In diesem Thema
Hauptkomponenten
Wenn Hauptkomponenten als Extraktionsmethode verwendet werden, entsprechen die j-ten Ladungen den skalierten Koeffizienten der j-ten Hauptkomponenten. Die Faktoren stehen in Bezug zu den ersten m Komponenten. In der nicht rotierten Lösung können Sie die Faktoren so interpretieren, wie Sie die Komponenten in einer Hauptkomponentenanalyse interpretieren würden. Nach einer Rotation können Sie die Faktoren jedoch nicht mehr wie Hauptkomponenten interpretieren.
Die Hauptkomponenten-Faktorenanalyse der Stichproben-Korrelationsmatrix R (oder Kovarianzmatrix S) wird in Form ihrer Eigenwert-Eigenvektor-Paare angegeben (λi, ei), i = 1, ...,p und λ1 ≤ λ2 ≤ ... ≤ λp). Sei m < p die Anzahl der gemeinsamen Faktoren. Die Matrix der geschätzten Faktorladungen ist die (p × m)-Matrix L, deren i-te Spalte folgendermaßen lautet:  , i = 1, ..., m.
, i = 1, ..., m.
Maximum-Likelihood
Bei der Maximum-Likelihood-Methode werden die Faktorladungen auf der Grundlage der Annahme geschätzt, dass die Daten einer multivariaten Normalverteilung folgen. Wie der Name andeutet, werden bei dieser Methode Schätzwerte für die Faktorladungen und eindeutige Varianzen ermittelt, indem die mit dem Modell der multivariaten Normalverteilung verbundene Likelihood-Funktion maximiert wird. Dies erfolgt äquivalent durch Minimieren eines Ausdrucks, der die Varianzen der Residuen enthält. Der Algorithmus arbeitet iterativ, bis ein Minimum gefunden wird oder die angegebene maximale Anzahl der Iterationen (Standardeinstellung 25) erreicht ist.
Minitab verwendet einen Algorithmus, der auf Joreskog1, 2 beruht und leicht angepasst wurde, um die Konvergenz zu verbessern. Der Algorithmus wird hier kurz zusammengefasst.
Angenommen, es liegen p Variablen vor, und es soll ein Modell mit m Faktoren angepasst werden. Sei R die (p × p)-Korrelationsmatrix der Variablen, L die (p × m)-Matrix der Faktorladungen und Ψ eine diagonale (p × p)-Matrix, deren Diagonalelemente die eindeutigen Varianzen Ψi sind. Dann müssen Werte für L und Ψ gefunden werden, die die Likelihood-Funktion f(L,Ψ) maximieren. Hierzu sind zwei Schritte erforderlich: Erst muss ein Wert für Ψ und dann für L ermittelt werden.
Sie können den Anfangswert von Ψ indirekt festlegen. Geben Sie im Unterdialogfeld „Faktorenanalyse: Optionen“ im Feld Vorabschätzungen der Kommunalitäten verwenden aus die Anfangswerte für die Kommunalitäten ein. Minitab berechnet dann die Diagonalelemente von Ψ als (1 − Kommunalitäten).
Nun wird f(L,Ψ) mit einem festen Wert von Ψ im Hinblick auf L maximiert. Dies ist eine einfache Matrixberechnung. Anschließend wird der Wert von L in f(L,Ψ) eingesetzt. Jetzt kann f als Funktion von Ψ betrachtet werden. Eine einfache Transformation dieser Funktion ergibt
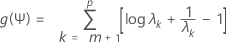
Hierbei sind λ1 < λ2 < ... λp Eigenwerte von Ψ R– 1Ψ. Als Nächstes wird g(Ψ) mit einem Newton-Raphson-Verfahren minimiert. Dies ergibt einen Schätzwert von Ψ, der in die Likelihood-Funktion f(L,Ψ) eingesetzt wird. Danach wird die Likelihood-Funktion wieder im Hinblick auf L maximiert. Anschließend wird ein neuer Wert für g(Ψ) berechnet usw. Standardmäßig werden bis zu 25 Iterationsschritte ausgeführt, sofern keine Konvergenz erreicht wird. Falls der Algorithmus nach 25 Schritten nicht konvergiert, können Sie die maximale Anzahl der Iterationen im Dialogfeld „Optionen“ ändern.
Die Konvergenz wird in Schritt n erreicht, wenn eine der folgenden Aussagen wahr ist:
- Die Funktion g(Ψ) ändert sich von einem Schritt zum nächsten nur noch geringfügig. Spezifischer ausgedrückt:
- | [g(Ψ) bei Schritt n] − [g(Ψ) bei Schritt (n − 1)] | < 10–6
- Alle eindeutigen Varianzen ändern sich von einem Schritt zum nächsten nur noch geringfügig. Spezifischer ausgedrückt:
- | ln(Ψi bei Schritt n) − ln(Ψi bei Schritt n − 1) | < K2,
für alle i = 1, ... , p, wobei Ψi, das i-te Diagonalelement von Ψ, die eindeutige Varianz ist, die der Variablen i entspricht.
Der Wert von K2 kann im Unterdialogfeld „Optionen“ im Feld Konvergenz angegeben werden. Der Standardwert beträgt 0,005.
Wählen Sie im Unterdialogfeld „Ergebnisse“ die Option Alle und ML-Schätzwert-Iterationen aus, um Informationen zu den einzelnen Iterationen anzuzeigen. Der Wert der Zielfunktion g(Ψ) wird angezeigt, dann die größte Änderung in ln(Ψi). Wenn bei einer Iteration der Wert von g(Ψ) nicht abnimmt, wird ein kleinerer (Halb-)Schritt ausgeführt. Die Halbschritte werden fortgesetzt, bis g(Ψ) abnimmt oder 25 Halbschritte erreicht sind. Die Anzahl der Halbschritte wird angezeigt. Wenn g(Ψ) in 25 Halbschritten nicht abgenommen hat, wird der Algorithmus angehalten, und eine Meldung wird angezeigt.
Bei der Minimierung von g(Ψ) wird eine Matrix der zweiten Ableitungen verwendet. Diese Matrix ist nicht immer positiv definit. Wenn sie es nicht ist, wird eine Approximation verwendet. Wenn Minitab die exakte Matrix verwendet, wird in den Ergebnissen ein Sternchen angezeigt.
Bei der Minimierung der Funktion g(Ψ) können für das Diagonalelement von Ψ Werte auftreten, die 0 oder negativ sind. Um dies zu vermeiden, begrenzt der Minitab-Algorithmus die Diagonalelemente von Ψ so, dass sie nicht 0 erreichen können. Spezifischer gesagt, wenn eine eindeutige Varianz Ψi kleiner als K2 ist, wird sie mit K2 gleichgesetzt. K2 ist der Wert, der im Unterdialogfeld „Optionen“ im Feld „Konvergenz“ festgelegt wurde.
Wenn der Algorithmus konvergiert, wird eine abschließende Prüfung der eindeutigen Varianzen durchgeführt. Wenn eindeutige Varianzen kleiner als K2 sind, werden diese gleich 0 gesetzt. Die entsprechende Kommunalität beträgt dann 1. Dieses Ergebnis wird als Heywood-Fall bezeichnet, und Minitab zeigt eine Meldung an, um den Benutzer über dieses Ergebnis zu informieren. Optimierungsalgorithmen, wie z. B. der für die Maximum-Likelihood-Faktorenanalyse verwendete, können bei geringfügigen Änderungen der Eingabe unterschiedliche Ergebnisse liefern. Wenn Sie z. B. auch nur wenige Datenpunkte, die Startwerte in Vorabschätzungen der Kommunalitäten verwenden aus oder das Konvergenzkritrium in Konvergenz ändern, werden Sie möglicherweise unterschiedliche Ergebnisse der Faktorenanalyse feststellen. Dies trifft insbesondere dann zu, wenn die Lösung an einer relativ flachen Stelle der Maximum-Likelihood-Oberfläche liegt.
Rotieren der Ladungen
Eine orthogonale Rotation ist eine orthogonale Transformation der Faktorladungen, die eine leichtere Interpretation der Faktorladungen ermöglicht. Die rotierten Ladungen behalten die Korrelations- oder Kovarianzmatrix, die Residuenmatrix, die spezifischen Varianzen und die Kommunalitäten bei. Da sich die Ladungen ändern, ändern sich die von den einzelnen Faktoren erklärte Varianz und der entsprechende Anteil daran.
Bei der Rotation werden die Achsen dicht an soviel wie möglich Punkten angeordnet und jede Gruppe von Variablen einem Faktor zugeordnet. In einigen Fällen liegen die Variablen jedoch nahe an mehr als einer Achse und werden daher mehr als einem Faktor zugeordnet.
Sie können eine von vier Rotationsmethoden auswählen:
- Equimax: Maximiert die Varianz der quadrierten Ladungen sowohl von Variablen als auch von Faktoren.
- Varimax: Maximiert die Varianz der quadrierten Ladungen innerhalb von Faktoren. Mit dieser Methode werden die Spalten der Ladungsmatrix vereinfacht. Sie ist die am häufigsten verwendete Rotationsmethode. Mit dieser Methode sollen die Ladungen hoch oder niedrig gemacht werden, um die Interpretation zu vereinfachen.
- Quartimax: Maximiert die Varianz der quadrierten Ladungen innerhalb von Variablen. Mit dieser Methode werden die Zeilen der Ladungsmatrix vereinfacht.
- Orthomax mit γ: Eine Rotation, die je nach dem Wert des Parameters Gamma (0–1) die drei oben aufgeführten Rotationen umfasst.
Modell der Faktorenanalyse
Das Modell der Faktorenanalyse lautet:
x = μ + L F + e
Hierbei ist x der (p x 1)-Vektor der Messwerte, μ der (p x 1)-Vektor der Mittelwerte, L eine (p × m)-Matrix der Ladungen, F ein (m × 1)-Vektor der gemeinsamen Faktoren und e ein (p × 1)-Vektor der Residuen Dabei steht p für die Anzahl der Messwerte je Proband, Objekt oder Item und m für die Anzahl der gemeinsamen Faktoren. Es wird angenommen, dass F und e unabhängig sind, und die einzelnen Werte von F sind unabhängig voneinander. Die Mittelwerte von F und e sind 0, Kov(F) = I (die Identitätsmatrix) und Kov(e) = Ψ (eine diagonale Matrix). Aufgrund der Annahme, dass die F-Werte unabhängig sind, handelt es sich hierbei um ein orthogonales Faktorenmodell.
Im Modell für die Faktorenanalyse wird die (p × p)-Kovarianzmatrix der Daten x folgendermaßen berechnet:
Kov(x) = L L' + Ψ
Hierbei ist L die (p × m)-Matrix der Ladungen und Ψ eine (p × p)-Diagonalmatrix. Das i-te Diagonalelement von L, L', die Summe der quadrierten Ladungen, wird als i-te Kommunalität bezeichnet. Die Kommunalitätswerte können als der Prozentsatz der Streuung betrachtet werden, der von den gemeinsamen Faktoren erklärt wird. Das i-te Diagonalelement von Ψ wird als die i-te spezifische Varianz oder Eindeutigkeit bezeichnet. Die spezifische Varianz ist der Anteil der Streuung, der nicht von den gemeinsamen Faktoren erklärt wird. Anhand der Größen der Kommunalitäten und/oder der spezifischen Varianzen kann die Güte der Anpassung beurteilt werden.
Ladungen
Formel
Bei Verwendung der Hauptkomponentenmethode wird die Matrix der geschätzten Faktorladungen L wie folgt angegeben:
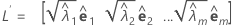
Bei Verwendung der Maximum-Likelihood-Methode wird die Matrix der Faktorladungen durch einen iterativen Prozess berechnet.
Notation
| Begriff | Beschreibung |
|---|---|
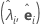 | Eigenwert-Eigenvektor-Paare |
Kommunalitäten
Formel
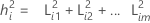
wobei i = 1, 2 ... p
Notation
| Begriff | Beschreibung |
|---|---|
| L | Matrix der Faktorladungen |
Varianz
Die Streuung in den Daten, die von den einzelnen Faktoren erklärt wird. Wenn Sie die Faktoren mit Hilfe der Hauptkomponenten extrahieren und die Ladungen nicht rotieren, ist die Varianz gleich dem Eigenwert.
% Var
Formel
Bei Verwendung einer Korrelationsmatrix wird der vom j-ten Faktor erklärte Anteil an der Varianz folgendermaßen berechnet:
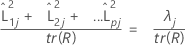
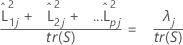
Notation
| Begriff | Beschreibung |
|---|---|
| L | Matrix der Faktorladungen |
| λj | j-ter Eigenwert |
| tr(R) | Spur der Korrelationsmatrix |
| tr(S) | Spur der Kovarianzmatrix |
Koeffizienten
Formel
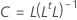
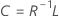
R ist die Korrelationsmatrix. Wenn die zu faktorierende Matrix die Kovarianzmatrix ist, wird R durch die Kovarianzmatrix ersetzt.
Notation
| Begriff | Beschreibung |
|---|---|
| L | Matrix der Faktorladungen |
Werte
Formel
F = ZC
Notation
| Begriff | Beschreibung |
|---|---|
| F | Matrix der Faktorwerte |
| Z | standardisierte Daten |
| C | Matrix der Gewichtungsfaktoren der Faktorwerte |