In diesem Thema
Schätzmethode
Sie können entweder Eingeschränkte Maximum-Likelihood (REML) oder Maximum-Likelihood (ML) auswählen. Im Allgemeinen verwenden Sie Eingeschränkte Maximum-Likelihood (REML), da der Schätzwert der Varianzkomponenten durch REML annähernd erwartungstreu ist, der ML-Schätzwert hingegen ist verzerrt. Die systematische Messabweichung nimmt jedoch bei größeren Stichprobenumfängen ab.
Verwenden Sie Maximum-Likelihood (ML), wenn Sie prüfen müssen, ob ein geschachteltes Modell mit einer geringeren Anzahl von Termen mit festen Effekten ebenso gut wie das entsprechende Referenzmodell ist, das mehr Terme mit festen Effekten enthält, wobei beide Modelle die gleiche Anzahl von Zufallstermen und die gleiche Fehlervarianzstruktur aufweisen. Insbesondere sei  die -2 Log-Likelihood aus dem vollständigen Modell und
die -2 Log-Likelihood aus dem vollständigen Modell und  die -2 Log-Likelihood aus dem kleineren Modell.
die -2 Log-Likelihood aus dem kleineren Modell.
Gemäß der Nullhypothese kann asymptotisch 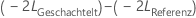 auf eine Chi-Quadrat-Verteilung geschlossen werden, deren Freiheitsgrade der Differenz hinsichtlich der Anzahl der Parameter für Terme mit festen Effekten zwischen dem Referenzmodell und dem geschachtelten Modell entsprechen. Sie können mit dem Likelihood-Quotienten-Test bewerten, ob eine Teilmenge von Termen mit festen Effekten aus dem Referenzmodell entfernt werden kann.
auf eine Chi-Quadrat-Verteilung geschlossen werden, deren Freiheitsgrade der Differenz hinsichtlich der Anzahl der Parameter für Terme mit festen Effekten zwischen dem Referenzmodell und dem geschachtelten Modell entsprechen. Sie können mit dem Likelihood-Quotienten-Test bewerten, ob eine Teilmenge von Termen mit festen Effekten aus dem Referenzmodell entfernt werden kann.
Weitere Informationen zum Likelihood-Quotienten-Test für feste Parameter in einem Modell mit gemischten Effekten finden Sie in B. T. West, K. B. Welch und A. T. Gałecki (2007). Linear Mixed Models: A Practical Guide Using Statistical Software, First Edition. Chapman and Hall/CRC (S. 34-36).
Testmethode für feste Effekte
Im Allgemeinen verwenden Sie Kenward-Roger-Approximation, da die Berechnungen eine Korrektur einschließen, mit der die systematische Messabweichung aufgrund kleiner Stichprobenumfänge verringert wird. Sie können auch Satterthwaite-Approximation verwenden. Generell gilt Folgendes: Je größer der Stichprobenumfang, desto kleiner die Differenz zwischen den beiden Methoden.
Gewichtungen
Geben Sie im Feld Gewichtungen eine numerische Spalte mit Gewichtungen für alle Werte der Antwortvariablen ein. Verwenden Sie Gewichtungen, wenn die Varianz des Zufallsfehlers innerhalb der Werte der Antwortvariablen nicht konstant ist. Stattdessen ist die Varianz für jeden Wert der Antwortvariablen gleich der Umkehrung der entsprechenden Gewichtung, multipliziert mit einer Konstanten.
Die Gewichtungen müssen größer oder gleich null sein. Die Spalte mit den Gewichtungen muss dieselbe Anzahl von Zeilen wie die Spalte mit der Antwortvariablen aufweisen.
Konfidenzniveau für alle Intervalle
Geben Sie das Konfidenzniveau für alle Konfidenzintervalle in der Ausgabe ein.
In der Regel ist ein Konfidenzniveau von 95 % gut geeignet. Ein 95%-Konfidenzniveau gibt an, dass bei einer Entnahme von 100 Zufallsstichproben aus der Grundgesamtheit für einen relevanten Parameter die Konfidenzintervalle für ungefähr 95 der Stichproben den tatsächlichen Wert des unbekannten Parameters enthalten. Für einen bestimmten Datensatz erzeugt ein niedrigeres Konfidenzniveau ein schmaleres Intervall, während mit einem höheren Konfidenzniveau ein breiteres Intervall erzielt wird.
Hinweis
Um die Konfidenzintervalle anzuzeigen, öffnen Sie das Unterdialogfeld Ergebnisse, und wählen Sie im Feld Darstellung der Ergebnisse die Option Erweiterte Tabellen aus.
Typ des Konfidenzintervalls
Sie können ein beidseitiges Intervall oder eine einseitige Grenze auswählen. Bei demselben Konfidenzniveau liegt eine Grenze näher an der Punktschätzung als das Intervall. Die Obergrenze liefert keinen wahrscheinlichen unteren Wert. Die Untergrenze liefert keinen wahrscheinlichen oberen Wert.
- Beidseitig
-
- Verwenden Sie ein beidseitiges Konfidenzintervall, um sowohl eine wahrscheinliche Untergrenze als auch eine wahrscheinliche Obergrenze für den Parameter von Interesse zu schätzen.
- Untergrenze
-
- Verwenden Sie eine untere Konfidenzgrenze, um eine wahrscheinliche Untergrenze für den Parameter von Interesse zu schätzen.
- Obergrenze
-
- Verwenden Sie eine obere Konfidenzgrenze, um eine wahrscheinliche Obergrenze für den Parameter von Interesse zu schätzen.
Mittelwerte
Sie können festlegen, dass die angepassten Mittelwerte für die Haupteffekte, für die Zwei-Faktor-Wechselwirkungen oder für alle Terme im Modell in der Ausgabe angezeigt werden. Sie können außerdem festlegen, dass die Mittelwerte für eine Teilmenge dieser Terme oder überhaupt keine Terme angezeigt werden.
Wenn Sie Angegebene Terme auswählen, verwenden Sie die Schaltfläche „I = Mittelwerte für Term berechnen für Term berechnen“, um die Terme zu identifizieren. Wählen Sie einen Term in der Liste aus, und klicken Sie anschließend auf die Schaltfläche. Ein I gibt an, dass der Mittelwert des Terms angezeigt wird. Wenn ein Term nicht angezeigt wird, der in der Liste enthalten sein sollte, müssen Sie diesen dem Modell hinzufügen.