In diesem Thema
- Schritt 1: Bestimmen, welche Terme am stärksten zur Streuung der Antwortvariablen beitragen
- Schritt 2: Bestimmen, ob die Assoziation zwischen der Antwortvariablen und dem Term statistisch signifikant ist
- Schritt 3: Bestimmen, wie gut das Modell an die Daten angepasst ist
- Schritt 4: Bestimmen, ob das Modell die Annahmen der Analyse erfüllt
Schritt 1: Bestimmen, welche Terme am stärksten zur Streuung der Antwortvariablen beitragen
Verwenden Sie ein Pareto-Diagramm der standardisierten Effekte, um die relative Größe und die statistische Signifikanz von Haupteffekten, quadratischen Effekten und Wechselwirkungseffekten zu vergleichen. Wenn das Modell einen Fehlerterm enthält, werden im Diagramm die Absolutwerte der standardisierten Effekte angezeigt. Wenn das Modell keinen Fehlerterm enthält, erstellt Minitab kein Pareto-Diagramm.
Minitab stellt die standardisierten Effekte in absteigender Reihenfolge ihrer Absolutwerte dar. Die Referenzlinie im Diagramm zeigt, welche Effekte signifikant sind. In der Standardeinstellung zeichnet Minitab die Referenzlinie unter Verwendung eines Signifikanzniveaus von 0,05.
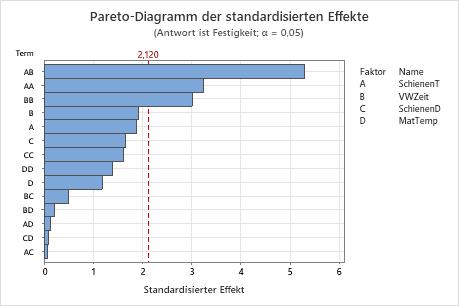
Wichtigste Ergebnisse: Pareto-Diagramm
In diesen Ergebnissen sind die Wechselwirkung zwischen „SchienenT“ und „VWZeit“ (AB) und die quadrierten Terme für „SchienenT“ (AA) und „VWZeit“ (BB) bei einem Signifikanzniveau von α = 0,05 signifikant.
Außerdem ist hier ersichtlich, dass „SchienenT*VWZeit“ (AB) den größten Effekt darstellt, da der entsprechende Balken am längsten ist. „SchienenT*SchienenD“ (AC) stellt den kleinsten Effekt dar, da der entsprechende Balken am kürzesten ist.
Schritt 2: Bestimmen, ob die Assoziation zwischen der Antwortvariablen und dem Term statistisch signifikant ist
Um zu bestimmen, ob die Assoziation zwischen der Antwortvariablen und jedem Term im Modell statistisch signifikant ist, vergleichen Sie den p-Wert für den Term mit dem Signifikanzniveau, um die Nullhypothese auszuwerten. Die Nullhypothese besagt, dass der Koeffizient des Terms gleich null ist, was bedeutet, dass keine Assoziation zwischen dem Term und der Antwortvariablen besteht. In der Regel ist ein Signifikanzniveau (als α oder Alpha bezeichnet) von 0,05 gut geeignet. Ein Signifikanzniveau von 0,05 bedeutet ein Risiko, dass auf eine vorhandene Assoziation geschlossen wird, während tatsächlich keine vorhanden ist, von 5 %.
- p-Wert ≤ α: Die Assoziation ist statistisch signifikant
- Wenn der p-Wert kleiner oder gleich dem Signifikanzniveau ist, können Sie schlussfolgern, dass eine statistisch signifikante Assoziation zwischen der Antwortvariablen und dem Term besteht.
- p-Wert > α: Die Assoziation ist statistisch nicht signifikant
- Wenn der p-Wert größer als das Signifikanzniveau ist, können Sie nicht schlussfolgern, dass eine statistisch signifikante Assoziation zwischen der Antwortvariablen und dem Term besteht. Es empfiehlt sich möglicherweise, das Modell ohne den Term erneut anzupassen.
Wenn ein Modellterm statistisch signifikant ist, hängt die Interpretation von der Art des Terms ab. Die Interpretationen lauten wie folgt:
- Wenn ein Koeffizient für einen Faktor signifikant ist, können Sie schlussfolgern, dass nicht alle Mittelwerte der Faktorstufen gleich sind.
- Wenn ein Koeffizient für einen quadrierten Term signifikant ist, können Sie schlussfolgern, dass die Beziehung zwischen dem Faktor und der Antwortvariablen einer gekrümmten Linie folgt.
- Wenn ein Koeffizient für einen Wechselwirkungsterm signifikant ist, hängt die Beziehung zwischen einem Faktor und der Antwortvariablen von den anderen Faktoren im Term ab. In diesem Fall sollten Sie die Haupteffekte nicht interpretieren, ohne dabei den Wechselwirkungseffekt zu berücksichtigen.
Wichtigste Ergebnisse: p-Wert, Koeffizienten
In diesen Ergebnissen sind die quadrierten Terme für „SchienenT“ und „VWZeit“ sowie die Wechselwirkung zwischen „SchienenT“ und „VWZeit“ bei einem Signifikanzniveau von α = 0,05 signifikant.
Varianzanalyse
| Quelle | DF | Kor SS | Kor MS | F-Wert | p-Wert |
|---|---|---|---|---|---|
| Modell | 14 | 1137,51 | 81,251 | 4,19 | 0,004 |
| Linear | 4 | 218,65 | 54,662 | 2,82 | 0,060 |
| SchienenT | 1 | 68,13 | 68,129 | 3,52 | 0,079 |
| VWZeit | 1 | 70,94 | 70,939 | 3,66 | 0,074 |
| SchienenD | 1 | 52,62 | 52,616 | 2,71 | 0,119 |
| MatTemp | 1 | 26,96 | 26,963 | 1,39 | 0,255 |
| Quadratisch | 4 | 372,07 | 93,018 | 4,80 | 0,010 |
| SchienenT*SchienenT | 1 | 202,61 | 202,611 | 10,45 | 0,005 |
| VWZeit*VWZeit | 1 | 175,32 | 175,318 | 9,05 | 0,008 |
| SchienenD*SchienenD | 1 | 50,52 | 50,522 | 2,61 | 0,126 |
| MatTemp*MatTemp | 1 | 37,87 | 37,866 | 1,95 | 0,181 |
| 2-Faktor-Wechselwirkung | 6 | 546,79 | 91,132 | 4,70 | 0,006 |
| SchienenT*VWZeit | 1 | 540,47 | 540,470 | 27,89 | 0,000 |
| SchienenT*SchienenD | 1 | 0,12 | 0,121 | 0,01 | 0,938 |
| SchienenT*MatTemp | 1 | 0,30 | 0,305 | 0,02 | 0,902 |
| VWZeit*SchienenD | 1 | 4,84 | 4,840 | 0,25 | 0,624 |
| VWZeit*MatTemp | 1 | 0,90 | 0,899 | 0,05 | 0,832 |
| SchienenD*MatTemp | 1 | 0,16 | 0,160 | 0,01 | 0,929 |
| Fehler | 16 | 310,08 | 19,380 | ||
| Fehlende Anpassung | 10 | 308,20 | 30,820 | 98,51 | 0,000 |
| Reiner Fehler | 6 | 1,88 | 0,313 | ||
| Gesamt | 30 | 1447,60 |
Schritt 3: Bestimmen, wie gut das Modell an die Daten angepasst ist
Um zu ermitteln, wie gut das Modell an die Daten angepasst ist, untersuchen Sie die Statistiken für die Güte der Anpassung in der Tabelle „Zusammenfassung des Modells“.
- S
-
Verwenden Sie S, um zu ermitteln, wie genau das Modell die Antwortvariable beschreibt. Verwenden Sie S anstelle von R2, um die Anpassung von Modellen zu vergleichen.
S wird in der Maßeinheit der Antwortvariablen ausgedrückt und stellt die Streuung der Abstände der Datenwerte von der tatsächlichen Wirkungsfläche dar. Je niedriger der Wert von S, desto genauer beschreibt das Modell die Antwortvariable. Ein niedriger Wert von S allein bedeutet jedoch nicht zwangsläufig, dass das Modell die Modellannahmen erfüllt. Prüfen Sie die Annahmen anhand der Residuendiagramme.
- R-Qd
-
Je höher das R2, desto besser ist das Modell an die Daten angepasst. Das R2 liegt immer zwischen 0 % und 100 %.
Der Wert von R2 nimmt beim Einbinden zusätzlicher Prädiktoren in das Modell stets zu. Das beste Modell mit fünf Prädiktoren weist beispielsweise immer ein R2 auf, das mindestens so hoch wie das des besten Modells mit vier Prädiktoren ist. Daher ist R2 am nützlichsten, wenn Sie Modelle derselben Größe vergleichen.
- R-Qd(kor)
-
Verwenden Sie das korrigierte R2, wenn Sie Modelle vergleichen möchten, die eine unterschiedliche Anzahl von Prädiktoren enthalten. R2 nimmt stets zu, wenn Sie einen zusätzlichen Prädiktor in das Modell aufnehmen, selbst wenn damit keine tatsächliche Verbesserung des Modells verbunden ist. Der Wert des korrigierten R2 berücksichtigt die Anzahl der Prädiktoren im Modell, so dass Ihnen das Auswählen des richtigen Modells erleichtert wird.
- R-Qd(prog)
-
Verwenden Sie das prognostizierte R2, um zu ermitteln, wie genau das Modell Werte der Antwortvariablen für neue Beobachtungen prognostiziert. Modelle mit einem höheren prognostizierten R2 zeichnen sich durch eine bessere Prognosefähigkeit aus.
Ein prognostiziertes R2, das wesentlich kleiner als R2 ist, kann auf eine übermäßige Anpassung des Modells hinweisen. Ein übermäßig angepasstes Modell liegt vor, wenn Sie Terme für Effekte hinzufügen, die in der Grundgesamtheit unbedeutend sind. Das Modell wird somit an die Stichprobendaten angepasst und ist daher möglicherweise beim Aufstellen von Prognosen für die Grundgesamtheit nicht nützlich.
Das prognostizierte R2 kann zudem beim Vergleichen von Modellen nützlicher als das korrigierte R2 sein, da der Wert mit Beobachtungen berechnet wird, die in der Modellberechnung nicht enthalten sind.
- AICc und BIC
- Wenn Sie die Details für die einzelnen Schritte einer Methode der schrittweisen Regression oder die erweiterten Ergebnisse der Analyse anfordern, zeigt Minitab zwei weitere Statistiken an. Bei diesen Statistiken handelt es sich um Akaikes korrigiertes Informationskriterium (AICc) und das Bayessche Informationskriterium (BIC). Anhand dieser Statistiken können Sie verschiedene Modelle vergleichen. Bei jeder dieser Statistiken sind kleinere Werte erwünscht.
- Kleine Stichproben ermöglichen keinen genauen Schätzwert für die Stärke der Beziehung zwischen der Antwortvariablen und den Prädiktoren. Wenn z. B. das R2 genauer sein muss, sollten Sie einen größeren Stichprobenumfang (im Allgemeinen 40 oder mehr) wählen.
- Statistiken für die Güte der Anpassung sind nur eines der Maße für die Güte der Anpassung des Modells an die Daten. Selbst wenn ein Modell einen erwünschten Wert aufweist, sollten Sie die Residuendiagramme untersuchen, um sich zu vergewissern, dass das Modell die Modellannahmen erfüllt.
Zusammenfassung des Modells
| S | R-Qd | R-Qd(kor) | R-Qd(prog) |
|---|---|---|---|
| 4,40228 | 78,58% | 59,84% | 0,00% |
Wichtigste Ergebnisse: S, R-Qd, R-Qd(kor), R-Qd(prog)
In diesen Ergebnissen erklärt das Modell 78,58 % der Streuung in der Lichtausbeute. Das prognostizierte R2 von 0 % deutet jedoch darauf hin, dass das Modell übermäßig angepasst ist. Wenn weitere Modelle mit anderen Prädiktoren angepasst werden, verwenden Sie die Werte des korrigierten R2 und des prognostizierten R2, um die Güte der Anpassung der Modelle an die Daten zu vergleichen.
Schritt 4: Bestimmen, ob das Modell die Annahmen der Analyse erfüllt
Verwenden Sie die Residuendiagramme, um zu ermitteln, ob das Modell angemessen ist und die Annahmen der Analyse erfüllt. Wenn die Annahmen nicht erfüllt werden, ist das Modell u. U. nicht gut an die Daten angepasst, und Sie sollten beim Interpretieren der Ergebnisse vorsichtig sein.
Weitere Informationen zum Umgang mit Mustern in den Residuendiagrammen finden Sie unter Residuendiagramme für Faktoriellen Versuchsplan analysieren; klicken Sie dort auf den Namen des Residuendiagramms in der Liste am oberen Rand der Seite.
Diagramm der Residuen im Vergleich zu den Anpassungen
Die Muster in der folgenden Tabelle können darauf hinweisen, dass das Modell die Modellannahmen nicht erfüllt.| Muster | Mögliche Bedeutung des Musters |
|---|---|
| Aufgefächerte oder ungleichmäßig gestreute Residuen für die angepassten Werte | Nicht konstante Varianz |
| Krümmung | Ein fehlender Term höherer Ordnung |
| Ein weit von null entfernt liegender Punkt | Ein Ausreißer |
| Ein in x-Richtung weit von den anderen Punkten entfernter Punkt | Ein einflussreicher Punkt |
Verwenden Sie das Diagramm der Residuen im Vergleich zu den Anpassungen, um die Annahme zu überprüfen, dass die Residuen zufällig verteilt sind und eine konstante Varianz aufweisen. Im Idealfall sollten die Punkte zufällig auf beiden Seiten von null verteilt sein, und es sollten keine Muster in den Punkten erkennbar sein.
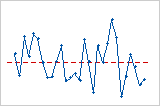
Diagramm der Residuen im Vergleich zur Reihenfolge
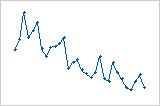
Trend
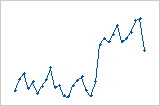
Shift
Zyklus
Wahrscheinlichkeitsnetz (Normal) für Residuen
Verwenden Sie das Wahrscheinlichkeitsnetz (Normal) der Residuen, um die Annahme zu überprüfen, dass die Residuen normalverteilt sind. Die Residuen im Wahrscheinlichkeitsnetz für Normalverteilung sollten ungefähr einer Geraden folgen.
Die Muster in der folgenden Tabelle können darauf hinweisen, dass das Modell die Modellannahmen nicht erfüllt.
| Muster | Mögliche Bedeutung des Musters |
|---|---|
| Keine Gerade | Nicht-Normalverteilung |
| Ein Punkt weit entfernt von der Linie | Ein Ausreißer |
| Sich verändernde Steigung | Eine nicht identifizierte Variable |