In diesem Thema
- Schritt 1: Ermitteln, welche Terme den größten Effekt auf die Antwortvariable haben
- Schritt 2: Bestimmen, welche Terme statistisch signifikante Effekte auf die Antwortvariable haben
- Schritt 3: Verstehen der Effekte der Prädiktoren
- Schritt 4: Bestimmen, wie gut das Modell an die Daten angepasst ist
- Schritt 5: Bestimmen, ob das Modell nicht an Ihre Daten angepasst ist
Schritt 1: Ermitteln, welche Terme den größten Effekt auf die Antwortvariable haben
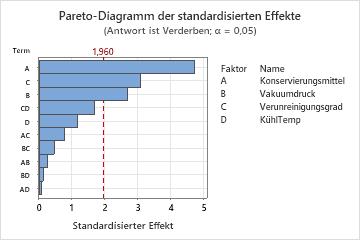
Verwenden Sie ein Pareto-Diagramm der standardisierten Effekte, um die relative Größe und die statistische Signifikanz von Haupteffekten und Wechselwirkungseffekten zu vergleichen.
Minitab stellt die standardisierten Effekte in absteigender Reihenfolge ihrer Absolutwerte dar. Die Referenzlinie im Diagramm zeigt, welche Effekte signifikant sind. In der Standardeinstellung zeichnet Minitab die Referenzlinie bei einem Signifikanzniveau von 0,05.
Wichtigste Ergebnisse: Pareto-Diagramm
In diesen Ergebnissen sind die drei Haupteffekte statistisch signifikant (α = 0,05) – Art des Konservierungsmittels (A), Vakuumversiegelungsdruck (B) und Grad der Verunreinigung (C).
Darüber hinaus können Sie feststellen, dass die Art des Konservierungsmittels (A) den größten Effekt hat, da er sich am weitesten erstreckt. Der Effekt der Wechselwirkung zwischen Konservierungsmittel und Kühltemperatur (AD) ist am geringsten, da er sich am kürzesten erstreckt.
Schritt 2: Bestimmen, welche Terme statistisch signifikante Effekte auf die Antwortvariable haben
- p-Wert ≤ α: Die Assoziation ist statistisch signifikant
- Wenn der p-Wert kleiner oder gleich dem Signifikanzniveau ist, können Sie schlussfolgern, dass eine statistisch signifikante Assoziation zwischen der Antwortvariablen und dem Term besteht.
- p-Wert > α: Die Assoziation ist statistisch nicht signifikant
- Wenn der p-Wert größer als das Signifikanzniveau ist, können Sie nicht schlussfolgern, dass eine statistisch signifikante Assoziation zwischen der Antwortvariablen und dem Term besteht. Es empfiehlt sich möglicherweise, das Modell ohne den Term erneut anzupassen.
- Wenn ein Koeffizient für einen Faktor signifikant ist, können Sie schlussfolgern, dass die Wahrscheinlichkeit des Ereignisses nicht für alle Stufen des Faktors gleich ist.
- Wenn ein Koeffizient für eine Kovariate signifikant ist, besteht eine Assoziation zwischen Änderungen des Werts der Variablen und Änderungen der Wahrscheinlichkeit.
- Wenn ein Koeffizient für einen Wechselwirkungsterm signifikant ist, hängt die Beziehung zwischen einem Faktor und der Antwortvariablen von den anderen Faktoren im Term ab. In diesem Fall sollten Sie die Haupteffekte nicht interpretieren, ohne dabei den Wechselwirkungseffekt zu berücksichtigen.
- Wenn der Koeffizient für einen Block statistisch signifikant ist, können Sie schlussfolgern, dass sich die Linkfunktion für den Block vom Durchschnittswert unterscheidet.
Kodierte Koeffizienten
| Term | Effekt | Koef | SE Koef | VIF |
|---|---|---|---|---|
| Konstante | -2,7370 | 0,0479 | ||
| Konservierungsmittel | 0,4497 | 0,2249 | 0,0477 | 1,03 |
| Vakuumdruck | 0,2574 | 0,1287 | 0,0477 | 1,06 |
| Verunreinigungsgrad | 0,2954 | 0,1477 | 0,0478 | 1,06 |
| KühlTemp | -0,1107 | -0,0554 | 0,0478 | 1,07 |
| Konservierungsmittel*Vakuumdruck | -0,0233 | -0,0117 | 0,0473 | 1,05 |
| Konservierungsmittel*Verunreinigungsgrad | 0,0722 | 0,0361 | 0,0474 | 1,06 |
| Konservierungsmittel*KühlTemp | 0,0067 | 0,0034 | 0,0472 | 1,05 |
| Vakuumdruck*Verunreinigungsgrad | -0,0430 | -0,0215 | 0,0469 | 1,04 |
| Vakuumdruck*KühlTemp | -0,0115 | -0,0058 | 0,0465 | 1,02 |
| Verunreinigungsgrad*KühlTemp | 0,1573 | 0,0786 | 0,0467 | 1,02 |
Wichtigstes Ergebnis: Koeffizienten
In diesen Ergebnissen sind die Koeffizienten für die Haupteffekte von Konservierungsmittel, Vakuumdruck und Verunreinigungsgrad positive Zahlen. Der Koeffizient des Haupteffekts von KühlTemp ist eine negative Zahl. Im Allgemeinen gilt bei einem zunehmenden Wert des Terms: Positive Koeffizienten steigern die Wahrscheinlichkeit des Ereignisses, während negative Koeffizienten die Wahrscheinlichkeit des Ereignisses verringern.
Varianzanalyse
| Quelle | DF | Kor Abw | Kor MW | Chi-Quadrat | p-Wert |
|---|---|---|---|---|---|
| Modell | 10 | 46,2130 | 4,6213 | 46,21 | 0,000 |
| Konservierungsmittel | 1 | 22,6835 | 22,6835 | 22,68 | 0,000 |
| Vakuumdruck | 1 | 7,3313 | 7,3313 | 7,33 | 0,007 |
| Verunreinigungsgrad | 1 | 9,6209 | 9,6209 | 9,62 | 0,002 |
| KühlTemp | 1 | 1,3441 | 1,3441 | 1,34 | 0,246 |
| Konservierungsmittel*Vakuumdruck | 1 | 0,0608 | 0,0608 | 0,06 | 0,805 |
| Konservierungsmittel*Verunreinigungsgrad | 1 | 0,5780 | 0,5780 | 0,58 | 0,447 |
| Konservierungsmittel*KühlTemp | 1 | 0,0051 | 0,0051 | 0,01 | 0,943 |
| Vakuumdruck*Verunreinigungsgrad | 1 | 0,2106 | 0,2106 | 0,21 | 0,646 |
| Vakuumdruck*KühlTemp | 1 | 0,0153 | 0,0153 | 0,02 | 0,902 |
| Verunreinigungsgrad*KühlTemp | 1 | 2,8475 | 2,8475 | 2,85 | 0,092 |
| Fehler | 5 | 0,9674 | 0,1935 | ||
| Gesamt | 15 | 47,1804 |
Wichtigstes Ergebnis: p-Wert
In diesen Ergebnissen sind die Haupteffekte für Konservierungsmittel, Vakuumdruck und Verunreinigungsgrad bei einem Signifikanzniveau von 0,05 statistisch signifikant. Sie können schlussfolgern, dass zwischen Änderungen dieser Variablen und Änderungen der Antwortvariablen eine Assoziation besteht.
Die Wechselwirkungsterme sind statistisch nicht signifikant. Die Beziehung zwischen den einzelnen Variablen und der Antwortvariablen hängen möglicherweise nicht vom Wert der jeweils anderen Variablen ab.
Schritt 3: Verstehen der Effekte der Prädiktoren
- Chancenverhältnisse für stetige Prädiktoren
-
Chancenverhältnisse größer als 1 weisen darauf hin, dass das Ereignis mit umso größerer Wahrscheinlichkeit eintritt, je größer der Prädiktor ist. Chancenverhältnisse kleiner als 1 weisen darauf hin, dass das Ereignis mit umso geringerer Wahrscheinlichkeit eintritt, je größer der Prädiktor ist.
Chancenverhältnisse für stetige Prädiktoren
Änderungseinheit Chancenverhältnis 95%-KI Dosis (mg) 0,5 6,1279 (1,7218; 21,8087) Wichtigstes Ergebnis: Chancenverhältnis
In diesen Ergebnissen wird mit dem Modell anhand der Dosierung eines Medikaments das Vorhandensein bzw. Nichtvorhandensein von Bakterien bei erwachsenen Patienten prognostiziert. In diesem Beispiel stellt das Nichtvorhandensein von Bakterien das Ereignis dar. Jede Tablette enthält eine Dosierung von 0,5 mg, so dass die Forscher die Einheit für eine Änderung auf 0,5 mg festlegen. Das Chancenverhältnis beläuft sich auf etwa 6. Bei jeder weiteren Tablette, die einem Patienten verabreicht wird, steigt die Chance, dass die Bakterien beim Patienten nicht festzustellen sind, um das etwa Sechsfache.
- Chancenverhältnisse für kategoriale Prädiktoren
-
Bei kategorialen Prädiktoren ist das Chancenverhältnis ein Vergleich der Chancen für das Eintreten des Ereignisses auf zwei verschiedenen Stufen des Prädiktors. In Minitab wird der Vergleich durch Auflisten der Stufen in zwei Spalten eingerichtet: Stufe A und Stufe B. Stufe B stellt die Referenzstufe für den Faktor dar. Chancenverhältnisse größer als 1 weisen darauf hin, dass das Ereignis auf Stufe A wahrscheinlicher ist. Chancenverhältnisse kleiner als 1 weisen darauf hin, dass das Ereignis auf Stufe A weniger wahrscheinlich ist. Weitere Informationen zur Kodierung von kategorialen Prädiktoren finden Sie unter Kodierungsschemas für kategoriale Prädiktoren.
Chancenverhältnisse für kategoriale Prädiktoren
Stufe A Stufe B Chancenverhältnis 95%-KI Monat 2 1 1,1250 (0,0600; 21,0834) 3 1 3,3750 (0,2897; 39,3165) 4 1 7,7143 (0,7461; 79,7592) 5 1 2,2500 (0,1107; 45,7172) 6 1 6,0000 (0,5322; 67,6397) 3 2 3,0000 (0,2547; 35,3325) 4 2 6,8571 (0,6556; 71,7169) 5 2 2,0000 (0,0976; 41,0019) 6 2 5,3333 (0,4679; 60,7946) 4 3 2,2857 (0,4103; 12,7323) 5 3 0,6667 (0,0514; 8,6389) 6 3 1,7778 (0,2842; 11,1200) 5 4 0,2917 (0,0252; 3,3719) 6 4 0,7778 (0,1464; 4,1326) 6 5 2,6667 (0,2124; 33,4861) Wichtigstes Ergebnis: Chancenverhältnis
In diesen Ergebnissen ist der kategoriale Prädiktor der Monat ab dem Beginn der Hochsaison eines Hotels. Die Antwortvariable gibt an, ob ein Gast eine Reservierung storniert oder nicht. In diesem Beispiel stellt die Stornierung das Ereignis dar. Das größte Chancenverhältnis beträgt etwa 7,71, wenn Stufe A gleich Monat 4 und Stufe B gleich Monat 1 ist. Das bedeutet, dass die Chance, dass ein Gast seine Reservierung storniert, in Monat 4 annähernd 8 Mal größer als in Monat 1 ist.
Schritt 4: Bestimmen, wie gut das Modell an die Daten angepasst ist
Hinweis
Viele Statistiken zur Übersicht des Modells und zur Güte der Anpassung werden davon beeinflusst, wie die Daten im Arbeitsblatt angeordnet sind und ob jede Zeile einen oder mehrere Versuche enthält. Der Hosmer-Lemeshow-Test wird durch die Anordnung der Daten nicht beeinflusst und liefert bei einem Versuch pro Zeile ähnliche Ergebnisse wie bei mehreren Versuchen pro Zeile. Weitere Informationen finden Sie unter Wie wirken sich Datenformate bei der binären logistischen Regression auf die Güte der Anpassung aus?.
- R-Qd der Abweichung
-
Je höher das R2 der Abweichung ausfällt, desto besser ist das Modell an die Daten angepasst. Das R2 der Abweichung liegt immer zwischen 0 % und 100 %.
Das R2 der Abweichung nimmt beim Einbinden zusätzlicher Terme in ein Modell stets zu. Das beste Modell mit fünf Termen weist beispielsweise immer ein R2 auf, das mindestens so hoch wie das des besten Modells mit vier Termen ist. Daher ist das R2 der Abweichung am nützlichsten, wenn Sie Modelle derselben Größe vergleichen.
Die Anordnung der Daten beeinflusst den Wert des R2 der Abweichung. Das R2 der Abweichung ist bei Daten mit mehreren Versuchen pro Zeile in der Regel höher als bei Daten mit nur einem Versuch pro Zeile. Die Werte des R2 der Abweichung sind nur bei Modellen vergleichbar, in denen dasselbe Datenformat verwendet wird.
Statistiken für die Güte der Anpassung sind nur eines der Maße für die Güte der Anpassung des Modells an die Daten. Selbst wenn ein Modell einen erwünschten Wert aufweist, sollten Sie die Residuendiagramme und die Tests auf Güte der Anpassung untersuchen, um zu beurteilen, wie gut das Modell an die Daten angepasst ist.
- R-Qd(kor) der Abweichung
-
Verwenden Sie das korrigierte R2 der Abweichung, wenn Sie Modelle vergleichen möchten, die eine unterschiedliche Anzahl von Termen enthalten. Das R2 der Abweichung nimmt beim Einbinden eines Terms in ein Modell stets zu. Das korrigierte R2 der Abweichung berücksichtigt die Anzahl der Terme im Modell, was die Auswahl des richtigen Modells erleichtert.
- AIC, AICc und BIC
-
Anhand des AIC, des AICc und des BIC können Sie verschiedene Modelle vergleichen. Bei jeder dieser Statistiken sind kleinere Werte erwünscht. Das Modell mit dem kleinsten Wert für eine Gruppe von Prädiktoren ist jedoch nicht zwangsläufig gut an die Daten angepasst. Verwenden Sie daher auch die Tests auf die Güte der Anpassung und die Residuendiagramme, um zu beurteilen, wie gut ein Modell an die Daten angepasst ist.
Zusammenfassung des Modells
| R-Qd der Abweichung | R-Qd(kor) der Abweichung | AIC | AICc | BIC |
|---|---|---|---|---|
| 97,95% | 76,75% | 105,98 | 171,98 | 114,48 |
Wichtigste Ergebnisse: R-Qd der Abweichung, R-Qd(kor) der Abweichung, AIC
In diesen Ergebnissen erklärt das Modell 97,95 % der Gesamtabweichung in der Antwortvariablen. Für diese Daten gibt das R2 der Abweichung an, dass das Modell gut an die Daten angepasst ist. Wenn Sie weitere Modelle mit anderen Prädiktoren anpassen, verwenden Sie das korrigierte R2 der Abweichung sowie das AIC, das AICc und das BIC, um zu vergleichen, wie gut die Modelle an die Daten angepasst sind.
Schritt 5: Bestimmen, ob das Modell nicht an Ihre Daten angepasst ist
- Falsche Linkfunktion
- Fehlender Term höherer Ordnung für Variablen im Modell
- Fehlender Prädiktor, der nicht im Modell enthalten ist
- Überdispersion
Wenn die Abweichung statistisch signifikant ist, können Sie eine andere Linkfunktion verwenden oder die Terme im Modell ändern.
- Abweichung: Der p-Wert für den Abweichungstest ist für Daten mit einem Versuch pro Zeile tendenziell kleiner als für Daten mit mehreren Versuchen pro Zeile und nimmt generell mit der Anzahl der Versuche pro Zeile ab. Für Daten mit einem Versuch pro Zeile sind die Ergebnisse des Hosmer-Lemeshow-Tests zuverlässiger.
- Pearson: Die vom Pearson-Test verwendete Approximation an die Chi-Quadrat-Verteilung ist ungenau, wenn die erwartete Anzahl von Ereignissen pro Zeile in den Daten klein ist. Daher ist der Test auf Güte der Anpassung nach Pearson ungenau, wenn die Daten im Format mit einem Versuch pro Zeile vorliegen.
- Hosmer-Lemeshow: Der Hosmer-Lemeshow-Test hängt nicht wie die anderen Tests auf Güte der Anpassung von der Anzahl der Versuche pro Zeile in den Daten ab.Wenn die Daten nur wenige Versuche pro Zeile aufweisen, ist der Hosmer-Lemeshow-Test ein zuverlässigerer Indikator dafür, wie gut das Modell an die Daten angepasst ist.
Informationen zur Antwortvariablen
| Variable | Wert | Anzahl | Ereignisbezeichnung |
|---|---|---|---|
| Verderben | Ereignis | 506 | Event |
| Nicht-Ereignis | 7482 | ||
| Gebinde | Gesamt | 7988 |
Tests auf Güte der Anpassung
| Test | DF | Chi-Quadrat | p-Wert |
|---|---|---|---|
| Abweichung | 5 | 0,97 | 0,965 |
| Pearson | 5 | 0,97 | 0,965 |
| Hosmer-Lemeshow | 6 | 0,10 | 1,000 |
Wichtigste Ergebnisse für das Ereignis-/Versuchsformat: Informationen zur Antwortvariablen, Abweichungstest, Pearson-Test, Hosmer-Lemeshow-Test
In diesen Ergebnisse weisen alle Tests auf Güte der Anpassung p-Werte auf, die über dem üblichen Signifikanzniveau 0,05 liegen. Die Tests liefern keine Anzeichen dafür, dass die prognostizierten Wahrscheinlichkeiten auf eine Weise von den beobachteten Wahrscheinlichkeiten abweichen, die mit der Binomialverteilung nicht prognostiziert wird.