Exponentialfamilie und Linkfunktionen
Die Erweiterung der klassischen linearen Modelle auf verallgemeinerte lineare Modelle umfasst zwei Teile: eine Verteilung aus der Exponentialfamilie und eine Linkfunktion.
Exponentialfamilie
Der erste Teil erweitert das lineare Modell auf Antwortvariablen, die zu einer großen Familie von Verteilungen gehören, die als Exponentialfamilie bezeichnet werden. Mitglieder der Exponentialfamilie von Verteilungen weisen Dichtefunktionen für einen beobachteten Wert der Antwortvariablen in dieser allgemeinen Form auf:
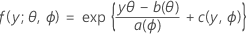
Hierbei gilt: a(∙), b(∙) und c(∙) hängen von der Verteilung der Antwortvariablen ab. Der Parameter θ ist ein Lageparameter, der oft als kanonischer Parameter bezeichnet wird, und ϕ wird als Streuungsparameter bezeichnet. Die Funktion a(ϕ) hat meistens die Form a(ϕ) = ϕ/ ω, wobei ω eine bekannte Konstante oder Gewichtung ist, die zwischen den Beobachtungen variieren kann. (Wenn in Minitab Gewichtungen angegeben werden, wird die Funktion a(ϕ) entsprechend korrigiert.)
Bei Mitgliedern der Exponentialfamilie kann es sich um diskrete Verteilungen oder stetige Verteilungen handeln. Beispiele für stetige Verteilungen, die zur Exponentialfamilie gehören, sind die Normalverteilung und die Gamma-Verteilung. Zu den diskreten Verteilungen, die zur Exponentialfamilie gehören, zählen zum Beispiel die Binomialverteilung und die Poisson-Verteilung. In der folgenden Tabelle werden die Merkmale einiger dieser Verteilungen aufgeführt.
| Verteilung | ϕ | b(θ) | a(φ) | c(y, ϕ) |
| Normal | σ2 | θ2/2 | φω |  |
| Binomial | 1 | 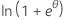 |
φ/ω | -ln(y!) |
| Poisson | 1 | exp(θ) | φ/ω |  |
Linkfunktion
Der zweite Teil ist die Linkfunktion. Die Linkfunktion setzt den Mittelwert der Antwortvariablen in der i-ten Beobachtung in folgender Form zu einem linearen Prädiktor in Beziehung:
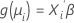
Das klassische lineare Modell ist ein Sonderfall dieser allgemeinen Formel, wobei die Linkfunktion die Identitätsfunktion ist.
Die Auswahl der Linkfunktion im zweiten Teil hängt von der spezifischen Verteilung der Exponentialfamilie im ersten Teil ab. Jede Verteilung in der Exponentialfamilie weist eine bestimmte Linkfunktion auf, die als kanonische Linkfunktion bezeichnet wird. Diese Linkfunktion erfüllt die Gleichung g (μi) = Xi'β = θ, wobei θ der kanonische Parameter ist. Die kanonische Linkfunktion ergibt einige erwünschte statistische Eigenschaften des Modells. Mit Hilfe der Statistiken für die Güte der Anpassung können Sie die Anpassungen mit den verschiedenen Linkfunktionen vergleichen. Bestimmte Linkfunktionen können aus historischen Gründen verwendet werden, oder weil sie eine bestimmte Bedeutung in einer Disziplin haben. Beispielsweise besteht ein Vorteil der Logit-Linkfunktion darin, dass sie einen Schätzwert für das Chancenverhältnis liefert. Ein weiteres Beispiel ist die Normit-Linkfunktion: Bei dieser wird angenommen, dass eine zugrunde liegende Variable vorhanden ist, die einer Normalverteilung folgt und in binäre Kategorien unterteilt ist.
Minitab bietet drei Linkfunktionen. Mit Hilfe der verschiedenen Linkfunktionen können Sie Modelle bestimmen, die bei unterschiedlich ausgeprägten Daten eine adäquate Anpassung bieten. Die folgenden Linkfunktionen sind verfügbar: Logit, Normit (auch als Probit bezeichnet) und Gompit (auch als komplementärer Log-Log bezeichnet). Hierbei handelt es sich um die Umkehrung der regulären kumulativen logistischen Verteilungsfunktion (Logit), die Umkehrung der regulären kumulativen Normalverteilungsfunktion (Normit) und die Umkehrung der Gompertz-Verteilungsfunktion (Gompit). Die Logit-Linkfunktion ist die kanonische Linkfunktion für Binomialmodelle, und somit ist Logit die standardmäßig vorgegebene Linkfunktion.
| Modell | Name | Linkfunktion, g(μi) |
| Binomial | Logit | 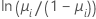 |
| Binomial | Normit (Probit) | 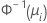 |
| Binomial | Gompit (komplementärer Log-Log) |  |
Notation
| Begriff | Beschreibung |
|---|---|
| μi | Mittelwert der Antwortvariablen in der i-ten Zeile |
| g(μi) | Linkfunktion |
| X | Vektor der Prädiktorvariablen |
| β | Vektor der Koeffizienten, die den Prädiktoren zugeordnet sind |
 | inverse kumulative Verteilungsfunktion der Normalverteilung |
Faktoren-/Kovariatenmuster
Beschreibt einen einzelnen Satz von Faktoren-/Kovariatenwerten in einem Datensatz. Minitab berechnet für jedes Faktoren-/Kovariatenmuster Ereigniswahrscheinlichkeiten, Residuen und weitere Bewertungsmaße.
Wenn ein Datensatz beispielsweise die Faktoren Geschlecht und Ethnie sowie die Kovariate Alter enthält, können die Kombinationen dieser Prädiktoren so viele verschiedene Kovariatenmuster wie Probanden enthalten. Wenn ein Datensatz nur die Faktoren Ethnie und Geschlecht enthält, die jeweils auf zwei Stufen kodiert sind, gibt es nur vier mögliche Faktoren-/Kovariatenmuster. Wenn Sie die Daten als Häufigkeiten oder als Erfolge, Versuche oder Misserfolge eingeben, enthält jede Zeile ein Faktoren-/Kovariatenmuster.
Versuchsplanmatrix
Minitab verfolgt für die Versuchsplanmatrix denselben Ansatz wie im allgemeinen linearen Modell (GLM), bei dem das angegebene Modell mit einer Regression angepasst wird. Zunächst erstellt Minitab auf der Grundlage der Faktoren und des angegebenen Modells eine Versuchsplanmatrix. Die Spalten dieser Matrix (mit X bezeichnet) stellen die Terme im Modell dar.
- Konstante
- Kovariaten
- Blöcke
- Faktoren
- Wechselwirkungen
- Konstante
- Kovariate
- Stetiger Faktor
Für Blöcke ist die Anzahl der Spalten gleich eins weniger als die Anzahl der Blöcke.
Kategoriale Faktoren und Wechselwirkungen in zweistufigen Versuchsplänen
In einem zweistufigen Versuchsplan weist der Term für einen kategorialen Faktor eine Spalte auf. Jeder Wechselwirkungsterm weist ebenfalls eine Spalte auf.
Kategoriale Faktoren in allgemeinen faktoriellen Versuchsplänen
| Stufe von A | A1 | A2 | A3 |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
| 4 | -1 | -1 | -1 |
Wechselwirkungen in allgemeinen faktoriellen Versuchsplänen
Um die Spalten für einen Wechselwirkungsterm zu berechnen, werden die entsprechenden Spalten für die Faktoren in der Wechselwirkung multipliziert. Angenommen, Faktor A weist sechs Stufen, Faktor C drei Stufen und Faktor D vier Stufen auf. Der Term A * C * D weist dann 5 x 2 x 3 = 30 Spalten auf. Um die Stufen zu erhalten, wird jede Spalte für A mit jeder für C und jeder für D multipliziert.
Haupteinheitenspalten in Split-Plot-Designs
Hinweis
Minitab analysiert keine Split-Plot-Designs mit einer binären Antwortvariablen.
Für ein Split-Plot-Design verwendet Minitab zwei Versionen der Versuchsplanmatrix. Eine Version ist dieselbe Matrix, die auch für zweistufige faktorielle Versuchspläne verwendet wird. Die andere Matrix enthält einen Block von Spalten, die Haupteinheiten darstellen. Bei der Berechnung des Haupteinheiten-Fehlerterms wird beispielsweise diese zweite Version der Versuchsplanmatrix verwendet. Die Spalten für die Haupteinheiten folgen den Spalten für die schwer veränderbaren Faktoren und Wechselwirkungen, die ausschließlich schwer veränderbare Faktoren umfassen.