In diesem Thema
Summe der Quadrate (SS)
In Bezug auf Matrizen lauten die Formeln für die verschiedenen Summen der Quadrate wie folgt:

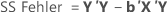
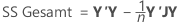
Minitab schlüsselt die Komponenten der Summe der Quadrate der Regression bzw. der Behandlungen in den Teil der Streuung auf, der durch die einzelnen Terme erklärt wird, wobei sowohl die sequenzielle Summe der Quadrate als auch die korrigierte Summe der Quadrate verwendet werden.
Notation
| Begriff | Beschreibung |
|---|---|
| b | Vektor von Koeffizienten |
| X | Designmatrix |
| Y | Vektor von Werten der Antwortvariablen |
| n | Anzahl der Beobachtungen |
| J | (n x n)-Matrix von 1s |
Sequenzielle Summe der Quadrate
Minitab schlüsselt die Varianzkomponenten der Summe der Quadrate der Regression bzw. der Behandlungen in sequenzielle Summen der Quadrate für die einzelnen Faktoren auf. Die sequenziellen Summen der Quadrate hängen von der Reihenfolge ab, in der die Faktoren bzw. Prädiktoren in das Modell aufgenommen wurden. Die sequenzielle Summe der Quadrate ist der eindeutige Anteil der Summe der Quadrate der Regression, der durch einen Faktor erklärt wird, nachdem alle zuvor aufgenommenen Faktoren erklärt wurden.
Wenn beispielsweise ein Modell mit den drei Faktoren bzw. Prädiktoren x1, x2 und x3 vorhanden ist, zeigt die sequenzielle Summe der Quadrate für x2, wie viel der verbleibenden Streuung durch x2 erklärt wird, nachdem x1 bereits in das Modell aufgenommen wurde. Wenn Sie eine andere Sequenz der Faktoren erhalten möchten, müssen Sie die Analyse wiederholen und dabei die Faktoren in einer anderen Reihenfolge aufnehmen.
Korrigierte Summe der Quadrate
Die korrigierte Summe der Quadrate hängt nicht von der Reihenfolge ab, in der die Terme in das Modell aufgenommen wurden. Die korrigierte Summe der Quadrate ist der Teil der Streuung, der durch einen Term erklärt wird, sofern alle anderen Terme im Modell enthalten sind, und zwar unabhängig von der Reihenfolge, in der die Terme in das Modell aufgenommen wurden.
Wenn beispielsweise ein Modell mit den drei Faktoren x1, x2 und x3 vorliegt, zeigt die korrigierte Summe der Quadrate für x2, wie viel der verbleibenden Streuung durch den Term für x2 erklärt wird, sofern die Terme für x1 und x3 bereits im Modell enthalten sind.
Die Berechnungen für die korrigierten Summen der Quadrate für drei Faktoren lauten wie folgt:
- SSR(x3 | x1, x2) = SSE (x1, x2) – SSE (x1, x2, x3) oder
- SSR(x3 | x1, x2) = SSR (x1, x2, x3) – SSR (x1, x2)
wobei SSR(x3 | x1, x2) die korrigierte Summe der Quadrate für x3 ist, sofern x1 und x2 im Modell enthalten sind.
- SSR(x2, x3 | x1) = SSE (x1) – SSE (x1, x2, x3) oder
- SSR(x2, x3 | x1) = SSR (x1, x2, x3) – SSR (x1)
wobei SSR(x2, x3 | x1) die korrigierte Summe der Quadrate für x2 und x3 ist, sofern x1 im Modell enthalten ist.
Sie können diese Formeln erweitern, wenn mehr als drei Faktoren im Modell vorhanden sind1.
- J. Neter, W. Wasserman und M. H. Kutner (1985). Applied Linear Statistical Models, Second Edition. Irwin, Inc.
Freiheitsgrade (DF)
Gibt die Anzahl der unabhängigen Einzelinformationen in Bezug auf die Daten der Antwortvariablen an, die zur Berechnung der Quadratsummen benötigt werden. Die Freiheitsgrade für jede Komponente des Modells werden wie folgt ausgedrückt:
| DF Regression | = p – 1 |
| DF Fehler | = n – p |
| Gesamt | = n – 1 |
Hierbei ist n = Anzahl der Beobachtungen und p = Anzahl der Terme im Modell.
Kor MS – Regression
Die Formel für das Mittel der Quadrate (MS) der Regression lautet wie folgt:
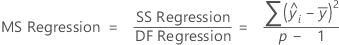
Notation
| Begriff | Beschreibung |
|---|---|
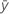 | Mittelwert der Antwortvariablen |
 | i-ter angepasster Wert der Antwortvariablen |
| p | Anzahl der Terme im Modell |
Kor MS – Fehler
Das mittlere Fehlerquadrat (das auch als MS Fehler oder MSE abgekürzt und als s2 angegeben wird) ist die Varianz um die angepasste Regressionslinie. Die Formel lautet:

Notation
| Begriff | Beschreibung |
|---|---|
| yi | i-ter beobachteter Wert der Antwortvariablen |
 | i-ter angepasster Wert der Antwortvariablen |
| n | Anzahl der Beobachtungen |
| p | Anzahl der Koeffizienten im Modell |
F
Wenn alle Faktoren im Modell fest sind, hängt die Berechnung der F-Statistik wie folgt vom Gegenstand des Hypothesentests ab:
- F(Term)
-

- F(fehlende Anpassung)
-

Wenn Zufallsfaktoren im Modell enthalten sind, wird F mit dem erwarteten Mittel der Quadrate für jeden Term bestimmt. Weitere Informationen finden Sie in Neter et al.1.
Notation
| Begriff | Beschreibung |
|---|---|
| Kor MS Term | Ein Maß der Streuung, die durch einen Term erklärt wird, nachdem die anderen Terme im Modell berücksichtigt wurden. |
| MS Fehler | Ein Maß der Streuung, die durch das Modell nicht erklärt wird. |
| MS Fehlende Anpassung | Ein Maß der Streuung in der Antwortvariablen, die durch Hinzufügen weiterer Terme zum Modell modelliert werden könnte. |
| MS Reiner Fehler | Ein Maß der Streuung in replizierten Antwortdaten. |
- J. Neter, W. Wasserman und M. H. Kutner (1985). Applied Linear Statistical Models, Second Edition. Irwin, Inc.
p-Wert – Tabelle der Varianzanalyse
Der p-Wert ist ein Wahrscheinlichkeitsmaß, das aus einer F-Verteilung mit den Freiheitsgraden (DF) wie folgt berechnet wird:
- DF des Zählers
- Summe der Freiheitsgrade für den Term oder die Terme im Test
- DF des Nenners
- Freiheitsgrade für Fehler
Formel
1 − P(F ≤ fj)
Notation
| Begriff | Beschreibung |
|---|---|
| P(F ≤ f) | kumulative Verteilungsfunktion für die F-Verteilung |
| f | F-Statistik für den Test |