In diesem Thema
Schritt 1: Untersuchen der Ähnlichkeitsniveaus und Distanzstufen
Betrachten Sie bei jedem Schritt des Fusionierungsprozesses die Cluster, die gebildet werden, und untersuchen Sie deren Ähnlichkeitsniveaus und Distanzstufen. Je höher das Ähnlichkeitsniveau, desto ähnlicher sind sich die Beobachtungen eines Clusters. Je niedriger die Distanzstufe, desto dichter beieinander liegen die Beobachtungen in einem Cluster.
Im Idealfall sollten die Cluster ein relativ hohes Ähnlichkeitsniveau und eine relativ niedrige Distanzstufe aufweisen. Sie müssen dieses Ziel jedoch gegenüber einer vernünftigen und praktischen Anzahl an Clustern abwägen.
Fusionierungsschritte
| Schritt | Anzahl der Cluster | Ähnlichkeitsniveau | Distanzstufe | Zusammengefasste Cluster | Neuer Cluster | Anzahl der Beobachtungen in neuem Cluster | |
|---|---|---|---|---|---|---|---|
| 1 | 19 | 96,6005 | 0,16275 | 13 | 16 | 13 | 2 |
| 2 | 18 | 95,4642 | 0,21715 | 17 | 20 | 17 | 2 |
| 3 | 17 | 95,2648 | 0,22669 | 6 | 9 | 6 | 2 |
| 4 | 16 | 92,9178 | 0,33905 | 17 | 18 | 17 | 3 |
| 5 | 15 | 90,5296 | 0,45339 | 11 | 15 | 11 | 2 |
| 6 | 14 | 90,3124 | 0,46378 | 12 | 19 | 12 | 2 |
| 7 | 13 | 88,2431 | 0,56285 | 2 | 14 | 2 | 2 |
| 8 | 12 | 88,2431 | 0,56285 | 5 | 8 | 5 | 2 |
| 9 | 11 | 85,9744 | 0,67146 | 6 | 10 | 6 | 3 |
| 10 | 10 | 83,0639 | 0,81080 | 7 | 13 | 7 | 3 |
| 11 | 9 | 83,0639 | 0,81080 | 1 | 3 | 1 | 2 |
| 12 | 8 | 81,4039 | 0,89027 | 2 | 17 | 2 | 5 |
| 13 | 7 | 79,8185 | 0,96617 | 6 | 11 | 6 | 5 |
| 14 | 6 | 78,7534 | 1,01716 | 4 | 12 | 4 | 3 |
| 15 | 5 | 66,2112 | 1,61760 | 2 | 5 | 2 | 7 |
| 16 | 4 | 62,0036 | 1,81904 | 1 | 6 | 1 | 7 |
| 17 | 3 | 41,0474 | 2,82229 | 1 | 4 | 1 | 10 |
| 18 | 2 | 40,1718 | 2,86421 | 2 | 7 | 2 | 10 |
| 19 | 1 | 0,0000 | 4,78739 | 1 | 2 | 1 | 20 |
Wichtigste Ergebnisse: Ähnlichkeitsniveau, Distanzstufe
In diesen Ergebnissen enthalten die Daten insgesamt 20 Beobachtungen. In Schritt 1 werden zwei Cluster (die Beobachtungen 13 und 16 im Arbeitsblatt) zu einem neuen Cluster zusammengefasst. Mit diesem Schritt werden in den Daten 19 Cluster erstellt, die ein Ähnlichkeitsniveau von 96,6005 und eine Distanzstufe von 0,16275 aufweisen. Zwar ist das Ähnlichkeitsniveau hoch und die Distanzstufe niedrig, aber die Anzahl der Cluster ist zu hoch, um nützlich zu sein. Bei jedem nachfolgenden Schritt, bei dem neue Cluster gebildet werden, sinkt das Ähnlichkeitsniveau und steigt die Distanzstufe. Im letzten Schritt werden alle Beobachtungen zu einem einzigen Cluster zusammengefasst.
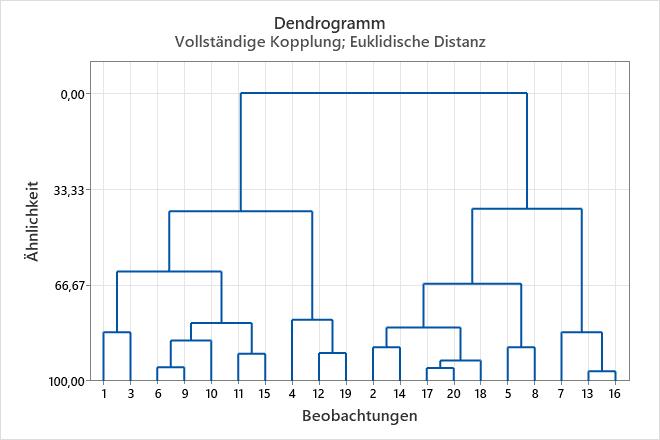
Um die Ähnlichkeitsniveaus im Dendrogramm anzuzeigen, zeigen Sie in Minitab mit dem Mauszeiger auf eine horizontale Linie im Dendrogramm.
Schritt 2: Bestimmen der endgültigen Gruppierungen für die Daten
Verwenden Sie das Ähnlichkeitsniveau für die Cluster, die in den einzelnen Schritten zusammengeführt werden, um die endgültigen Gruppierungen für die Daten zu bestimmen.Suchen Sie nach abrupten Veränderungen des Ähnlichkeitsniveaus zwischen den Schritten. Der Schritt, der der abrupten Veränderung der Ähnlichkeit vorangeht, stellt möglicherweise einen guten Schnittpunkt für die endgültige Partition dar. Für die endgültige Partition sollten die Cluster ein angemessen hohes Ähnlichkeitsniveau aufweisen. Sie sollten auch Ihr Praxiswissen über die Daten anwenden, um die endgültigen Gruppierungen zu bestimmen, die für Ihre Anwendung am sinnvollsten sind.
Die folgende Fusionierungstabelle zeigt beispielsweise, dass das Ähnlichkeitsniveau bis Schritt 15 jeweils ungefähr um höchstens 3 abnimmt. In den Schritten 16 und 17, bei denen sich die Anzahl der Cluster von 4 auf 3 ändert, nimmt die Ähnlichkeit um mehr als 20 ab (von 62,0036 auf 41,0474). Diese Ergebnisse legen nahe, dass 4 Cluster für die endgültige Partition ausreichen. Wenn Ihnen diese Gruppierung intuitiv geeignet erscheint, stellt sie vermutlich eine gute Wahl dar.
Fusionierungsschritte
| Schritt | Anzahl der Cluster | Ähnlichkeitsniveau | Distanzstufe | Zusammengefasste Cluster | Neuer Cluster | Anzahl der Beobachtungen in neuem Cluster | |
|---|---|---|---|---|---|---|---|
| 1 | 19 | 96,6005 | 0,16275 | 13 | 16 | 13 | 2 |
| 2 | 18 | 95,4642 | 0,21715 | 17 | 20 | 17 | 2 |
| 3 | 17 | 95,2648 | 0,22669 | 6 | 9 | 6 | 2 |
| 4 | 16 | 92,9178 | 0,33905 | 17 | 18 | 17 | 3 |
| 5 | 15 | 90,5296 | 0,45339 | 11 | 15 | 11 | 2 |
| 6 | 14 | 90,3124 | 0,46378 | 12 | 19 | 12 | 2 |
| 7 | 13 | 88,2431 | 0,56285 | 2 | 14 | 2 | 2 |
| 8 | 12 | 88,2431 | 0,56285 | 5 | 8 | 5 | 2 |
| 9 | 11 | 85,9744 | 0,67146 | 6 | 10 | 6 | 3 |
| 10 | 10 | 83,0639 | 0,81080 | 7 | 13 | 7 | 3 |
| 11 | 9 | 83,0639 | 0,81080 | 1 | 3 | 1 | 2 |
| 12 | 8 | 81,4039 | 0,89027 | 2 | 17 | 2 | 5 |
| 13 | 7 | 79,8185 | 0,96617 | 6 | 11 | 6 | 5 |
| 14 | 6 | 78,7534 | 1,01716 | 4 | 12 | 4 | 3 |
| 15 | 5 | 66,2112 | 1,61760 | 2 | 5 | 2 | 7 |
| 16 | 4 | 62,0036 | 1,81904 | 1 | 6 | 1 | 7 |
| 17 | 3 | 41,0474 | 2,82229 | 1 | 4 | 1 | 10 |
| 18 | 2 | 40,1718 | 2,86421 | 2 | 7 | 2 | 10 |
| 19 | 1 | 0,0000 | 4,78739 | 1 | 2 | 1 | 20 |
Wichtigste Ergebnisse: Ähnlichkeitsniveau, Anzahl der Cluster
Die Entscheidung über die endgültige Gruppierung wird auch als Beschneiden des Dendrogramms bezeichnet. Das Beschneiden des Dendrogramms ähnelt dem Zeichnen einer horizontalen Linie durch das Dendrogramm, um die endgültige Gruppierung festzulegen. Um z. B. dieses Dendrogramm in vier Cluster zu zerschneiden, stellen Sie sich vor, etwa auf halber Höhe der vertikalen Achse eine horizontale Linie zu ziehen, direkt unter dem Ähnlichkeitsniveau von ungefähr 41.
Schritt 3: Untersuchen der endgültigen Partition
Nachdem Sie in Schritt 2 die endgültigen Gruppierungen bestimmt haben, führen Sie die Analyse erneut aus, und geben Sie die Anzahl der Cluster (oder das Ähnlichkeitsniveau) für die endgültige Partition an. Minitab zeigt die Tabelle der endgültigen Partition an, in der die Merkmale der einzelnen Cluster in der endgültigen Partition aufgeführt werden. Die durchschnittliche Distanz zum Zentroiden ist z. B. ein Maß für die Streuung der Beobachtungen innerhalb eines Clusters.
Hinweis
Weitere Informationen zu diesen Statistiken finden Sie unter Endgültige Partition.
Endgültige Partition
| Anzahl der Beobachtungen | Summe der Quadrate innerhalb des Clusters | Durchschnittliche Distanz von Zentroid | Maximale Distanz von Zentroid | |
|---|---|---|---|---|
| Cluster1 | 7 | 3,25713 | 0,612540 | 1,12081 |
| Cluster2 | 7 | 2,72247 | 0,581390 | 0,95186 |
| Cluster3 | 3 | 0,55977 | 0,398964 | 0,54907 |
| Cluster4 | 3 | 0,37116 | 0,326533 | 0,48848 |
Cluster-Zentroide
| Variable | Cluster1 | Cluster2 | Cluster3 | Cluster4 | Gesamtzentroid |
|---|---|---|---|---|---|
| Geschlecht | 0,97468 | -0,97468 | 0,97468 | -0,97468 | -0,0000000 |
| Größe | -1,00352 | 1,01283 | -0,37277 | 0,35105 | 0,0000000 |
| Gewicht | -0,90672 | 0,93927 | -0,86797 | 0,79203 | -0,0000000 |
| Händigkeit | 0,63808 | 0,63808 | -1,48885 | -1,48885 | 0,0000000 |
Distanzen zwischen Cluster-Zentroiden
| Cluster1 | Cluster2 | Cluster3 | Cluster4 | |
|---|---|---|---|---|
| Cluster1 | 0,00000 | 3,35759 | 2,21882 | 3,61171 |
| Cluster2 | 3,35759 | 0,00000 | 3,67557 | 2,23236 |
| Cluster3 | 2,21882 | 3,67557 | 0,00000 | 2,66074 |
| Cluster4 | 3,61171 | 2,23236 | 2,66074 | 0,00000 |
Wichtigste Ergebnisse: Endgültige Partition, Dendrogramm
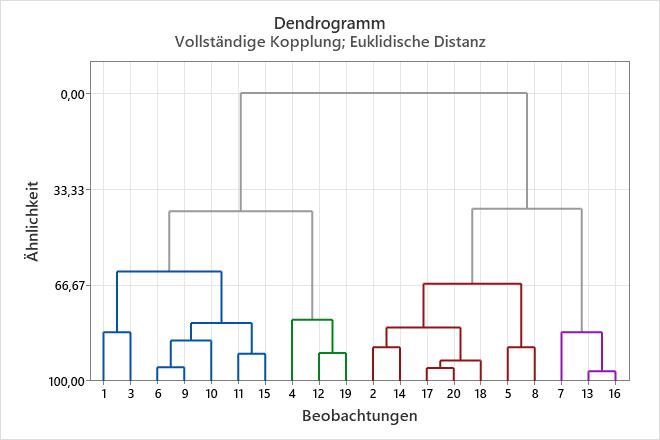
Dieses Dendrogramm wurde unter Verwendung einer endgültigen Partition aus 4 Clustern erstellt, die bei einem Ähnlichkeitsniveau von ungefähr 40 erreicht wurde. Der erste Cluster (ganz links) setzt sich aus 7 Beobachtungen zusammen (die Beobachtungen in den Zeilen 1, 3, 6, 9, 10, 11 und 15 des Arbeitsblatts). Der zweite Cluster, direkt rechts daneben, besteht aus 3 Beobachtungen (den Beobachtungen in den Zeilen 4, 12 und 19 des Arbeitsblatts). Der dritte Cluster setzt sich aus 7 Beobachtungen zusammen (die Beobachtungen in den Zeilen 2, 14, 17, 20, 18, 5 und 8). Der vierte Cluster (ganz rechts) setzt sich aus 3 Beobachtungen zusammen (den Beobachtungen in den Zeilen 7, 13 und 16). Wenn Sie das Dendrogramm weiter oben beschneiden würden, wären weniger endgültige Cluster vorhanden, aber das Ähnlichkeitsniveau wäre geringer. Wenn Sie das Dendrogramm weiter unten beschneiden würden, wäre das Ähnlichkeitsniveau größer, aber Sie hätten mehr endgültige Cluster.