In diesem Thema
Schritt 1: Untersuchen der Ähnlichkeitsniveaus und Distanzstufen
Betrachten Sie bei jedem Schritt des Fusionierungsprozesses die Cluster, die gebildet werden, und untersuchen Sie deren Ähnlichkeitsniveaus und Distanzstufen. Je höher das Ähnlichkeitsniveau, desto ähnlicher (korrelierter) sind die Variablen eines Clusters. Je niedriger die Distanzstufe, desto dichter beieinander liegen die Variablen in einem Cluster.
Im Idealfall sollten die Cluster ein relativ hohes Ähnlichkeitsniveau und eine relativ niedrige Distanzstufe aufweisen. Sie müssen dieses Ziel jedoch gegenüber einer vernünftigen und praktischen Anzahl an Clustern abwägen.
Fusionierungsschritte
| Schritt | Anzahl der Cluster | Ähnlichkeitsniveau | Distanzstufe | Zusammengefasste Cluster | Neuer Cluster | Anzahl der Beobachtungen in neuem Cluster | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93,9666 | 0,120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93,1548 | 0,136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87,3150 | 0,253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79,8113 | 0,403775 | 1 | 2 | 1 | 5 |
Wichtigste Ergebnisse: Ähnlichkeitsniveau, Distanzstufe
In diesen Ergebnissen enthalten die Daten insgesamt 5 Variablen. In Schritt 1 werden zwei Cluster (die Variablen 2 und 3 im Arbeitsblatt) zu einem neuen Cluster zusammengefasst. Damit werden in den Daten 4 Cluster erstellt, die ein Ähnlichkeitsniveau von 96,9666 und eine Distanzstufe von 0,130669 aufweisen. Zwar ist das Ähnlichkeitsniveau hoch und die Distanzstufe niedrig, aber die Anzahl der Cluster ist zu hoch, um nützlich zu sein. Bei jedem nachfolgenden Schritt, bei dem neue Cluster gebildet werden, sinkt das Ähnlichkeitsniveau und steigt die Distanzstufe. Beim letzten Schritt werden alle Variablen zu einem einzigen Cluster zusammengefasst.
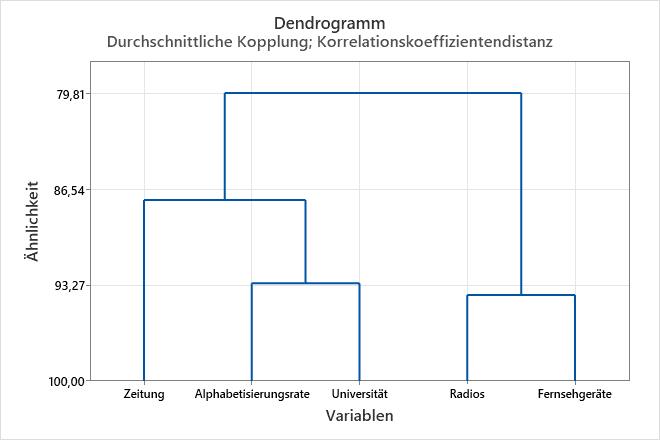
Um die Ähnlichkeitsniveaus im Dendrogramm anzuzeigen, zeigen Sie in Minitab mit dem Mauszeiger auf eine horizontale Linie im Dendrogramm.
Schritt 2: Bestimmen der endgültigen Gruppierungen für die Daten
Verwenden Sie das Ähnlichkeitsniveau für die Cluster, die in den einzelnen Schritten zusammengeführt werden, um die endgültigen Gruppierungen für die Daten zu bestimmen.Suchen Sie nach abrupten Veränderungen des Ähnlichkeitsniveaus zwischen den Schritten. Der Schritt, der der abrupten Veränderung der Ähnlichkeit vorangeht, stellt möglicherweise einen guten Schnittpunkt für die endgültige Partition dar. Für die endgültige Partition sollten die Cluster ein angemessen hohes Ähnlichkeitsniveau aufweisen. Sie sollten auch Ihr Praxiswissen über die Daten anwenden, um die endgültigen Gruppierungen zu bestimmen, die für Ihre Anwendung am sinnvollsten sind.
Die folgende Fusionierungstabelle zeigt beispielsweise, dass das Ähnlichkeitsniveau von Schritt 1 (93,9666) zu Schritt 2 (93,1548) leicht abnimmt. Dann nimmt die Ähnlichkeit in Schritt 3, in dem sich die Anzahl der Cluster von 3 auf 2 ändert, abrupt ab (87,3150). Diese Ergebnisse zeigen, dass 3 Cluster wahrscheinlich für die endgültige Partition geeignet sind. Wenn Ihnen diese Gruppierung intuitiv geeignet erscheint, stellt sie vermutlich eine gute Wahl dar.
Fusionierungsschritte
| Schritt | Anzahl der Cluster | Ähnlichkeitsniveau | Distanzstufe | Zusammengefasste Cluster | Neuer Cluster | Anzahl der Beobachtungen in neuem Cluster | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93,9666 | 0,120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93,1548 | 0,136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87,3150 | 0,253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79,8113 | 0,403775 | 1 | 2 | 1 | 5 |
Wichtigste Ergebnisse: Ähnlichkeitsniveau, Anzahl der Cluster
Die Entscheidung über die endgültige Gruppierung wird auch als Beschneiden des Dendrogramms bezeichnet. Das Beschneiden des Dendrogramms ähnelt dem Zeichnen einer horizontalen Linie durch das Dendrogramm, um die endgültige Gruppierung festzulegen. Um z. B. dieses Dendrogramm in vier Cluster zu zerschneiden, stellen Sie sich vor, etwa auf halber Höhe der vertikalen Achse eine horizontale Linie zu ziehen, direkt unter dem Ähnlichkeitsniveau von ungefähr 88.
Schritt 3: Untersuchen der endgültigen Partition
Nachdem Sie in Schritt 2 die endgültigen Gruppierungen bestimmt haben, wiederholen Sie die Analyse, und geben Sie die Anzahl der Cluster (oder das Ähnlichkeitsniveau) für die endgültige Partition an. Minitab zeigt die Tabelle der endgültigen Partition an, in der die Variablen aufgeführt werden, die die einzelnen Cluster in der endgültigen Partition bilden.
Untersuchen Sie die Cluster in der endgültigen Partition, um zu bestimmen, ob die Gruppierung für Ihre Anwendung sinnvoll erscheint. Wenn Sie noch unsicher sind, können Sie die Analyse wiederholen und Dendrogramme für verschiedene endgültige Gruppierungen vergleichen, um zu entscheiden, welche davon für Ihre Daten am sinnvollsten ist.
Fusionierungsschritte
| Schritt | Anzahl der Cluster | Ähnlichkeitsniveau | Distanzstufe | Zusammengefasste Cluster | Neuer Cluster | Anzahl der Beobachtungen in neuem Cluster | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93,9666 | 0,120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93,1548 | 0,136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87,3150 | 0,253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79,8113 | 0,403775 | 1 | 2 | 1 | 5 |
Endgültige Partition
| Variablen | |
|---|---|
| Cluster 1 | Zeitung |
| Cluster 2 | Radios Fernsehgeräte |
| Cluster 3 | Alphabetisierungsrate Universität |
Wichtigste Ergebnisse: Endgültige Partition, Dendrogramm
In diesen Ergebnissen bilden drei Cluster die endgültige Partition:
- Verkaufte Zeitungen pro 1.000 Einwohner
- Anzahl der Radios und Fernsehgeräte
- Alphabetisierungsrate und Präsenz einer Universität in der Stadt
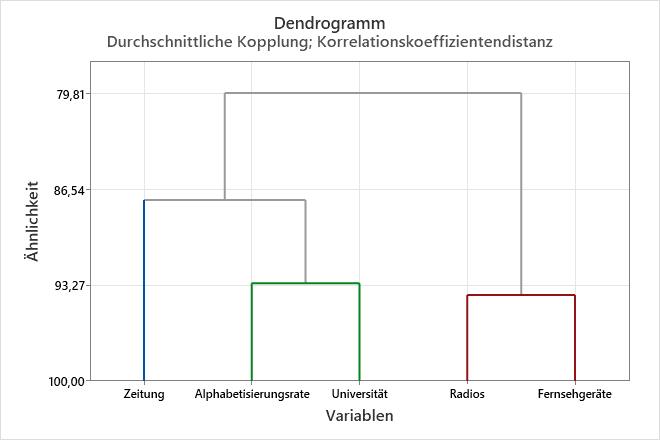
Dieses Dendrogramm wurde unter Verwendung einer endgültigen Partition aus 3 Clustern erstellt. Jedes endgültige Cluster wird durch eine andere Farbe dargestellt. Das Dendrogramm wurde bei einem Ähnlichkeitsniveau von ungefähr 88 beschnitten. Wenn Sie das Dendrogramm weiter oben beschnitten hätten, wären weniger endgültige Cluster vorhanden, aber das Ähnlichkeitsniveau wäre geringer. Wenn Sie das Dendrogramm weiter unten beschnitten hätten, wäre das Ähnlichkeitsniveau größer, aber Sie hätten mehr endgültige Cluster.