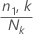Das Verfahren für die Berechnung des kumulativen Lifts hängt von der Validierungsmethode ab. Für eine multinomiale Antwortvariable zeigt Minitab mehrere Diagramme an, in denen jede Klasse nacheinander als Ereignis behandelt wird.
Trainingsdatensatz oder keine Validierung
Beim Diagramm für einen Trainingsdatensatz stellt jeder Punkt im Diagramm einen Endknoten aus dem Baum dar. Der Endknoten mit der höchsten Ereigniswahrscheinlichkeit ist der erste Punkt im Diagramm, der links außen angezeigt wird. Die anderen Endknoten werden nach abnehmender Ereigniswahrscheinlichkeit geordnet abgebildet.
Verwendern Sie das folgende Verfahren, um die x- und y-Koordinaten für die Punkte zu finden.
Berechnen Sie die Ereigniswahrscheinlichkeit jedes Endknotens:
Dabei gilt Folgendes:
n1,k ist die Anzahl der Fälle in der Ereignisklasse im
k-ten Knoten
Nk ist die Anzahl der Fälle im
k-ten Knoten
Bilden Sie eine Rangfolge der Endknoten von der höchsten bis zur niedrigsten Ereigniswahrscheinlichkeit.
Verwenden Sie jede Ereigniswahrscheinlichkeit als Schwellenwert. Für einen bestimmten Schwellenwert erhalten Fälle mit geschätzter Ereigniswahrscheinlichkeit, die größer oder gleich dem Schwellenwert sind, 1 als prognostizierte Klasse, andernfalls 0. Anschließend können Sie eine 2x2-Tabelle für alle Fälle mit beobachteten Klassen als Zeilen und prognostizierten Klassen als Spalten erstellen, um die Richtig-Positiv-Rate für jeden Endknoten zu berechnen.
Angenommen, in der folgenden Tabelle wird ein Baum mit vier Endknoten zusammengefasst:
A: Endknoten
B: Anzahl der Ereignisse
C: Anzahl der Fälle
D: Schwellenwert (B/C)
4
18
30
0,60
1
25
67
0,37
3
12
56
0,21
2
4
36
0,11
Gesamt
59
189
Im Folgenden sind die entsprechenden vier Tabellen mit ihren jeweiligen Richtig-Positiv-Raten auf 2 Dezimalstellen gerundet aufgeführt:
Suchen Sie in den sortierten Endknoten den Prozentsatz der Grundgesamtheit in den Endknoten:
Dabei gilt Folgendes:
Nk ist die Anzahl der Fälle im
k-ten Knoten
N ist die Anzahl der Fälle im Trainingsdatensatz
Berechnen Sie anhand der sortierten Liste den kumulierten Prozentsatz der Daten in jedem Endknoten. Diese kumulierten Werte sind die x-Koordinaten im Diagramm.
Wenn z. B. der Endknoten mit der höchsten prognostizierten Wahrscheinlichkeit 0,16 der Daten und der Endknoten mit der zweithöchsten Ereigniswahrscheinlichkeit 0,35 der Grundgesamtheit enthält, beträgt der kumulierte Prozentsatz der Daten für den ersten Endknoten 0,16 und der kumulierte Prozentsatz der Grundgesamtheit für den zweiten Endknoten 0,16 + 0,35 = 0,51.
Um den kumulativen Lift für die y-Koordinate zu ermitteln, dividieren Sie die Richtig-Positiv-Rate und den kumulierten Prozentsatz der Grundgesamtheit:
Die folgende Tabelle zeigt ein Beispiel der Berechnungen für einen kleinen Baum. Die Werte sind auf zwei Dezimalstellen gerundet.
A: Endknoten
B: Anzahl der Ereignisse
C: Anzahl der Fälle
D: Ereigniswahrscheinlichkeit für Sortierung (B/C)
E: Richtig-Positiv-Rate
F: Prozentsatz der Daten (C/Summe von C)
G: Kumulierter Prozentsatz der Daten, x-Koordinate
H: Kumulativer Lift (E/G), y-Koordinate
4
18
30
0,60
0,31
0,16
0,16
1,92
1
25
67
0,37
0,73
0,35
0,51
1,42
3
12
56
0,21
0,93
0,30
0,81
1,15
2
4
36
0,11
1
0,19
1,00
1
Separater Testdatensatz
Führen Sie die gleichen Schritte wie beim Trainingsdatensatz aus, berechnen Sie jedoch die Ereigniswahrscheinlichkeit aus den Fällen für den Testdatensatz.
Test mit Kreuzvalidierung mit K Faltungen
Das Verfahren zum Definieren der x- und y-Koordinaten im kumulativen Lift-Diagramm mit Kreuzvalidierung mit K Faltungen umfasst einen zusätzlichen Schritt. Durch diesen Schritt werden viele eindeutige Ereigniswahrscheinlichkeiten erzeugt. Angenommen, das Baumdiagramm enthält vier Endknoten. Es liegt eine Kreuzvalidierung mit 10 Faltungen vor. Verwenden Sie für die i-te Faltung den 9/10-Anteil der Daten, um die Ereigniswahrscheinlichkeiten für Fälle in Faltung i zu schätzen. Wird dieser Vorgang für jede Faltung wiederholt, beträgt die maximale Anzahl eindeutiger Ereigniswahrscheinlichkeiten 4 *10 = 40. Sortieren Sie anschließend alle eindeutigen Ereigniswahrscheinlichkeiten in absteigender Reihenfolge. Verwenden Sie die Ereigniswahrscheinlichkeiten als Schwellenwerte, um prognostizierte Klassen für Fälle im gesamten Datensatz zuzuweisen. Nach diesem Schritt bestimmen Sie mit den Schritten für den Trainingsdatensatz ab Schritt 3 bis zum Ende die x- und y-Koordinaten.