In diesem Thema
Varianzanalyse

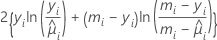
Die Abweichungstabelle wird auf der Grundlage des folgenden allgemeinen Ergebnisses erstellt, bei dem angenommen wird, dass ϕ bekannt ist. Wenn DI die einem Anfangsmodell zugeordnete Abweichung und DS die einer Teilmenge von Termen im Anfangsmodell zugeordnete Abweichung ist, liegt unter einigen Regularitätsbedingungen die folgende Beziehung vor:

Die Differenz zwischen den Abweichungen ist asymptotisch als Chi-Quadrat-Verteilung mit d Freiheitsgraden verteilt. Diese Statistiken werden für die korrigierte Analyse (Typ III) und die sequenzielle Analyse (Typ I) berechnet. Die korrigierte Abweichung und die Chi-Quadrat-Statistik in der Abweichungstabelle sind gleich. Die korrigierte mittlere Abweichung ist die korrigierte Abweichung dividiert durch die Freiheitsgrade.
Bei der sequenziellen Analyse hängt das Ergebnis von der Reihenfolge ab, in der die Prädiktoren in das Modell eingegeben werden. Die sequenzielle Abweichung ist der eindeutige Teil der Abweichung, der durch einen Prädiktor erklärt wird, wenn bereits Prädiktoren im Modell vorhanden sind. Bei einem Modell mit den drei Prädiktoren X1, X2 und X3 zeigt die sequenzielle Abweichung für X3, wie viel der verbleibenden Abweichung durch X3 erklärt wird, wenn X1 und X2 bereits im Modell enthalten sind. Um eine andere sequenzielle Abweichung zu erhalten, wiederholen Sie das Regressionsverfahren, und geben Sie die Prädiktoren in einer anderen Reihenfolge ein.
Wenn ϕ unbekannt ist, zum Beispiel bei Antwortvariablen, die einer Normalverteilung folgen, ändert sich die Beziehung unter einigen Regularitätsbedingungen wie folgt:
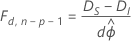
Hier ist die Differenz zwischen den Abweichungen asymptotisch als F-Verteilung mit d Freiheitsgraden für den Zähler und n − p Freiheitsgraden für den Nenner verteilt. Um den Streuungsparameter zu schätzen, verwenden Sie das Anfangsmodell.
Notation
| Begriff | Beschreibung |
|---|---|
| yi | Anzahl der Ereignisse für die i-te Zeile |
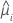 | geschätzter Mittelwert der Antwortvariablen für die i-te Zeile |
| mi | Anzahl der Versuche für die i-te Zeile |
| Lf | Log-Likelihood des vollständigen Modells |
| Lc | Log-Likelihood des Modells mit einer Teilmenge von Termen aus dem vollständigen Modell |
| d | Freiheitsgrade; die Differenz zwischen der Anzahl der Parameter in den zu vergleichenden Modellen |
| ϕ | Streuungsparameter, der für das Modell mit Binomialverteilung als 1 bekannt ist |
| n | Anzahl der Zeilen in den Daten |
| p | Freiheitsgrade der Regression für das Anfangsmodell |
Freiheitsgrade (DF)
| Streuungsquelle | DF |
| Modell | p |
| Fehler | n − p − 1 |
| Gesamt | n − 1 |
| Stetige Prädiktoren | 1 |
| Kategoriale Prädiktoren | q − 1 |
| Blöcke | b − 1 |

Hinweis
Für zweistufige Versuchspläne mit Zentralpunkten beträgt der Freiheitsgrad für die Krümmung 1.
Notation
| Begriff | Beschreibung |
|---|---|
| p | Summe der Freiheitsgrade für die Prädiktoren. Die Prädiktoren umfassen nicht die Konstante. |
| n | Anzahl der Zeilen im Versuchsplan |
| q | Anzahl der Stufen des kategorialen Prädiktors |
| b | Anzahl der Blöcke |
| a | Anzahl der Stufen im Faktor A |
| b | Anzahl der Stufen im Faktor B |
Log-Likelihood
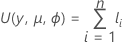
Die allgemeine Form der einzelnen Beiträge lautet:

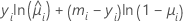
Notation
| Begriff | Beschreibung |
|---|---|
| yi | Anzahl der Ereignisse für die i-te Zeile |
| mi | Anzahl der Versuche für die i-te Zeile |
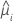 | geschätzter Mittelwert der Antwortvariablen für die i-te Zeile |
p-Wert (p)
p-Werte werden in Hypothesentests verwendet, um Ihnen die Entscheidung zu ermöglichen, ob eine Nullhypothese zurückgewiesen oder nicht zurückgewiesen werden sollte. Der p-Wert stellt die Wahrscheinlichkeit dar, eine Teststatistik zu erhalten, die mindestens so extrem wie der tatsächlich berechnete Wert ist, wenn die Nullhypothese wahr ist. Ein häufig verwendeter Trennwert für den p-Wert ist 0,05. Wenn beispielsweise der berechnete p-Wert einer Teststatistik kleiner als 0,05 ist, weisen Sie die Nullhypothese zurück.