,181 | 3,67 | R | |
| 1160 | 52,380 | 40,051 | 12,329 | 2,97 | R | |
| 1163 | 30,950 | 41,598 | -10,648 | -2,57 | R | |
| 1165 | 69,050 | 56,757 | 12,293 | 2,97 | R | |
| 1169 | 59,520 | 49,275 | 10,245 | 2,48 | R | |
| 1198 | 42,860 | 51,516 | -8,656 | -2,09 | R | |
| 1207 | 76,190 | 63,534 | 12,656 | 3,07 | R | |
| 1213 | 26,190 | 40,278 | -14,088 | -3,41 | R | |
| 1228 | 40,480 | 50,571 | -10,091 | -2,45 | R | |
| 1235 | 59,520 | 50,175 | 9,345 | 2,26 | R | |
| 1237 | 57,140 | 48,239 | 8,901 | 2,15 | R | |
| 1246 | 64,290 | 55,416 | 8,874 | 2,14 | R | |
| 1262 | 45,240 | 35,957 | 9,283 | 2,24 | R | |
| 1263 | 57,140 | 43,951 | 13,189 | 3,18 | R | |
| 1282 | 33,330 | 36,011 | -2,681 | -0,65 | X | |
| 1284 | 45,240 | 56,564 | -11,324 | -2,74 | R | |
| 1285 | 47,620 | 60,657 | -13,037 | -3,15 | R | |
| 1303 | 26,190 | 36,567 | -10,377 | -2,51 | R | |
| 1305 | 35,710 | 45,499 | -9,789 | -2,36 | R | |
| 1311 | 30,950 | 40,089 | -9,139 | -2,21 | R | |
| 1345 | 26,190 | 25,105 | 1,085 | 0,26 | X | |
| 1353 | 42,860 | 53,175 | -10,315 | -2,49 | R | |
| 1365 | 26,190 | 17,834 | 8,356 | 2,01 | R | |
| 1377 | 47,620 | 35,222 | 12,398 | 3,00 | R | |
| 1380 | 69,050 | 55,416 | 13,634 | 3,29 | R | |
| 1384 | 50,000 | 38,496 | 11,504 | 2,78 | R | |
| 1414 | 26,190 | 35,345 | -9,155 | -2,21 | R | |
| 1502 | 61,900 | 50,195 | 11,705 | 2,84 | R | |
| 1526 | 38,100 | 25,450 | 12,650 | 3,05 | R | |
| 1535 | 14,290 | 24,088 | -9,798 | -2,36 | R | |
| 1544 | 38,100 | 29,165 | 8,935 | 2,16 | R | |
| 1548 | 50,000 | 40,455 | 9,545 | 2,31 | R | |
| 1565 | 38,100 | 42,846 | -4,746 | -1,16 | X | |
| 1582 | 66,670 | 55,437 | 11,233 | 2,72 | R |
Auswählen eines alternativen Modells
Die Forscher beschließen, die Ergebnisse für das beste TreeNet®-Modell zu untersuchen.
- Wählen Sie Alternatives Modell auswählen in den Ergebnissen für Bestes Modell ermitteln (stetige Antwort) aus.
- Wählen Sie im Feld Modelltyp die Option TreeNet® aus.
- Wählen Sie in Vorhandenes Modell auswählendas sechste Modell aus, das den besten Wert von R2hat.
- Klicken Sie auf Anzeigen der Ergebnisse.
Interpretieren der Ergebnisse
Diese Analyse wächst 300 Bäume und die optimale Anzahl von Bäumen ist 63. Das Modell verwendet eine Lernrate von 0,1 und einen Teilstichprobenanteil von 0,7. Die maximale Anzahl von Terminalknoten beträgt 6.
Methode
| Verlustfunktion | Quadrierter Fehler |
|---|---|
| Kriterium für Auswahl der optimalen Anzahl von Bäumen | Maximales R-Quadrat |
| Modellvalidierung | Kreuzvalidierung mit 5 Faltungen |
| Trainingsrate | 0,1 |
| Teilstichbruchfraktionschefin | 0,7 |
| Maximale Anzahl von Endknoten pro Baum | 6 |
| Minimale Endknotengröße | 3 |
| Anzahl der für die Knotenteilung ausgewählten Prädiktoren | Gesamtanzahl der Prädiktoren = 8 |
| Verwendete Zeilen | 1546 |
| Nicht verwendete Zeilen | 70 |
Informationen zur Antwortvariablen
| Mittelwert | StdAbw | Minimum | Q1 | Median | Q3 | Maximum |
|---|---|---|---|---|---|---|
| 31,0110 | 14,0820 | 0 | 19,05 | 30,95 | 40,48 | 76,19 |
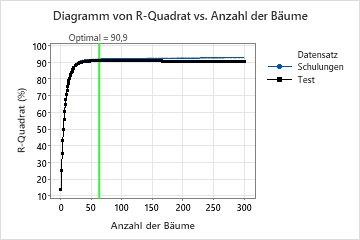
Das Diagramm von R-Quadrat vs. Anzahl der Bäume zeigt die gesamte Kurve über die Anzahl der aufgebauten Bäume. Der optimale Wert für die Testdaten liegt bei etwa 91%, wenn die Anzahl der Bäume 63 beträgt.
Zusammenfassung des Modells
| Prädiktoren gesamt | 8 |
|---|---|
| Wichtige Prädiktoren | 8 |
| Anzahl der aufgebauten Bäume | 300 |
| Optimale Anzahl von Bäumen | 63 |
| Statistiken | Schulungen | Test |
|---|---|---|
| R-Quadrat | 91,93% | 90,90% |
| Wurzel des mittleren quadrierten Fehlers (RMSE) | 3,9992 | 4,2471 |
| Mittlerer quadrierter Fehler (MSE) | 15,9932 | 18,0375 |
| Mittlere abs. Abweichung (MAD) | 2,9943 | 3,1613 |
| Mittlerer absoluter prozentualer Fehler (MAPE) | 0,1088 | 0,1130 |
Die Modellübersichtstabelle zeigt, dass der R2-Wert bei einer Anzahl von Bäumen von 63 für die Trainingsdaten ca. 92% und für die Testdaten ca. 91% beträgt.
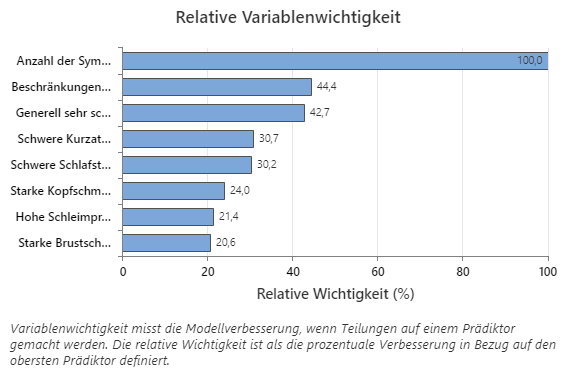
Das Diagramm „Relative Variablenwichtigkeit“ zeigt die Prädiktoren in der Reihenfolge ihrer Auswirkungen auf die Modellverbesserung, wenn Teilungen anhand eines Prädiktors über die Abfolge der Bäume hinweg vorgenommen werden. Die wichtigste Prädiktorvariable ist Anzahl der Symptome jetzt. Wenn der Beitrag der obersten Prädiktorvariablen 100% beträgt, Anzahl der Symptome jetzt, dann hat die nächste wichtige Variable, Beschränkungen für Aktivitäten, einen Beitrag von 44,4%. Beschränkungen für Aktivitäten Dies bedeutet, dass 44,4% so wichtig ist wie Anzahl der Symptome jetzt in diesem Regressionsmodell.
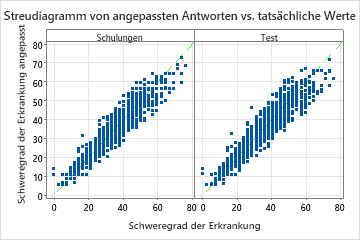
Das Streudiagramm der angepassten Krankheitswerte im Vergleich zu den tatsächlichen Krankheitswerten zeigt die Beziehung zwischen den angepassten und den tatsächlichen Werten sowohl für die Trainings- als auch für die Testdaten. Die Punkte liegen ungefähr nahe der Referenzlinie von y=x, was darauf hinweist, dass das Modell gut zu den Daten passt.
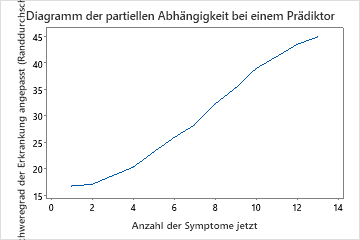
Verwenden Sie die partiellen Abhängigkeitsdiagramme, um einen Einblick in die Auswirkungen der wichtigen Variablen oder Variablenpaare auf die angepassten Antwortwerte zu erhalten. Die Diagramme der partiellen Abhängigkeit zeigen, ob die Beziehung zwischen der Antwortvariablen und einer Variablen linear, monoton oder komplexer ist.
Das erste Diagramm veranschaulicht die Beziehung zwischen den Krankheitswerten und der Anzahl der Symptome, die der Patient jetzt hat. Sie können den Mauszeiger über einzelne Datenpunkte bewegen, um die spezifischen x- und y-Werte anzuzeigen. Zum Beispiel ist der höchste Punkt auf der rechten Seite der Grafik, wenn der Patient 13 Symptome hat und der angepasste Krankheitswert ungefähr 45 beträgt.
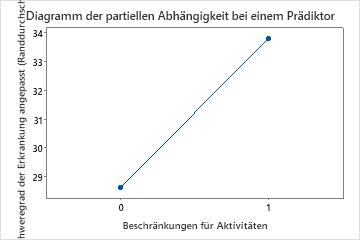
Die zweite Grafik zeigt, dass der angepasste Krankheitswert um etwa 5 Punkte ansteigt, wenn Patienten Einschränkungen ihrer normalen Aktivitäten melden.
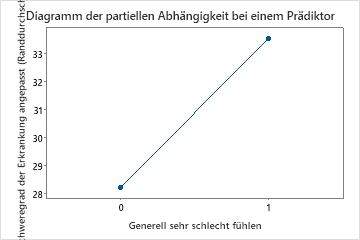
Die dritte Grafik zeigt, dass der angepasste Krankheitswert um etwa 5 Punkte ansteigt, wenn Patienten berichten, dass sie sich im Allgemeinen sehr schlecht fühlen.
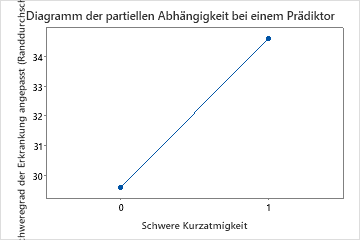
Die vierte Grafik zeigt, dass der angepasste Krankheitswert um etwa 4 Punkte ansteigt, wenn Patienten über schwere Kurzatmigkeit berichten.
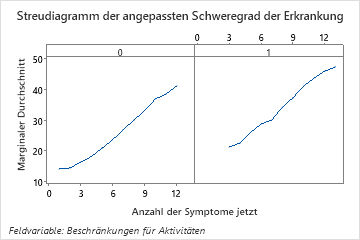
Das letzte Diagramm zeigt, wie der angepasste Krankheitswert für eine Reihe von Symptomen davon abhängt, ob der Patient auch Einschränkungen seiner normalen Aktivitäten hat. Für die gleiche Anzahl von Symptomen haben Patienten, die auch Einschränkungen ihrer normalen Aktivitäten melden, höhere angepasste Krankheitswerte.