Ein Designer von Sportartikeln für einen Sportausstatter möchte neue Torwarthandschuhe testen. Der Designer bittet 20 Sportler, die neuen Handschuhe auszuprobieren, und erfasst deren Geschlecht, Größe, Gewicht und Händigkeit. Der Designer möchte die Sportler nach Ähnlichkeiten gruppieren.
- Öffnen Sie den Beispieldatensatz Handschuhtester.MWX.
- Wählen Sie aus.
- Geben Sie im Feld Variablen oder Distanzmatrix die Spalten GeschlechtGrößeGewichtHändigkeit ein.
- Wählen Sie im Feld Agglomeratives Verfahren die Option Vollständig aus. Wählen Sie im Feld Distanzmaß die Option Euklidisch aus.
- Wählen Sie Variablen standardisieren aus.
- Wählen Sie Dendrogramm anzeigen aus.
- Klicken Sie auf OK.
Interpretieren der Ergebnisse
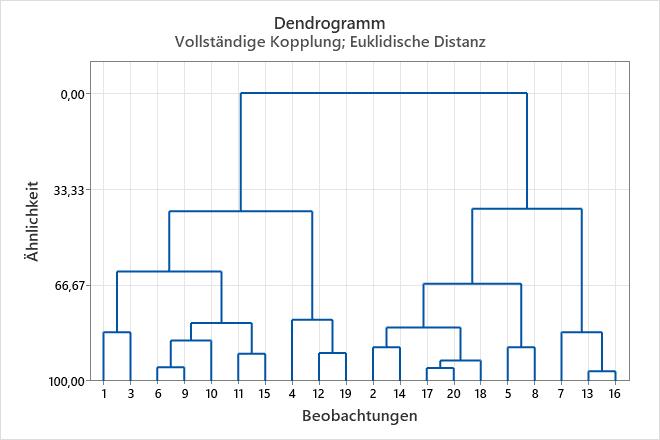
- Das Ähnlichkeitsniveau nimmt bis Schritt 15 jeweils ungefähr um maximal 3 ab. In den Schritten 16 und 17, bei denen sich die Anzahl der Cluster von 4 auf 3 ändert, nimmt die Ähnlichkeit um mehr als 20 ab (von 62,0036 auf 41,0474).
- Die Distanz zwischen den zusammengefassten Clustern nimmt zu, zuerst um maximal ungefähr 0,6. In den Schritten 16 und 17, bei denen sich die Anzahl der Cluster von 4 auf 3 ändert, steigt die Distanz um mehr als 1 an (von 1,81904 auf 2,82229).
Diese Ergebnisse in Hinblick auf Ähnlichkeit und Distanz legen nahe, dass 4 Cluster für die endgültige Partition ausreichen. Wenn diese Gruppierung dem Designer intuitiv geeignet erscheint, stellt sie vermutlich eine gute Wahl dar. Im Dendrogramm werden die Informationen in der Tabelle in Form eines Baumdiagramms angezeigt.
Der Designer sollte die Analyse erneut ausführen und für die endgültige Partition 4 Cluster angeben. Wenn Sie eine endgültige Partition angeben, zeigt Minitab zusätzliche Tabellen an, in denen die Merkmale jedes in der endgültigen Partition enthaltenen Clusters beschrieben werden.
Fusionierungsschritte
| Schritt | Anzahl der Cluster | Ähnlichkeitsniveau | Distanzstufe | Zusammengefasste Cluster | Neuer Cluster | Anzahl der Beobachtungen in neuem Cluster | |
|---|---|---|---|---|---|---|---|
| 1 | 19 | 96,6005 | 0,16275 | 13 | 16 | 13 | 2 |
| 2 | 18 | 95,4642 | 0,21715 | 17 | 20 | 17 | 2 |
| 3 | 17 | 95,2648 | 0,22669 | 6 | 9 | 6 | 2 |
| 4 | 16 | 92,9178 | 0,33905 | 17 | 18 | 17 | 3 |
| 5 | 15 | 90,5296 | 0,45339 | 11 | 15 | 11 | 2 |
| 6 | 14 | 90,3124 | 0,46378 | 12 | 19 | 12 | 2 |
| 7 | 13 | 88,2431 | 0,56285 | 2 | 14 | 2 | 2 |
| 8 | 12 | 88,2431 | 0,56285 | 5 | 8 | 5 | 2 |
| 9 | 11 | 85,9744 | 0,67146 | 6 | 10 | 6 | 3 |
| 10 | 10 | 83,0639 | 0,81080 | 7 | 13 | 7 | 3 |
| 11 | 9 | 83,0639 | 0,81080 | 1 | 3 | 1 | 2 |
| 12 | 8 | 81,4039 | 0,89027 | 2 | 17 | 2 | 5 |
| 13 | 7 | 79,8185 | 0,96617 | 6 | 11 | 6 | 5 |
| 14 | 6 | 78,7534 | 1,01716 | 4 | 12 | 4 | 3 |
| 15 | 5 | 66,2112 | 1,61760 | 2 | 5 | 2 | 7 |
| 16 | 4 | 62,0036 | 1,81904 | 1 | 6 | 1 | 7 |
| 17 | 3 | 41,0474 | 2,82229 | 1 | 4 | 1 | 10 |
| 18 | 2 | 40,1718 | 2,86421 | 2 | 7 | 2 | 10 |
| 19 | 1 | 0,0000 | 4,78739 | 1 | 2 | 1 | 20 |
Endgültige Partition
| Anzahl der Beobachtungen | Summe der Quadrate innerhalb des Clusters | Durchschnittliche Distanz von Zentroid | Maximale Distanz von Zentroid | |
|---|---|---|---|---|
| Cluster1 | 20 | 76 | 1,91323 | 2,53613 |