Die Knotenstatistiken stammen aus den Daten für einzelne Knoten. Bei der Verwendung einer Validierungsmethode ist die Anpassung für einen Knoten identisch, unabhängig davon, ob sie sich im Testdatensatz oder im Trainingsdatensatz befindet. Die anderen Statistiken verwenden die Datensätze für den Knoten aus dem Trainings- oder dem Testdatensatz.
Diese Statistiken werden in der Tabelle der besten oder schlechtesten Endknoten angezeigt. Im Allgemeinen sind die Zeilen nach der Größe des Fehlers (MSE oder MAD) sortiert. Sind beide Werte kleiner als 1, stellen Werte innerhalb von 1E-12 Bindungen dar. Wenn einer der Fehlerwerte größer als 1 ist, stellen Werte innerhalb von 1E-12* (größerer Wert) Bindungen dar. Minitab sortiert Bindungen nach ihren gewichteten Anzahlen. Wenn die gewichteten Anzahlen ebenfalls Bindungen sind, sortiert Minitab Bindungen nach der Knoten-ID.
Anpassung
Die Anpassung hängt vom Kriterium für die Verbesserung eines Knotens ab. Wenn als Kriterium die kleinsten Quadrate festgelegt sind, ist die Anpassung der Mittelwert:
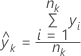
Wenn das Kriterium die geringste absolute Abweichung ist, dann ist die Anpassung der Median.
StdAbw
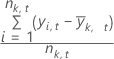
MSE
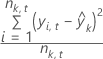
MAD
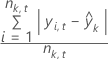
MAPE
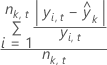
Notation
| Begriff | Beschreibung |
|---|---|
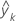 | angepasster Wert für den k-ten Knoten |
| yi | i -ten beobachteter Ansprechwert im k-ten Knoten |
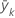 | Mittlere Antwort für die Datensätze im k-ten Knoten |
| nk | Anzahl der Datensätze im k-ten Knoten |
| nk, t | Anzahl der Datensätze im k-ten Knoten für Beobachtungen im Trainingsdatensatz oder im Testdatensatz |
| yi, t | i -ten beobachteter Antwortwert im k-ten Knoten für den Trainingsdatensatz oder die Testdaten Festgelegt |
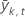 | Mittlere Antwort für die Datensätze im k-ten Knoten entweder im Trainingsdatensatz oder in den Testdaten Festgelegt |