In diesem Thema
Schritt
Die Nummer des Schritts im Fusionierungsprozess zur Zusammenführung der Cluster. Bei jedem Schritt wird ein neuer Cluster mit einem vorhandenen zusammengeführt, und das Ähnlichkeitsniveau und die Distanzstufe werden berechnet.
Anzahl der Cluster
Die Anzahl der Cluster, die in jedem Schritt des Fusionierungsprozesses gebildet werden. Vor dem ersten Schritt entspricht die Anzahl der Cluster der Gesamtzahl der Beobachtungen (bei Clusterbeobachtungen) bzw. der Gesamtzahl der Variablen (bei Clustervariablen). Im ersten Schritt werden zwei Cluster zu einem neuen Cluster zusammengefasst. Bei jedem nachfolgenden Schritt wird ein weiterer Cluster mit einem vorhandenen zusammengefasst, um einen neuen Cluster zu bilden. Im letzten Schritt werden alle Beobachtungen oder Variablen zu einem einzigen Cluster zusammengefasst.
Sie können die Anzahl der Cluster im Hauptdialogfeld eingeben, um die endgültige Partition für die Daten festzulegen. Das Clusterergebnis wird in erheblichem Maße von Ihrer Auswahl des agglomerativen Verfahrens und des Distanzmaßes beeinflusst.
Ähnlichkeitsniveau
Der Prozentsatz der minimalen Distanz zwischen den Clustern bei jedem Fusionierungsschritt relativ zur maximalen Distanz zwischen den Beobachtungen in den Daten. Die Ähnlichkeit s(ij) zwischen den beiden Clustern i und j wird durch die Gleichung s(ij) = 100 * [1 – d(ij)) / d(max)] berechnet, wobei d(max) der maximale Wert in der ursprünglichen Distanzmatrix D ist und der Eintrag d(ij) für die Distanz zwischen i und j steht.
Interpretation
Verwenden Sie das Ähnlichkeitsniveau für die Cluster, die in den einzelnen Schritten zusammengeführt werden, um die endgültigen Gruppierungen für die Daten zu bestimmen.Suchen Sie nach abrupten Veränderungen des Ähnlichkeitsniveaus zwischen den Schritten. Der Schritt, der der abrupten Veränderung der Ähnlichkeit vorangeht, stellt möglicherweise einen guten Schnittpunkt für die endgültige Partition dar. Für die endgültige Partition sollten die Cluster ein angemessen hohes Ähnlichkeitsniveau aufweisen. Sie sollten auch Ihr Praxiswissen über die Daten anwenden, um die endgültigen Gruppierungen zu bestimmen, die für Ihre Anwendung am sinnvollsten sind.
Die folgende Fusionierungstabelle zeigt beispielsweise, dass das Ähnlichkeitsniveau von Schritt 1 (93,9666) zu Schritt 2 (93,1548) leicht abnimmt. Dann nimmt die Ähnlichkeit in Schritt 3, in dem sich die Anzahl der Cluster von 3 auf 2 ändert, abrupt ab (87,3150). Diese Ergebnisse zeigen, dass 3 Cluster wahrscheinlich für die endgültige Partition geeignet sind. Wenn Ihnen diese Gruppierung intuitiv geeignet erscheint, stellt sie vermutlich eine gute Wahl dar.
Fusionierungsschritte
| Schritt | Anzahl der Cluster | Ähnlichkeitsniveau | Distanzstufe | Zusammengefasste Cluster | Neuer Cluster | Anzahl der Beobachtungen in neuem Cluster | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93,9666 | 0,120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93,1548 | 0,136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87,3150 | 0,253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79,8113 | 0,403775 | 1 | 2 | 1 | 5 |
Distanzstufe
Die Distanz zwischen Clustern (unter Verwendung des ausgewählten agglomerativen Verfahrens) oder Variablen (unter Verwendung des ausgewählten Distanzmaßes), die in den einzelnen Schritten zusammengefasst werden. Minitab berechnet die Distanzstufe auf der Grundlage des agglomerativen Verfahrens und des Distanzmaßes, die Sie im Hauptdialogfeld ausgewählt haben.
Die Distanz zwischen zwei Variablen steht in direktem Bezug zu deren Korrelation. Das heißt, für zwei Variablen x1 und x2 entspricht die Distanz 1 – Korrelation. Wenn z. B. die Korrelation(x1, x2) = 0,879, dann beträgt die Distanz(x1, x2) = 1 – 0,879 = 0,121.
Interpretation
Verwenden Sie die Distanzstufe für die Cluster, die in den einzelnen Schritten zusammengeführt werden, um die endgültigen Gruppierungen für die Daten zu bestimmen. Suchen Sie nach abrupten Veränderungen der Distanzstufe zwischen den Schritten. Der Schritt, der der abrupten Veränderung der Distanz vorangeht, stellt möglicherweise einen guten Schnittpunkt für die endgültige Partition dar. Für die endgültige Partition sollten die Cluster eine angemessen kleine Distanzstufe aufweisen. Sie sollten auch Ihr Praxiswissen über die Daten anwenden, um die endgültigen Gruppierungen zu bestimmen, die für Ihre Anwendung am sinnvollsten sind.
Die folgende Fusionierungstabelle zeigt beispielsweise, dass die Distanzstufe von Schritt 1 (0,120669) zu Schritt 2 (0,136904) leicht ansteigt. Die Distanz steigert sich dann mit Schritt 3, bei dem sich die Anzahl der Cluster von 3 auf 2 ändert, stärker auf (0,253700). Diese Ergebnisse zeigen, dass 3 Cluster wahrscheinlich für die endgültige Partition geeignet sind. Wenn Ihnen diese Gruppierung intuitiv geeignet erscheint, stellt sie vermutlich eine gute Wahl dar.
Fusionierungsschritte
| Schritt | Anzahl der Cluster | Ähnlichkeitsniveau | Distanzstufe | Zusammengefasste Cluster | Neuer Cluster | Anzahl der Beobachtungen in neuem Cluster | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93,9666 | 0,120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93,1548 | 0,136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87,3150 | 0,253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79,8113 | 0,403775 | 1 | 2 | 1 | 5 |
Zusammengefasste Cluster
Die beiden Cluster, die in jedem Schritt des Fusionierungsprozesses zusammengefasst werden, um einen neuen Cluster zu bilden.
Neuer Cluster
Die Identifikationsnummer des neuen Clusters, der in jedem Schritt des Fusionierungsprozesses gebildet wird. Die Identifikationsnummer des neuen Clusters ist immer die kleinere der beiden Identifikationsnummern der zwei zusammengefassten Cluster. Wenn z. B. Cluster 2 und Cluster 9 zusammengefasst werden, wird der neu entstandene Cluster als Cluster 2 bezeichnet.
Anzahl der Beobachtungen im neuen Cluster
Die Anzahl der Beobachtungen in jedem neuen Cluster, der in jedem Schritt des Fusionierungsprozesses gebildet wird. Im letzten Schritt werden alle Beobachtungen in einem einzigen Cluster kombiniert. Daher entspricht die Anzahl der Beobachtungen im neuen Cluster für den letzten Schritt der Gesamtzahl der Beobachtungen in den Daten.
Hinweis
Für Clustervariablen entspricht die Anzahl der Beobachtungen der Anzahl der Variablen im neuen Cluster.
Endgültige Partition
Wenn Sie im Hauptdialogfeld eine endgültige Partition angeben, zeigt Minitab eine Liste der Variablen in den einzelnen Clustern an. Die Variablen in den einzelnen Clustern der endgültigen Partition sollten für Ihre jeweilige Anwendung intuitiv sinnvoll erscheinen.
Dendrogramm
Das Dendrogramm ist ein Baumdiagramm, in dem die Gruppen, die durch Clustern von Variablen bei jedem Schritt gebildet wurden, und deren Ähnlichkeitsniveaus dargestellt werden. Das Ähnlichkeitsniveau (alternativ die Distanzstufe) wird entlang der vertikalen Achse und die verschiedenen Variablen entlang der horizontalen Achse abgetragen.
Interpretation
Verwenden Sie das Dendrogramm, um zu sehen, wie die Cluster in den einzelnen Schritten gebildet wurden, und um die Ähnlichkeitsniveaus (oder Distanzstufen) der gebildeten Cluster zu untersuchen.
Um die Ähnlichkeitsniveaus (oder Distanzstufen) anzuzeigen, zeigen Sie mit dem Mauszeiger auf eine horizontale Linie im Dendrogramm. Das Muster der Änderungen der Ähnlichkeits- oder Distanzwerte zwischen den einzelnen Schritten bietet Orientierung für die Auswahl der endgültigen Gruppierung Ihrer Daten. Der Schritt, bei dem sich die Werte abrupt ändern, kann eine gute Stelle zum Definieren der endgültigen Gruppierungen sein.
Die Entscheidung über die endgültige Gruppierung wird auch als Beschneiden des Dendrogramms bezeichnet. Das Beschneiden des Dendrogramms ähnelt dem Zeichnen einer Linie durch das Dendrogramm, um die endgültige Gruppierung festzulegen. Ein Vergleich von Dendrogrammen für unterschiedliche endgültige Gruppierungen kann auch die Entscheidung erleichtern, welche davon für Ihre Daten am sinnvollsten ist.
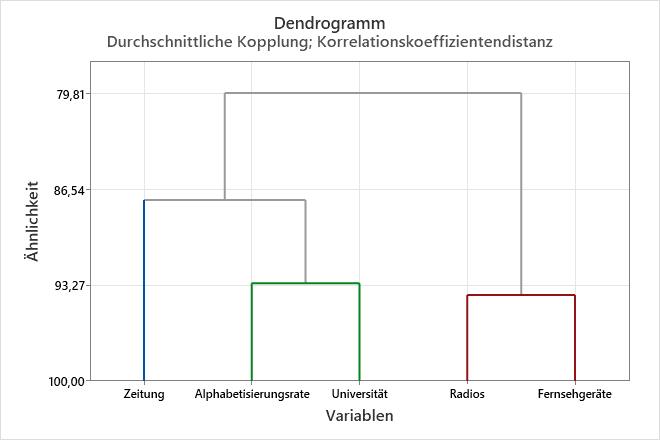
Dieses Dendrogramm wurde unter Verwendung einer endgültigen Partition aus 3 Clustern erstellt. Jedes endgültige Cluster wird durch eine andere Farbe dargestellt. Das Dendrogramm wurde bei einem Ähnlichkeitsniveau von ungefähr 88 „beschnitten“. Wenn Sie das Dendrogramm weiter oben beschnitten hätten, wären weniger endgültige Cluster vorhanden, aber das Ähnlichkeitsniveau wäre geringer. Wenn Sie das Dendrogramm weiter unten beschnitten hätten, wäre das Ähnlichkeitsniveau größer, aber Sie hätten mehr endgültige Cluster.
Hinweis
Bei einigen Datensätzen führen die durchschnittliche, Zentroid-, Median- oder Ward-Methode möglicherweise nicht zu einem hierarchischen Dendrogramm. Dies bedeutet, dass die Fusionierungsdistanzen nicht immer mit jedem Schritt zunehmen. Im Dendrogramm führt ein solcher Schritt zu einer Verbindungslinie nach unten und nicht nach oben.