In diesem Thema
Quadrierte Distanz
Quadrierte Mahalanobis-Distanz – Allgemeine Form
Die quadrierte Distanz (auch als Mahalanobis-Distanz bezeichnet) zwischen Beobachtung x und dem Zentrum (Mittelwert) von Gruppe t für die lineare Diskriminanzfunktion wird durch folgende allgemeine Form angegeben:

Quadrierte Mahalanobis-Distanz – Quadratische Funktion
Die quadrierte Mahalanobis-Distanz zwischen x und der Gruppe t für die quadratische Diskriminanzfunktion wird wie folgt berechnet:

Verallgemeinerte quadrierte Distanz – Lineare Funktion
Die verallgemeinerte quadrierte Distanz zwischen x und der Gruppe t für die lineare Diskriminanzfunktion wird wie folgt berechnet:
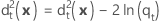
Verallgemeinerte quadrierte Distanz – Quadratische Funktion
Die verallgemeinerte quadrierte Distanz zwischen x und der Gruppe t für die quadratische Diskriminanzfunktion wird wie folgt berechnet:

A-posteriori-Wahrscheinlichkeit
Die A-posteriori-Wahrscheinlichkeit, dass x zu Gruppe t gehört, wird wie folgt berechnet:
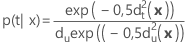
Lineare Diskriminanzwerte
Die linearen Diskriminanzwerte werden wie folgt berechnet:

Notation
| Begriff | Beschreibung |
|---|---|
| x | Spaltenvektor der Länge p, der die Werte des Prädiktors für diese Beobachtung enthält. (Dieser Spaltenvektor wird als eine Zeile gespeichert.) |
| p | Anzahl der Prädiktoren |
| n | Gesamtzahl der Beobachtungen |
| t | Gruppenindex |
| nt | Anzahl der Beobachtungen in Gruppe t |
| qt | A-priori-Wahrscheinlichkeit für Gruppe t, die nt/n entspricht |
| Sp | zusammengefasste Kovarianzmatrix für die lineare Diskriminanzanalyse |
| Si | Kovarianzmatrix von Gruppe i für die quadratische Diskriminanzanalyse |
| mt | Spaltenvektor der Länge p, der die Mittelwerte der Prädiktoren enthält, die aus den Daten in Gruppe t berechnet werden |
| St | Kovarianzmatrix für Gruppe t |
| |St| | Determinante von St |
Lineare Diskriminanzfunktion

Für ein gegebenes x ordnet diese Regel x der Gruppe mit dem größten Wert der linearen Diskriminanzfunktion zu.
Notation
| Begriff | Beschreibung |
|---|---|
| x | Spaltenvektor der Länge p, der die Werte des Prädiktors für diese Beobachtung enthält. (Dieser Spaltenvektor wird als eine Zeile gespeichert.) |
| mi | Spaltenvektor der Länge p, der die Mittelwerte der Prädiktoren enthält, die aus den Daten in Gruppe i berechnet werden |
| Sp | zusammengefasste Kovarianzmatrix |
| ln pi | natürlicher Logarithmus der A-priori-Wahrscheinlichkeit für Gruppe i |
Verallgemeinerte quadrierte Distanz

Notation
| Begriff | Beschreibung |
|---|---|
| x | Spaltenvektor der Länge p, der die Werte des Prädiktors für diese Beobachtung enthält. (Dieser Spaltenvektor wird als eine Zeile gespeichert.) |
| mi | Spaltenvektor der Länge p, der die Mittelwerte der Prädiktoren enthält, die aus den Daten in Gruppe i berechnet werden |
| Sp | zusammengefasste Kovarianzmatrix f |
| ln pi | natürlicher Logarithmus der A-priori-Wahrscheinlichkeit für Gruppe i |
A-posteriori-Wahrscheinlichkeit
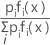
Die größte A-posteriori-Wahrscheinlichkeit entspricht dem höchsten Wert von ln [pi fi (x)]


Notation
| Begriff | Beschreibung |
|---|---|
| pi | A-priori-Wahrscheinlichkeit für Gruppe i |
| fi(x) | gemeinsame Dichte für die Daten in der Gruppe i (wobei die Parameter der Grundgesamtheit durch die Stichprobenschätzwerte ersetzt werden) |